L14 // Анализ главных компонент. Эксплораторный факторный анализ
Проклятие размености (curse of dimensionality)
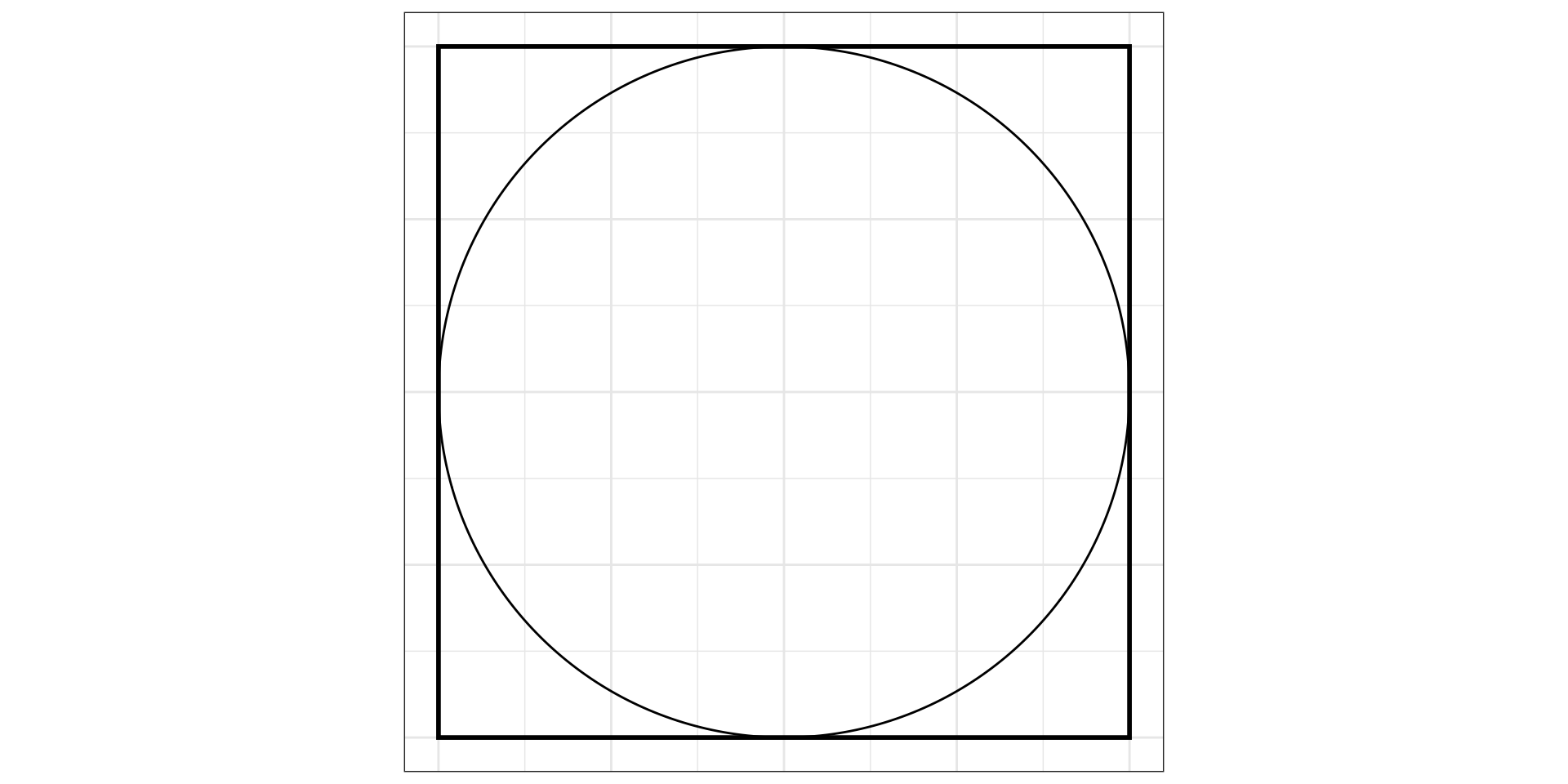
