L2 // Предобработка данных. Дата и время. Визуализация данных
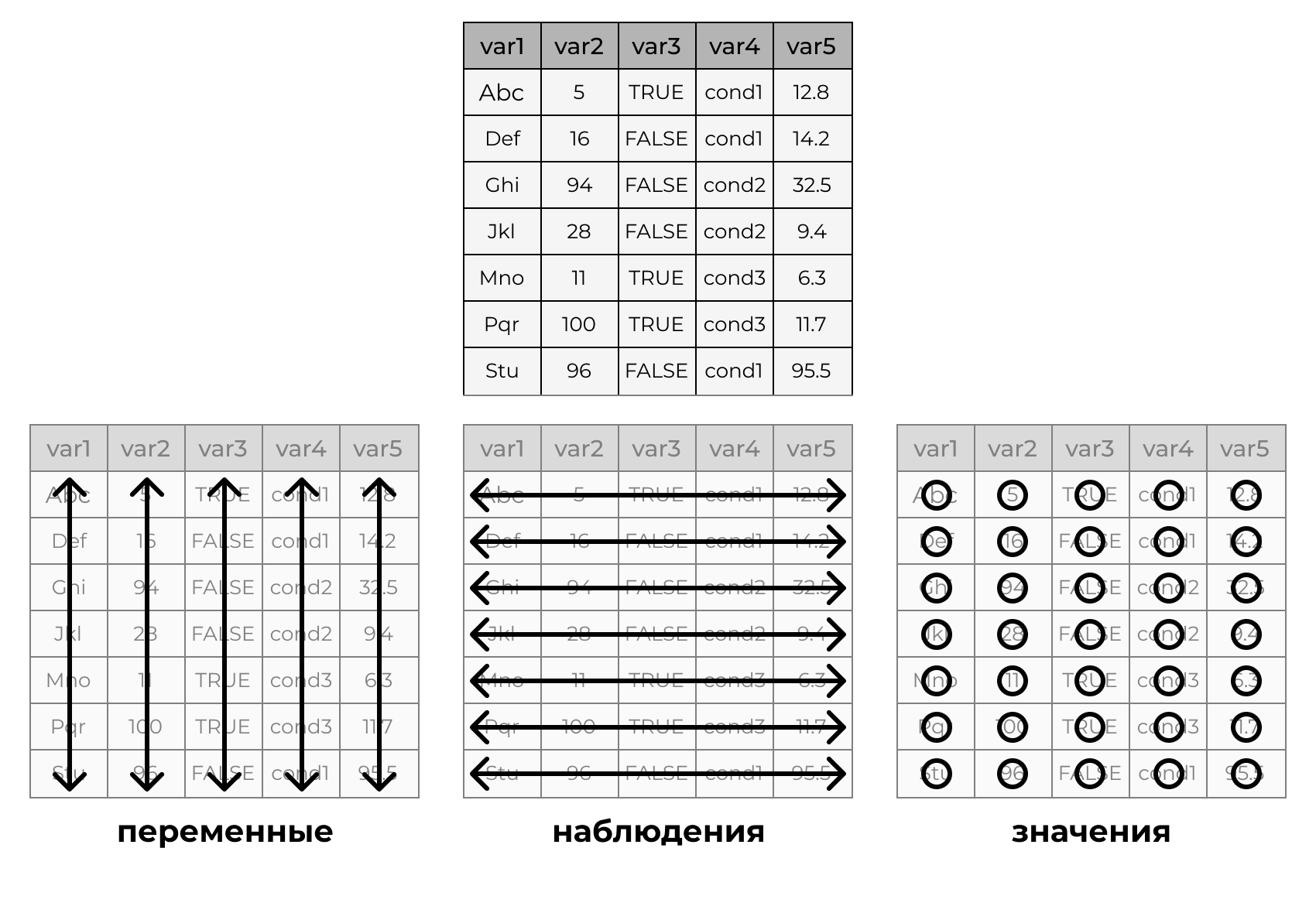
Концепция Tidy Data
- В каждом столбце содержится одна переменная
- В каждой строке содержится одно наблюдение
- В каждой ячейке содержится одно значение
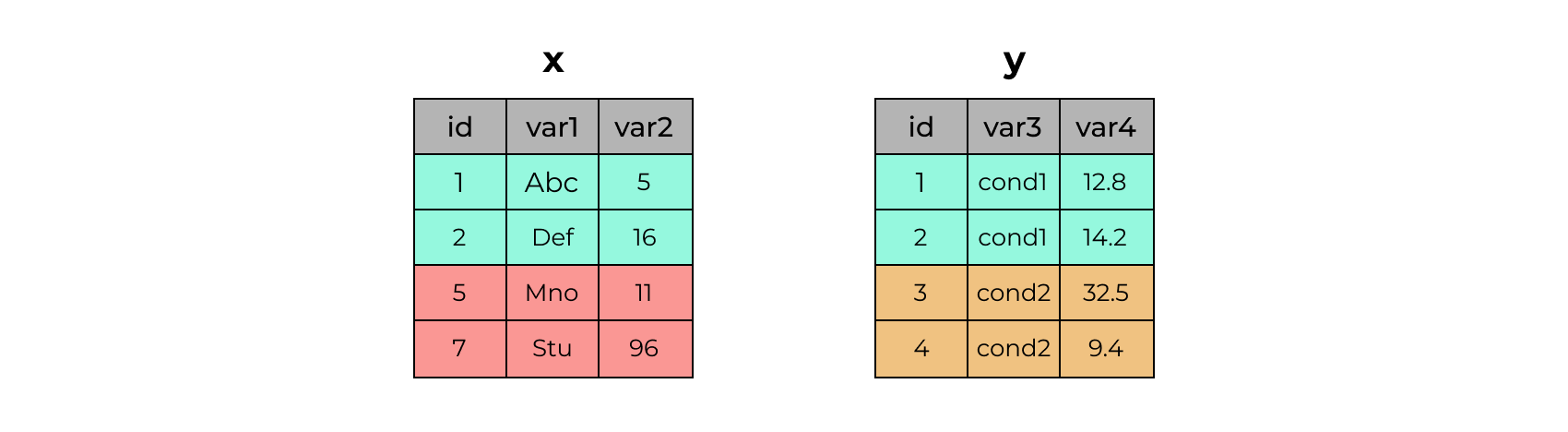
Объединение датасетов. Ключ
inner_join()
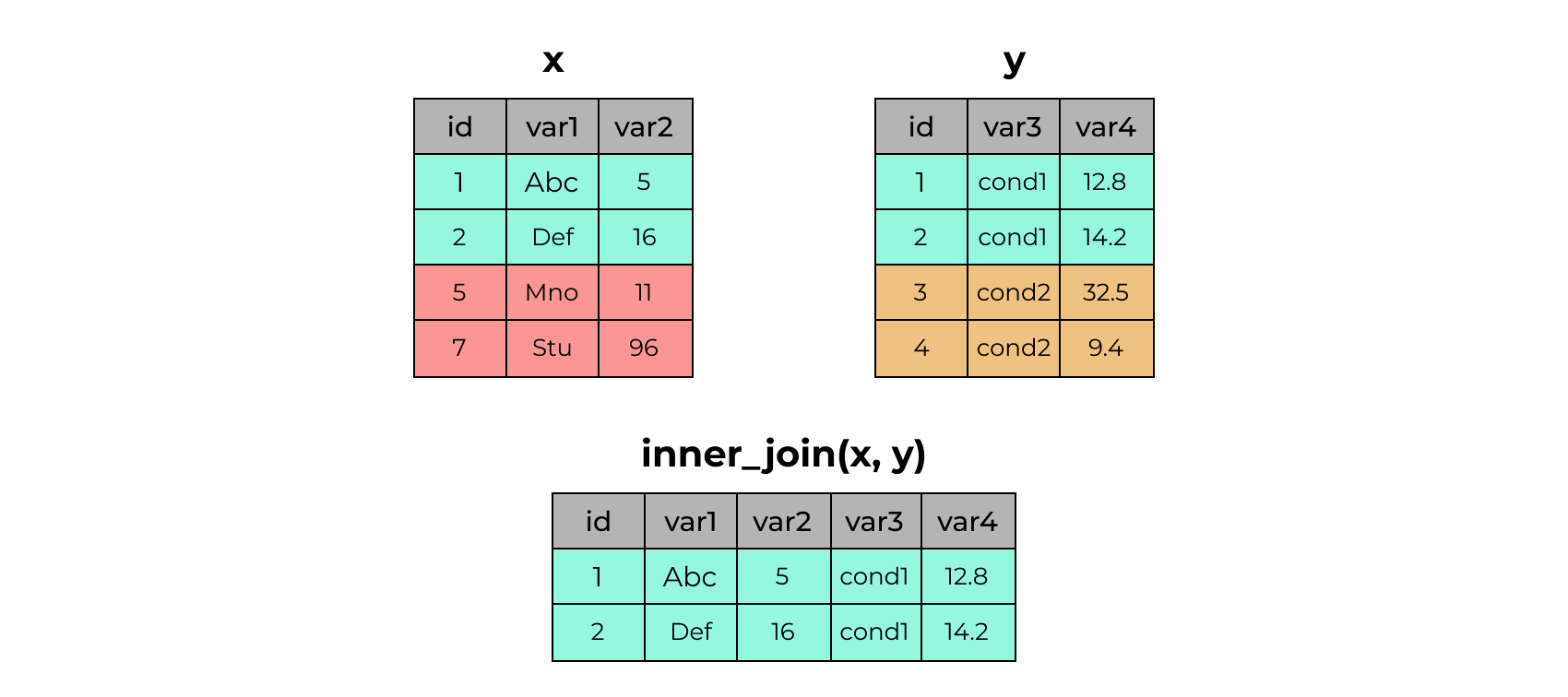
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 2 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 2 Def 16 cond1 14.2left_join()
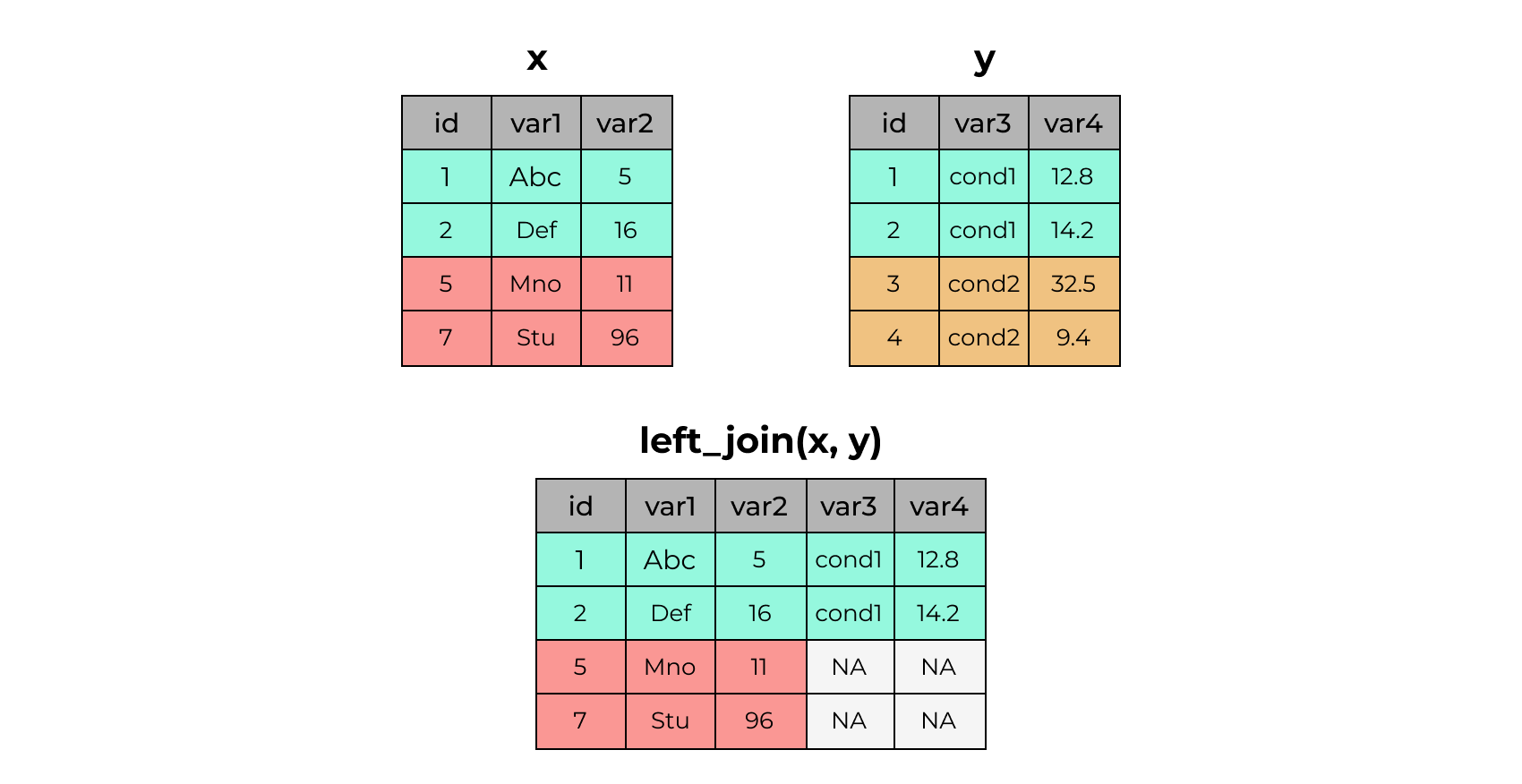
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 4 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 2 Def 16 cond1 14.2
3 5 Mno 11 <NA> NA
4 7 Stu 96 <NA> NA right_join()
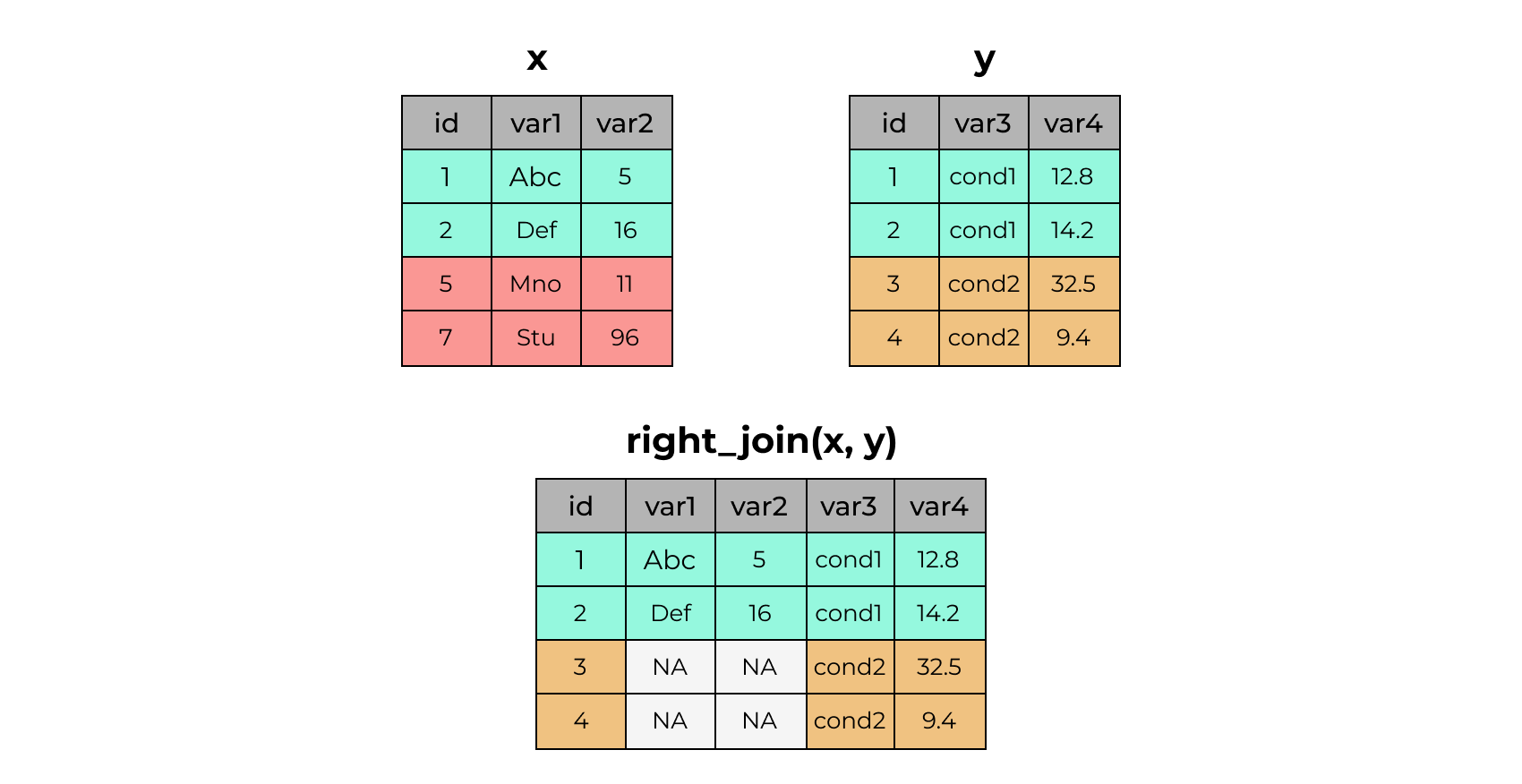
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 4 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 2 Def 16 cond1 14.2
3 3 <NA> NA cond2 32.5