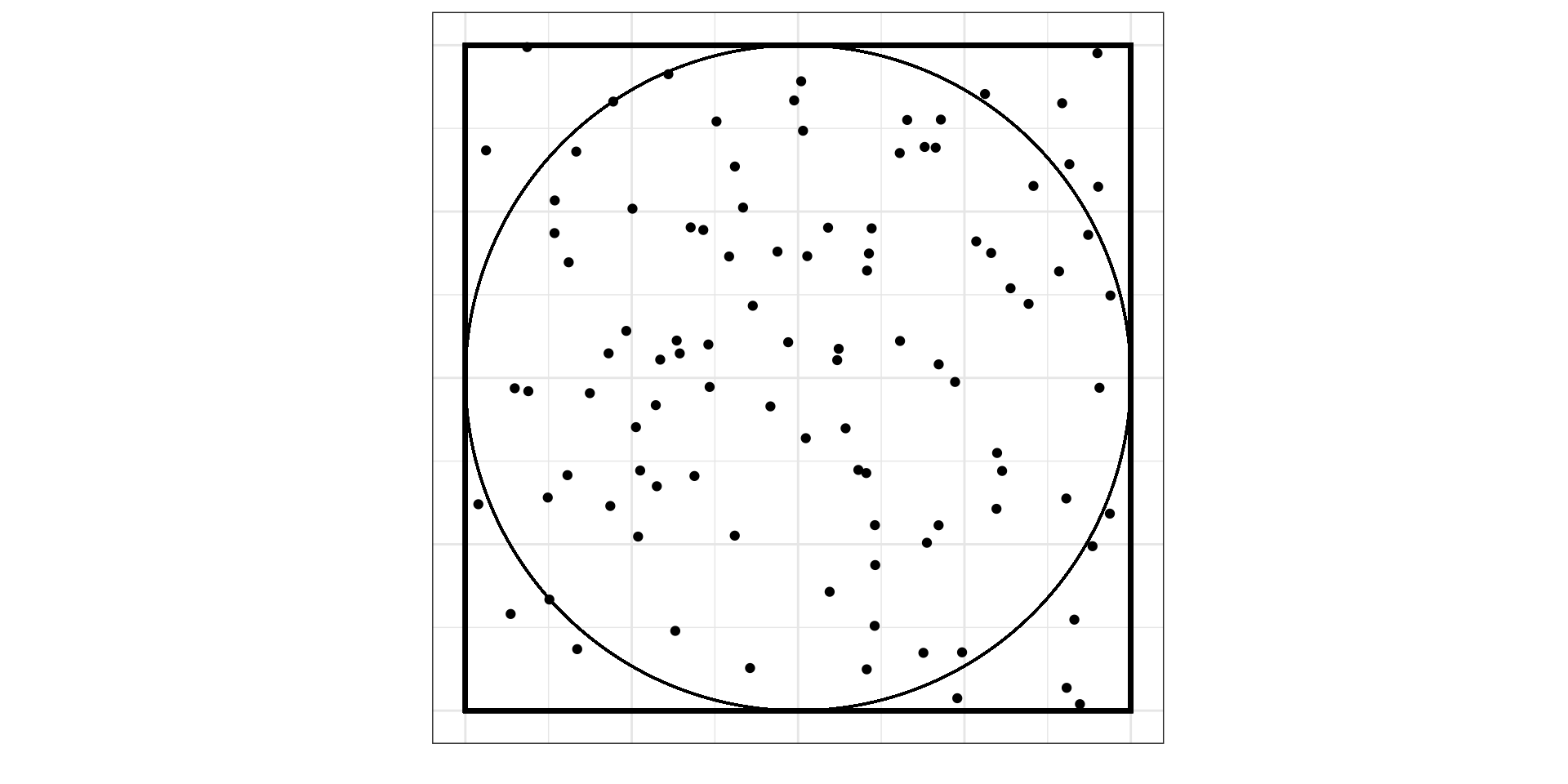
Какова вероятность, что случайно брошенная точка попадет в круг (событие \(A\))?