4 4 <NA> NA cond2 9.4full_join()
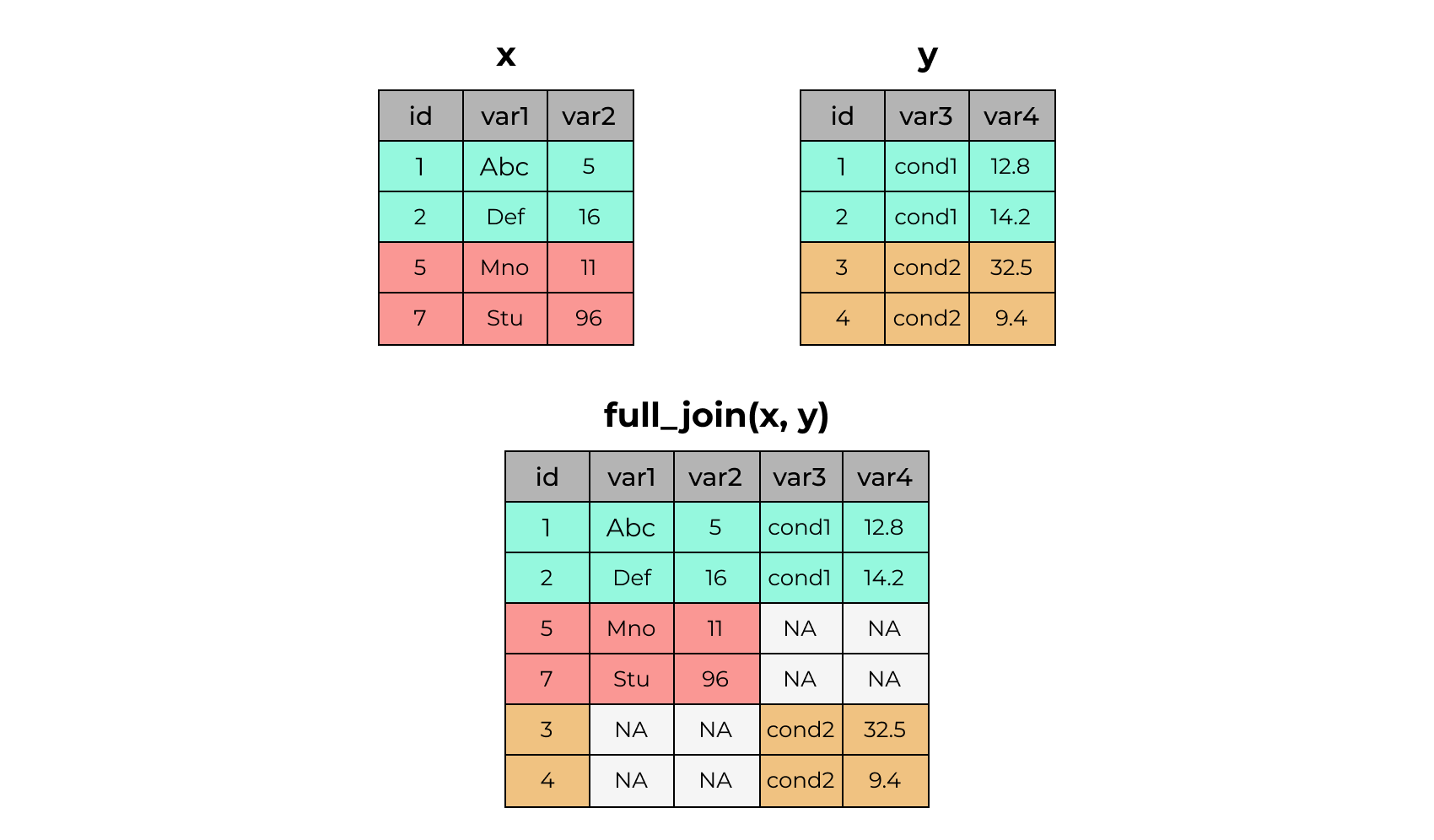
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 6 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 2 Def 16 cond1 14.2
3 5 Mno 11 <NA> NA
4 7 Stu 96 <NA> NA
5 3 <NA> NA cond2 32.5
6 4 <NA> NA cond2 9.4semi_join()
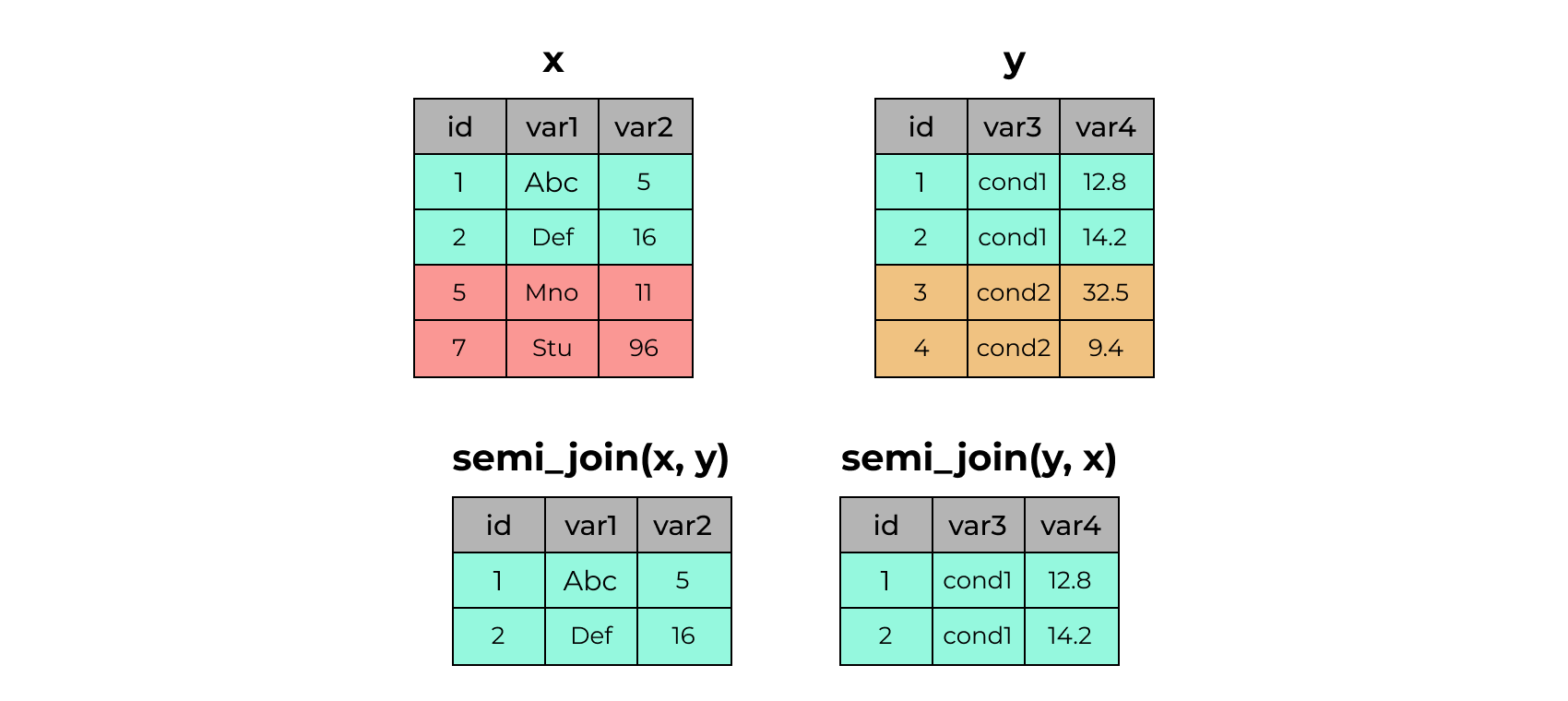
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 2 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16# A tibble: 2 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2anti_join()
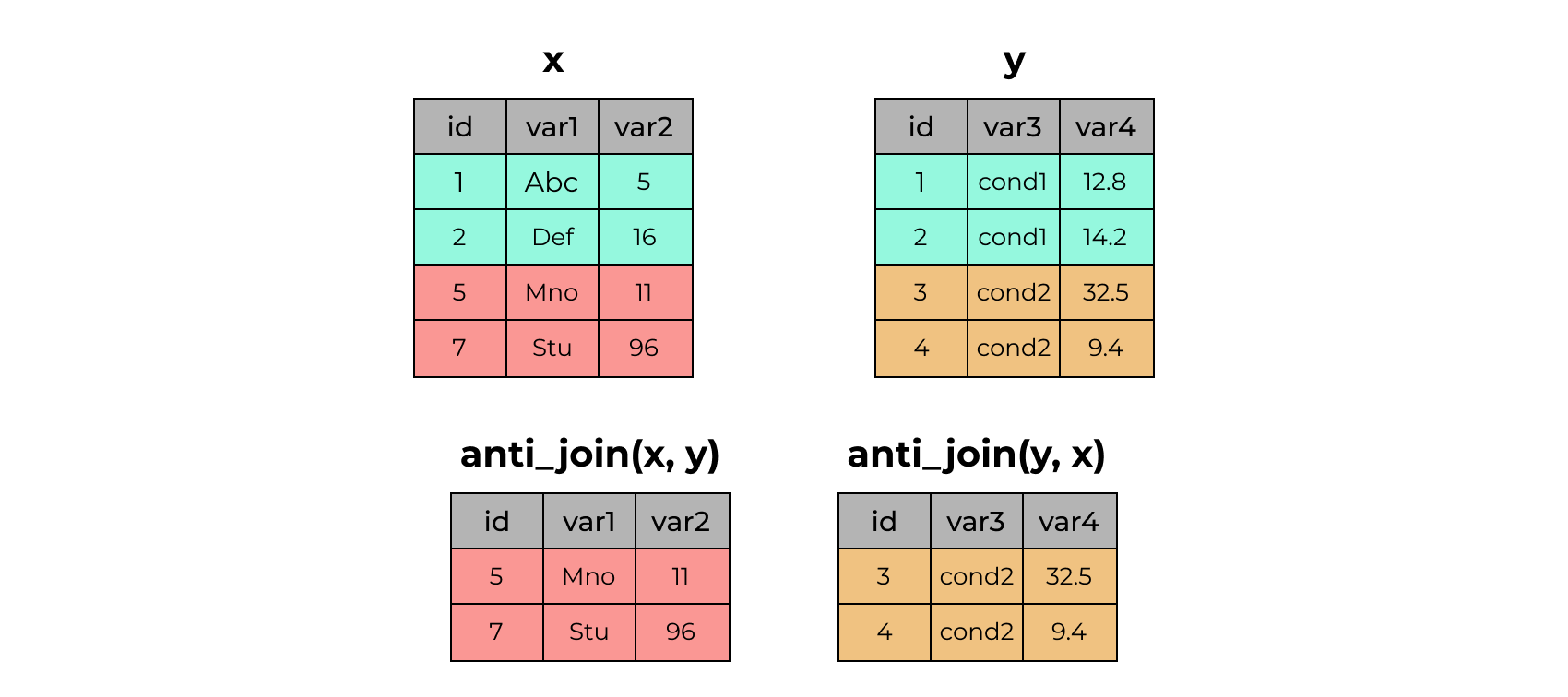
# A tibble: 4 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 2 Def 16
3 5 Mno 11
4 7 Stu 96# A tibble: 4 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 3 cond2 32.5
4 4 cond2 9.4# A tibble: 2 × 3
id var1 var2
<dbl> <chr> <dbl>
1 5 Mno 11
2 7 Stu 96# A tibble: 2 × 3
id var3 var4
<dbl> <chr> <dbl>
1 3 cond2 32.5
2 4 cond2 9.4Дублирование ключа
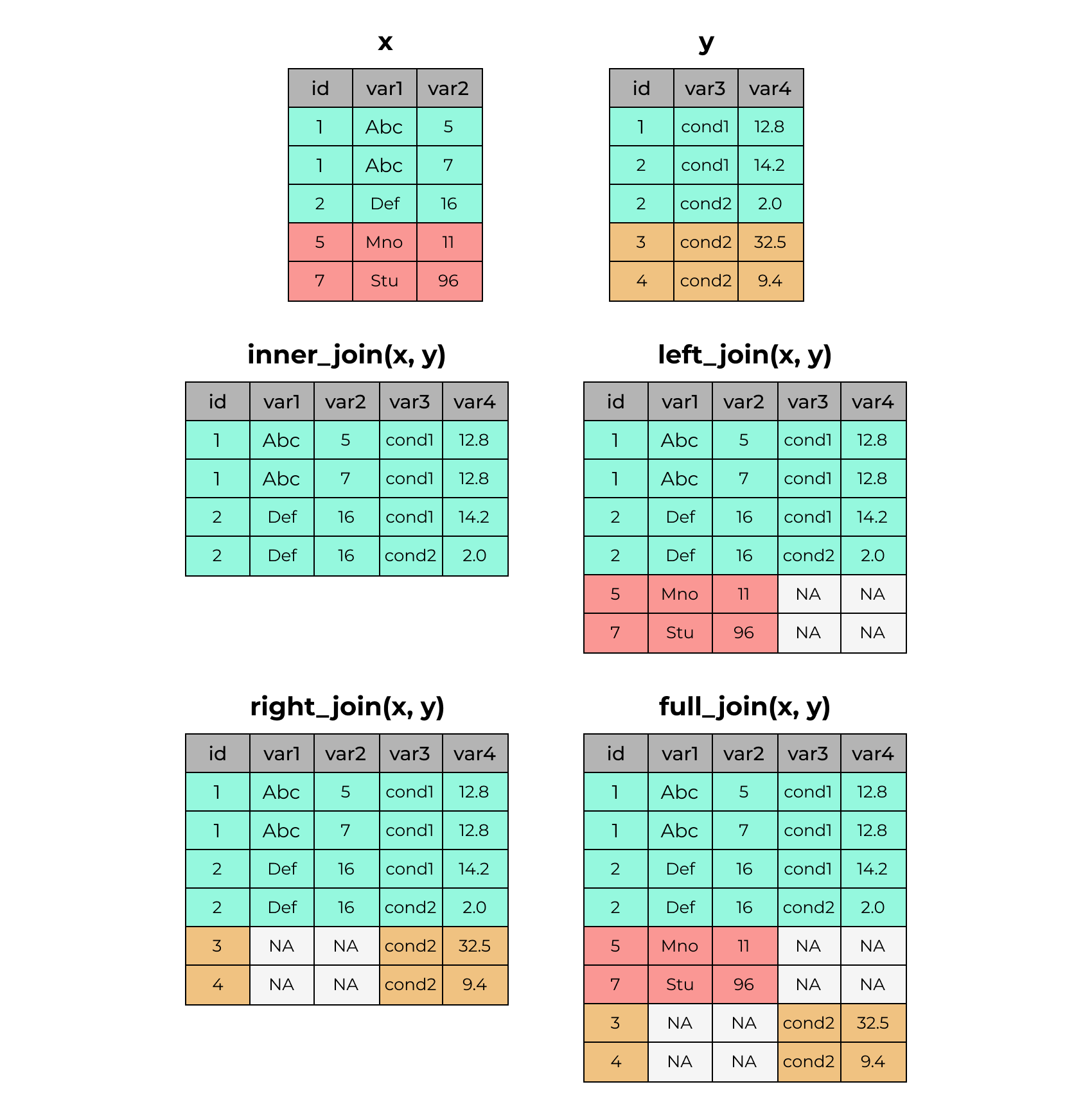