- для \(\mathbb{R}^2\)
\[ \mathbb{P}(A) = \lim_{N \rightarrow \infty} \frac{n}{N} = \frac{S_\text{circle}}{S_\text{square}} \]
\[ \mathbb{P}(A) = \frac{S_\text{circle}}{S_\text{square}} = \frac{\pi r^2}{a^2} = \frac{\pi \big(\frac{1}{2}a\big)^2}{a^2} = \frac{1}{4}\pi \approx 0.785 \]
- для \(\mathbb{R}^3\)
\[ \mathbb{P}(A) = \frac{V_\text{ball}}{V_\text{cube}} = \frac{\frac{4}{3}\pi r^3}{a^3} = \frac{\frac{4}{3}\pi \big(\frac{1}{2}a\big)^3}{a^3} \approx 0.523 \]
- для \(\mathbb{R}^k\)
\[ \begin{split} k = 2n &, V = \frac{\pi^2}{n!}r^{2n} \\ k = 2n+1 &, V = \frac{2 \cdot (2\pi)^n}{(2n+1)!!} r^{2n+1} \end{split} \]
- \(k \to \infty : V \to 0\).
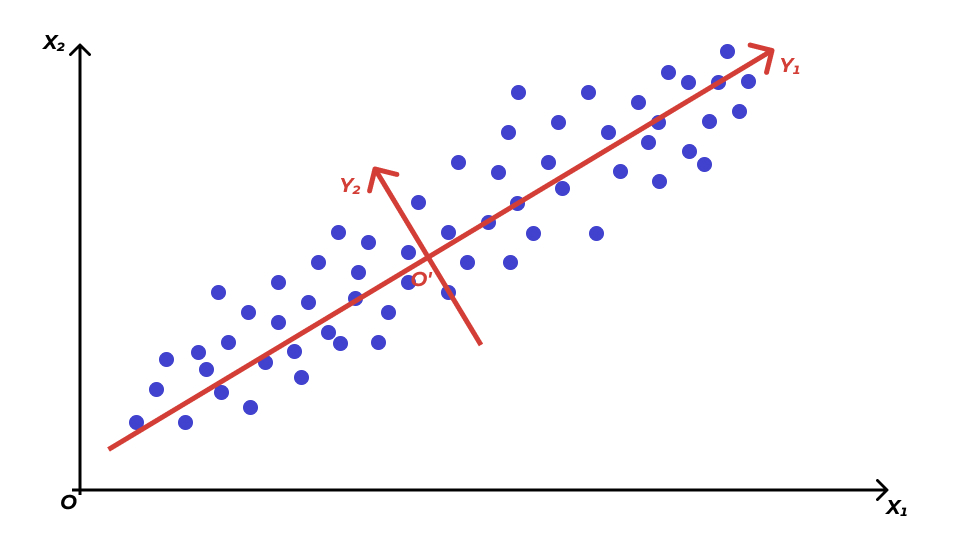
Поиск главных компонент геометрически
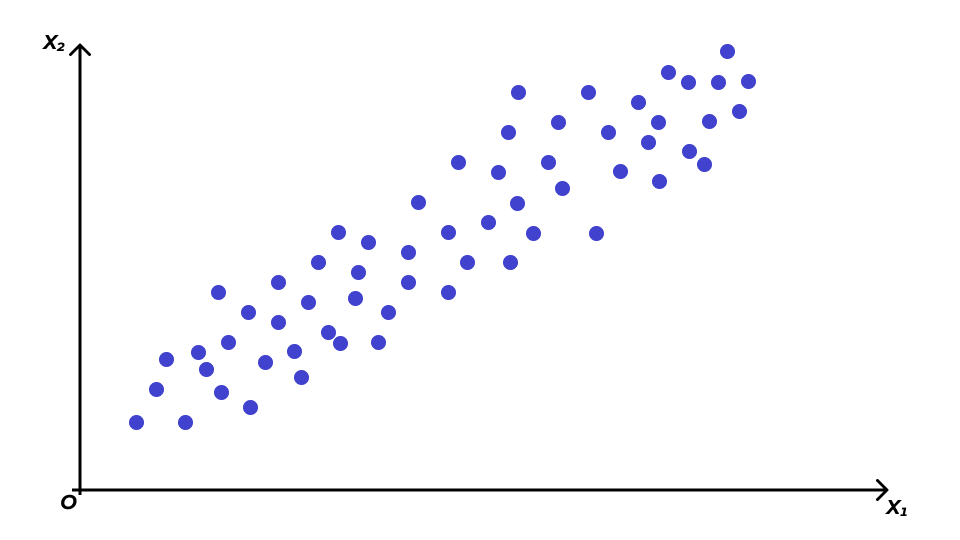
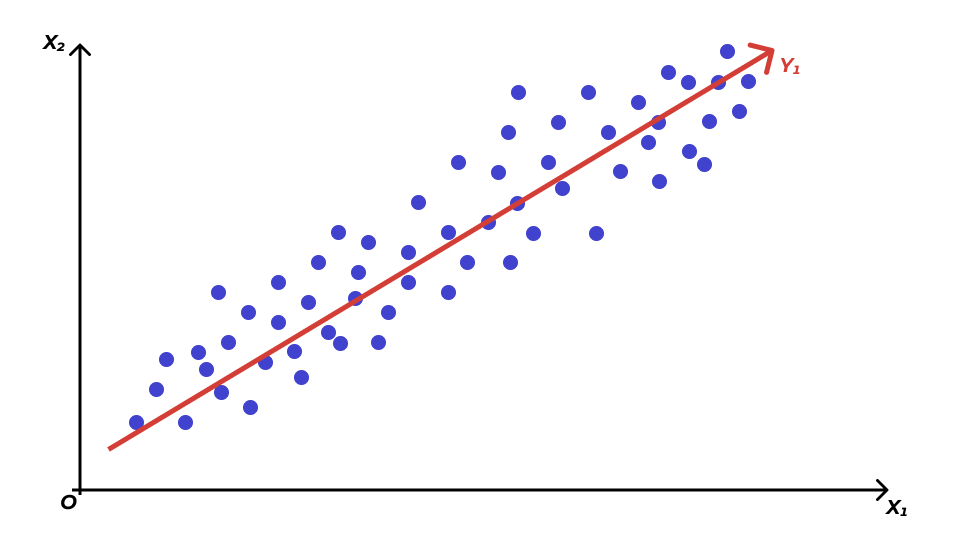
Сокращение размерности признакового пространства

Информативность компонент
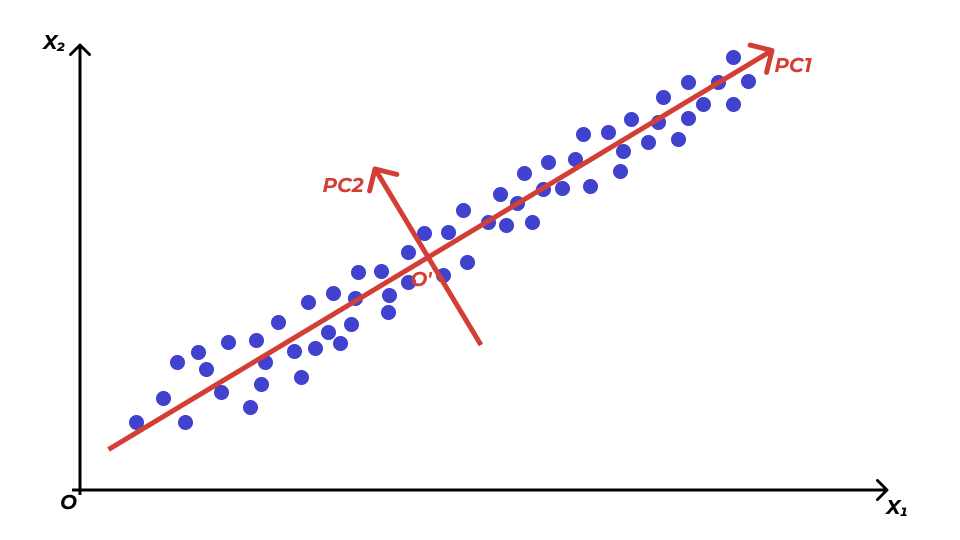
- все наблюдения расположены более-менее вокруг одной прямой — первой главной компоненты \(\text{PC1}\)
- изменчивостью по второй главной компоненте \(\text{PC2}\) можно пренебречь
L14 // Анализ главных компонент. Эксплораторный факторный анализ
![]()