# A tibble: 5 × 3
id var1 var2
<dbl> <chr> <dbl>
1 1 Abc 5
2 1 Abc 7
3 2 Def 16
4 5 Mno 11
5 7 Stu 96# A tibble: 5 × 3
id var3 var4
<dbl> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 2 cond2 2
4 3 cond2 32.5
5 4 cond2 9.4# A tibble: 4 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 1 Abc 7 cond1 12.8
3 2 Def 16 cond1 14.2
4 2 Def 16 cond2 2 # A tibble: 6 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 1 Abc 7 cond1 12.8
3 2 Def 16 cond1 14.2
4 2 Def 16 cond2 2
5 5 Mno 11 <NA> NA
6 7 Stu 96 <NA> NA # A tibble: 6 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 1 Abc 7 cond1 12.8
3 2 Def 16 cond1 14.2
4 2 Def 16 cond2 2
5 3 <NA> NA cond2 32.5
6 4 <NA> NA cond2 9.4# A tibble: 8 × 5
id var1 var2 var3 var4
<dbl> <chr> <dbl> <chr> <dbl>
1 1 Abc 5 cond1 12.8
2 1 Abc 7 cond1 12.8
3 2 Def 16 cond1 14.2
4 2 Def 16 cond2 2
5 5 Mno 11 <NA> NA
6 7 Stu 96 <NA> NA
7 3 <NA> NA cond2 32.5
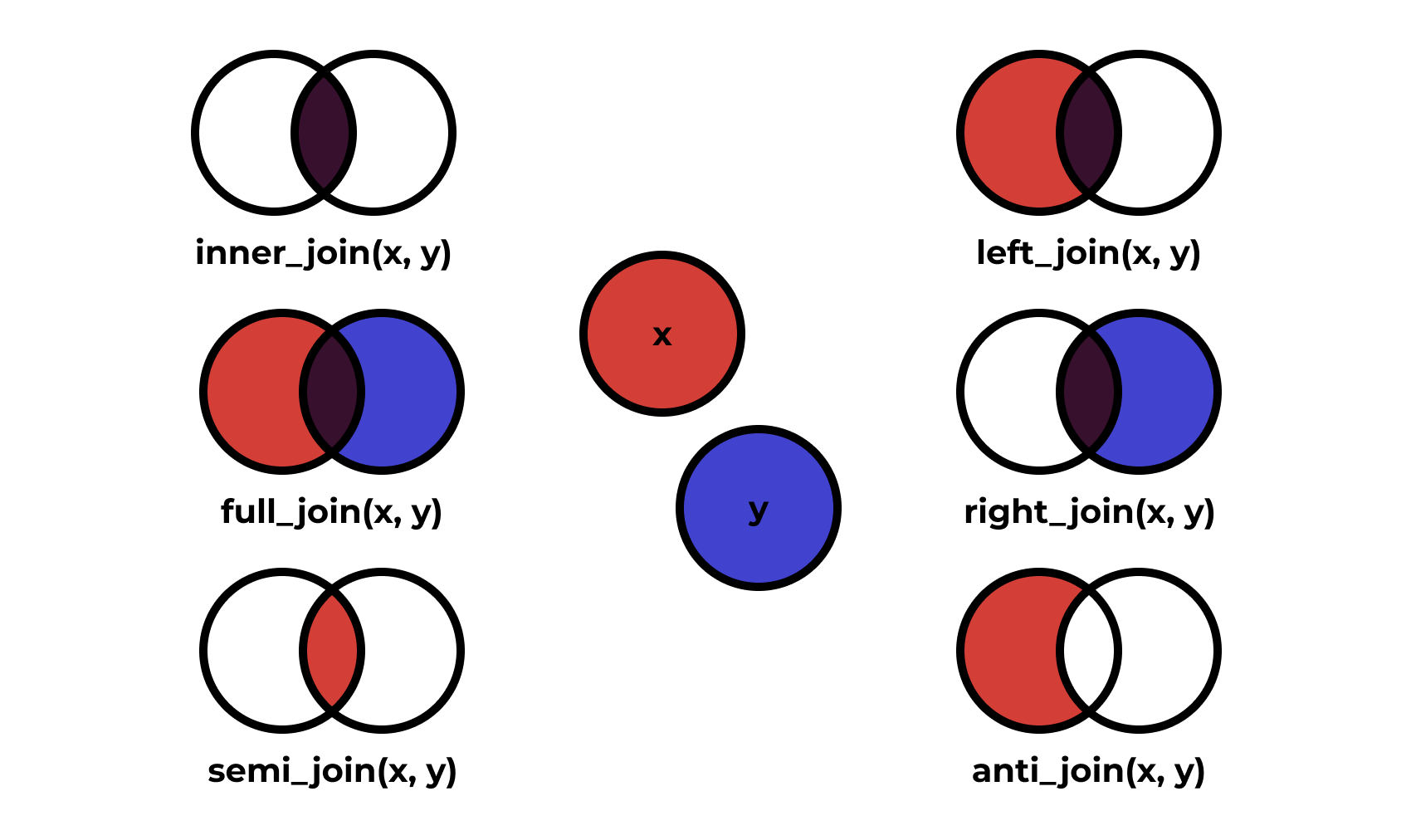
8 4 <NA> NA cond2 9.4Способы объединения по ключу на диаграммах Венна
Широкий и длинный форматы данных
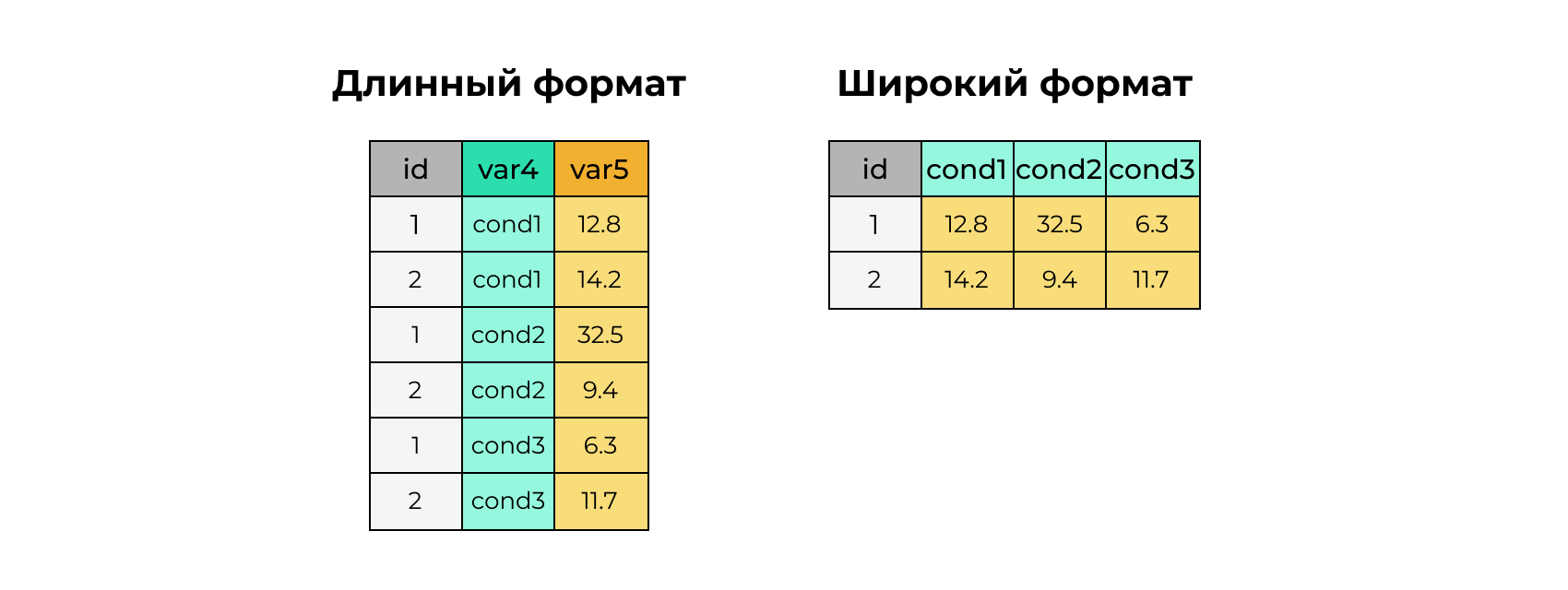
# A tibble: 6 × 3
id var1 var2
<int> <chr> <dbl>
1 1 cond1 12.8
2 2 cond1 14.2
3 1 cond2 32.5
4 2 cond2 9.4
5 1 cond3 6.3
6 2 cond3 11.7# A tibble: 2 × 4
id cond1 cond2 cond3
<int> <dbl> <dbl> <dbl>
1 1 12.8 32.5 6.3
2 2 14.2 9.4 11.7# A tibble: 6 × 3
id name value
<int> <chr> <dbl>
1 1 cond1 12.8
2 1 cond2 32.5
3 1 cond3 6.3
4 2 cond1 14.2
5 2 cond2 9.4
6 2 cond3 11.7Визуализация Квартета Анскомба
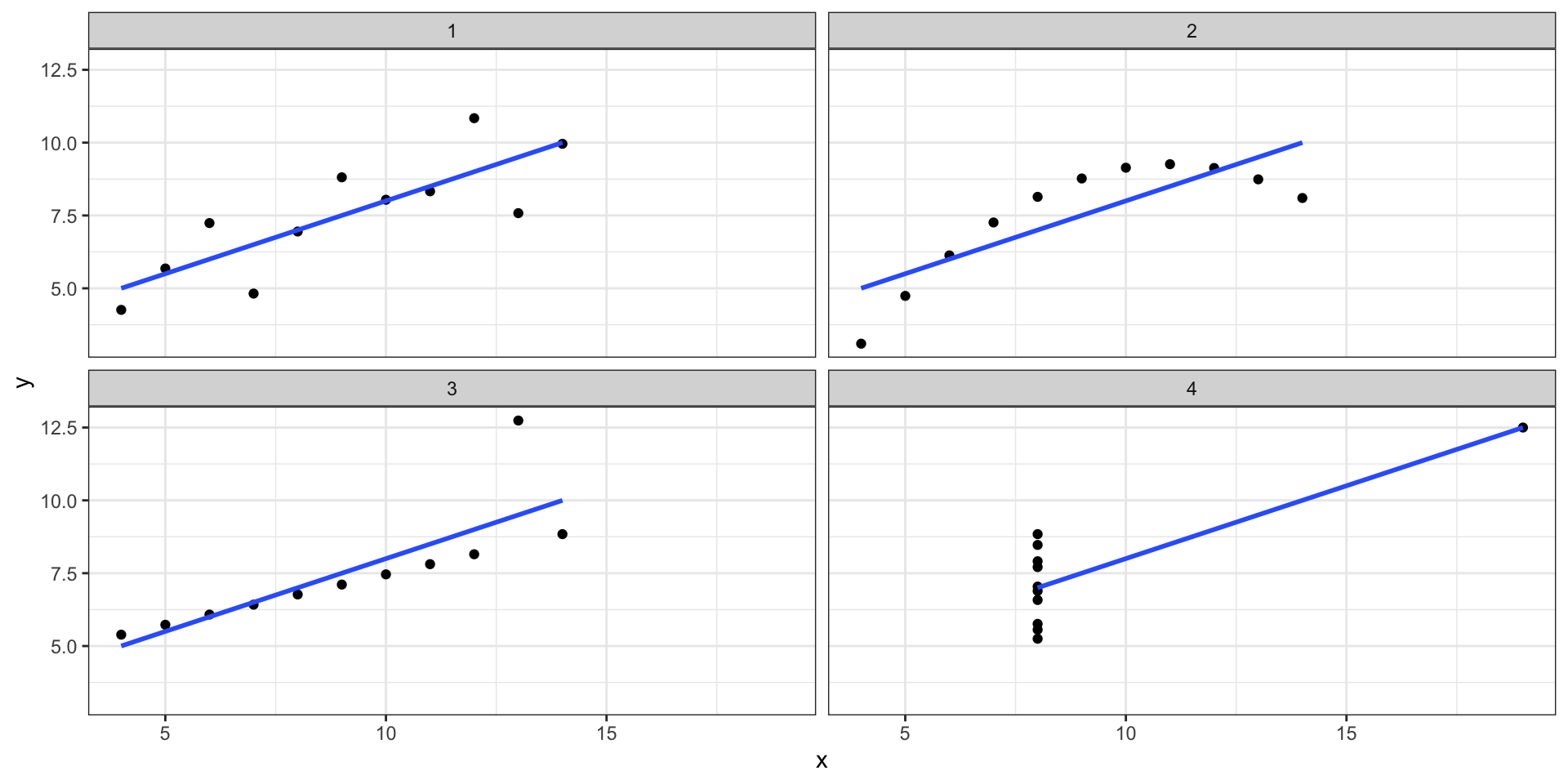
Визуализация Datasaurus
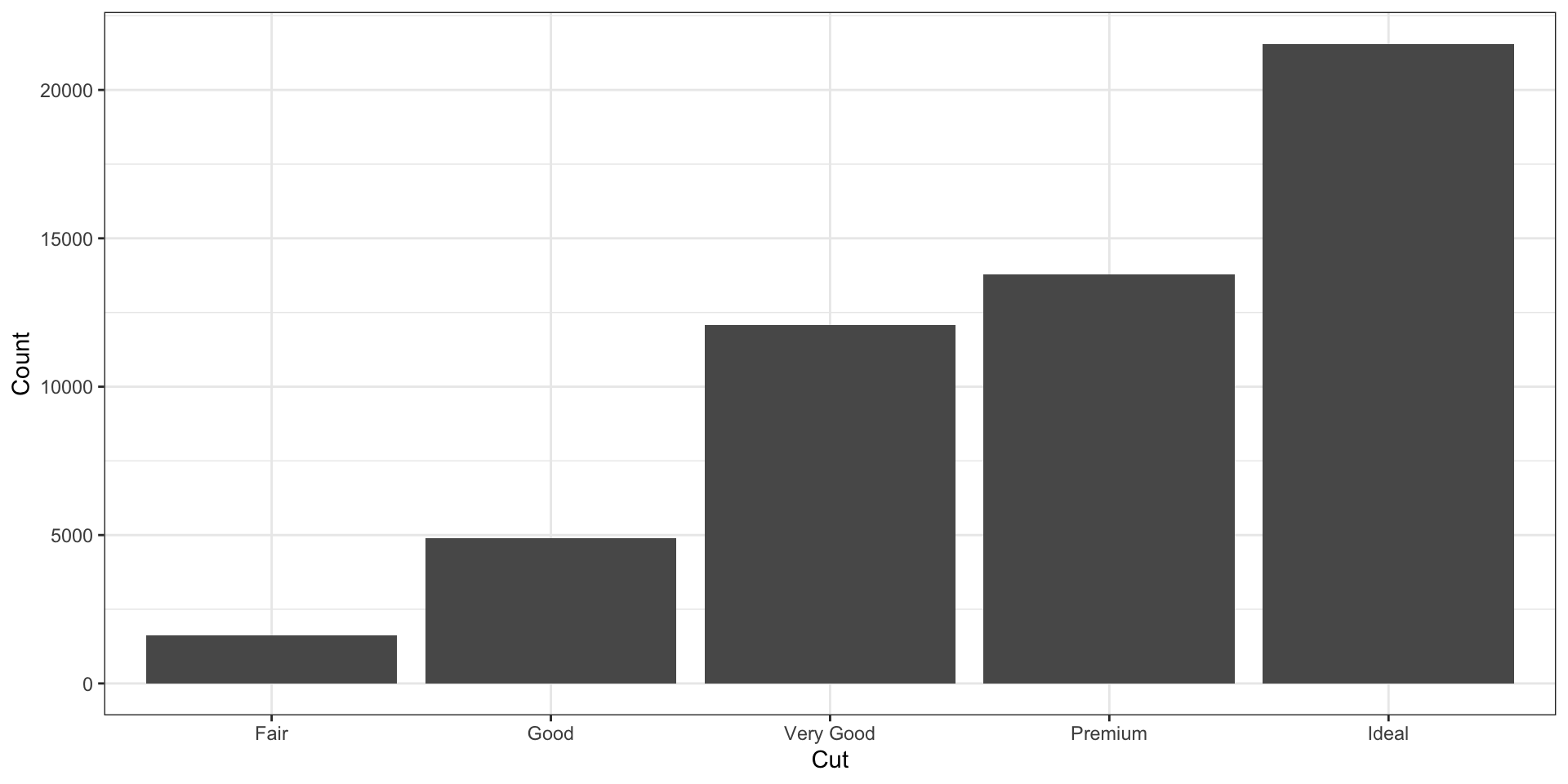
Столбчатая диаграмма (Bar plot, Bar graph)
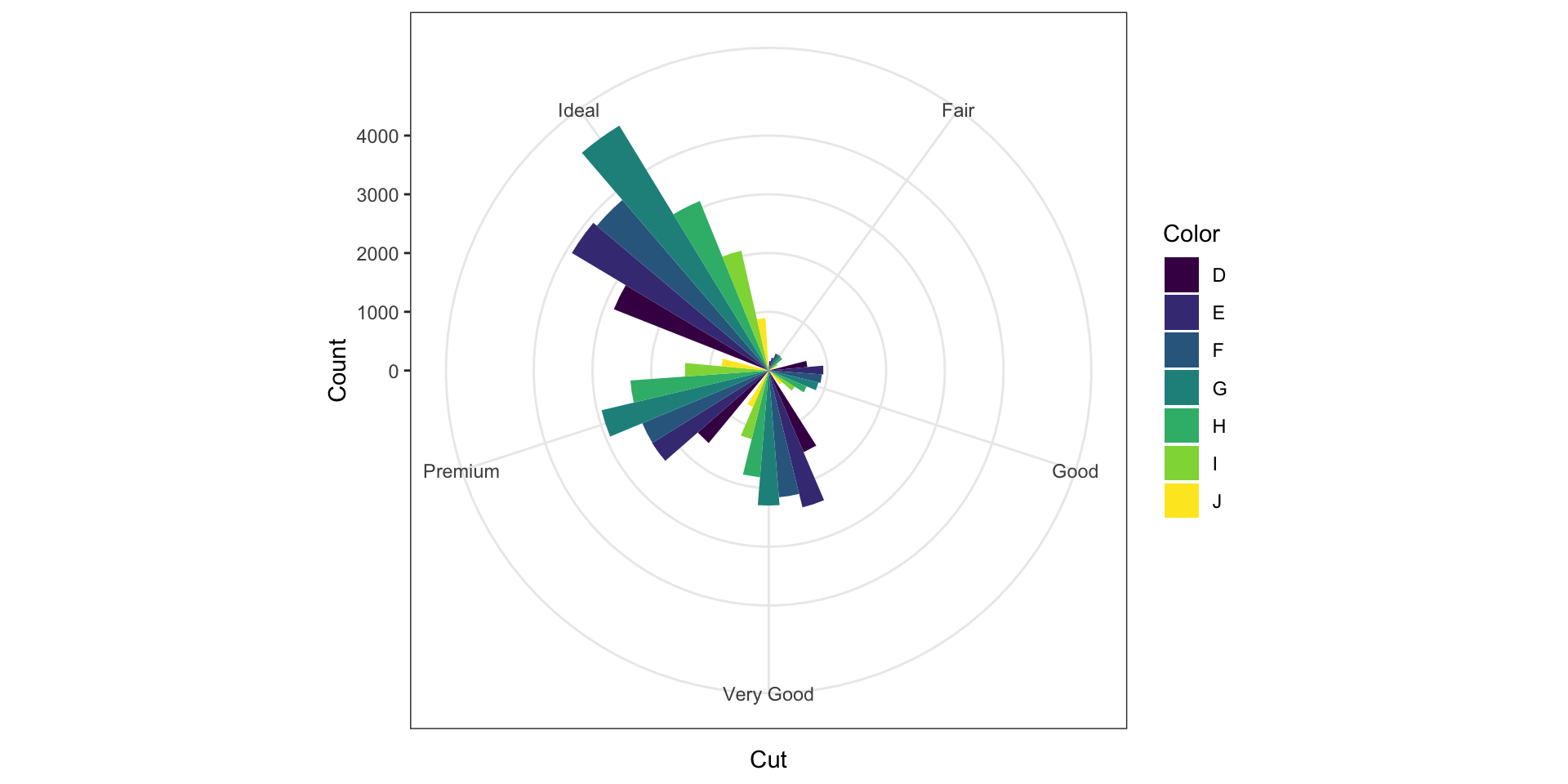
Лучевая диаграмма (Subburts)
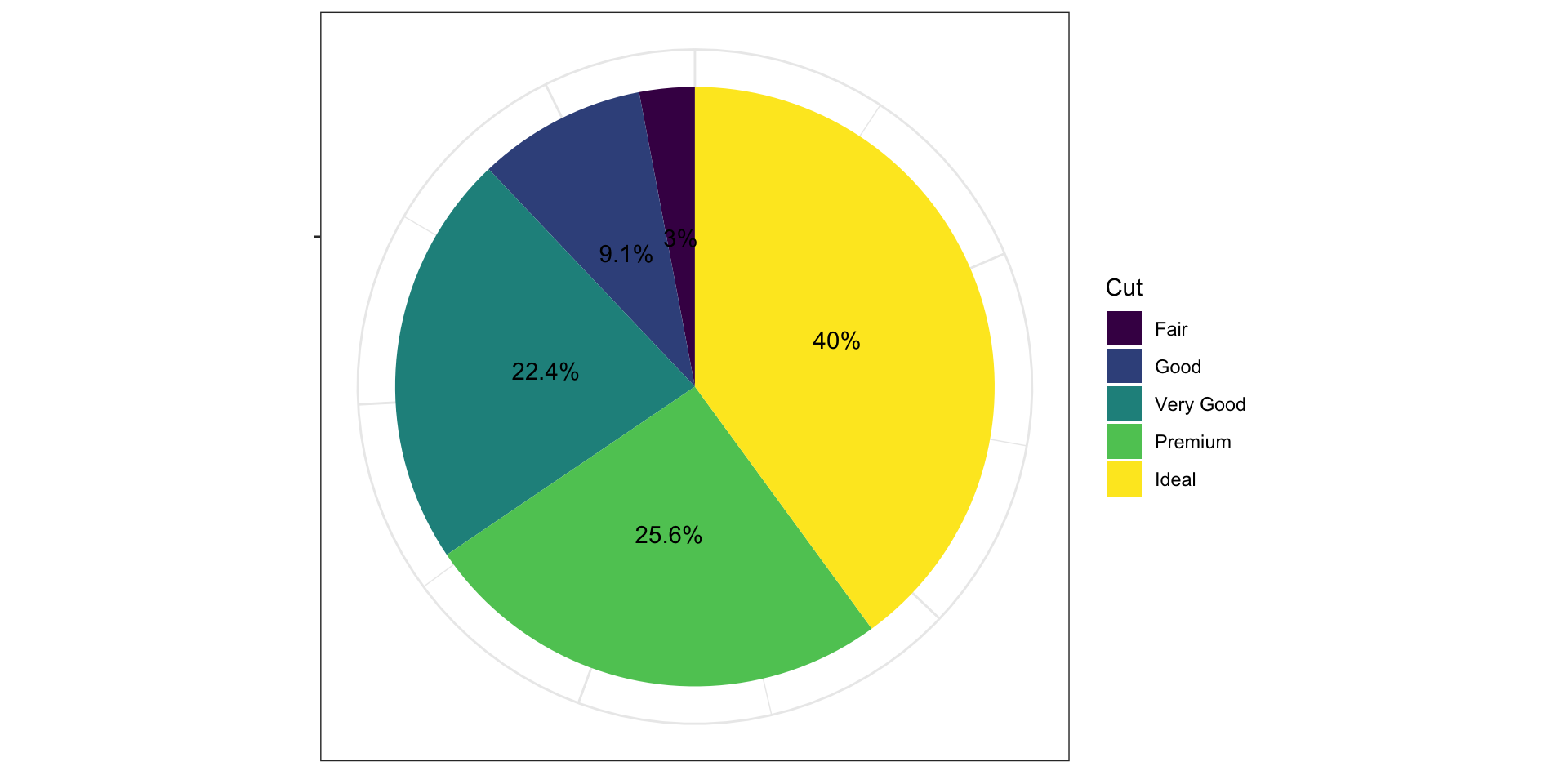
Круговая диаграмма (Pie chart)
Линейная диаграмма (Line graph, Line plot)
Гистограмма (Histogram)
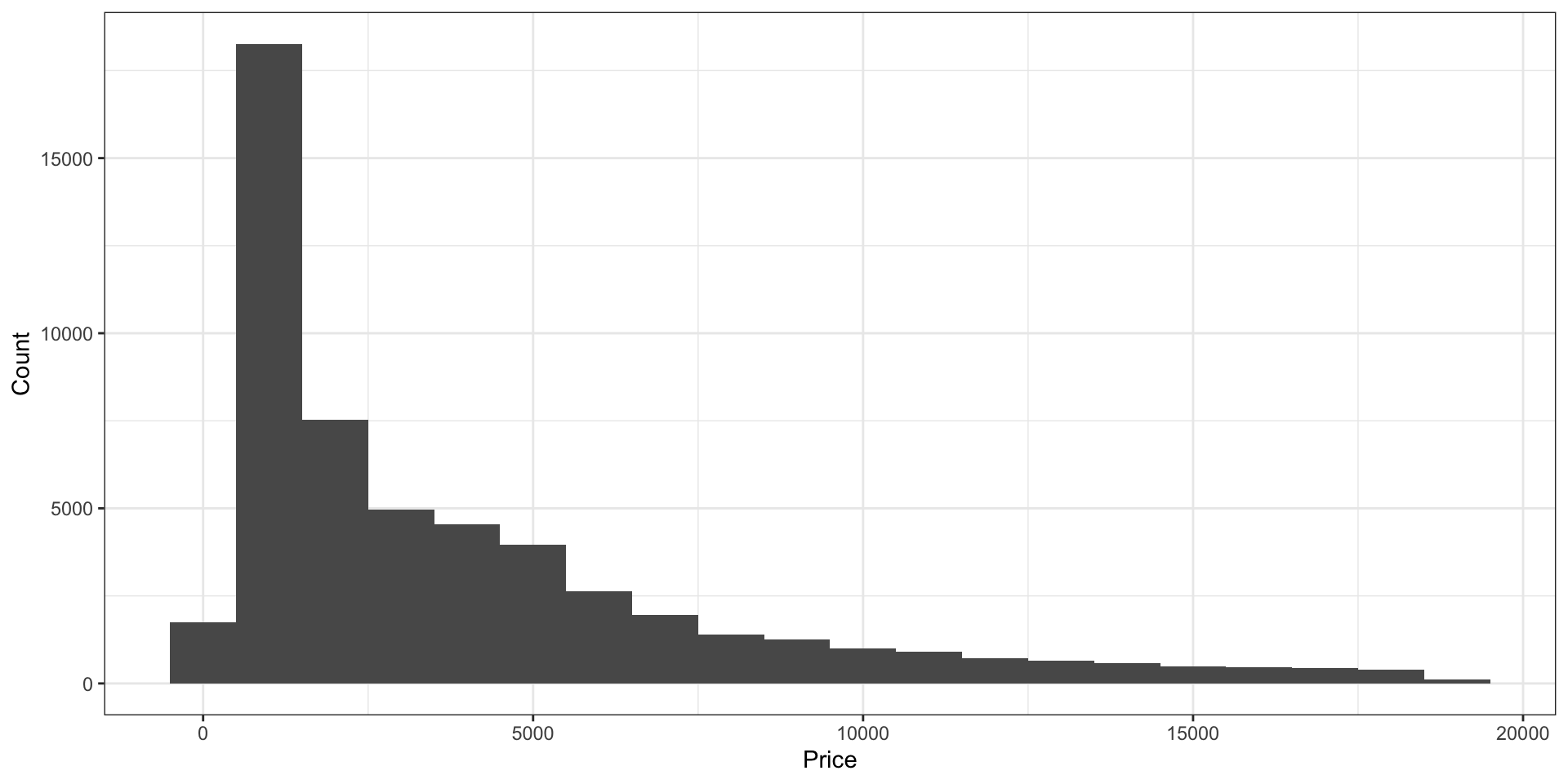
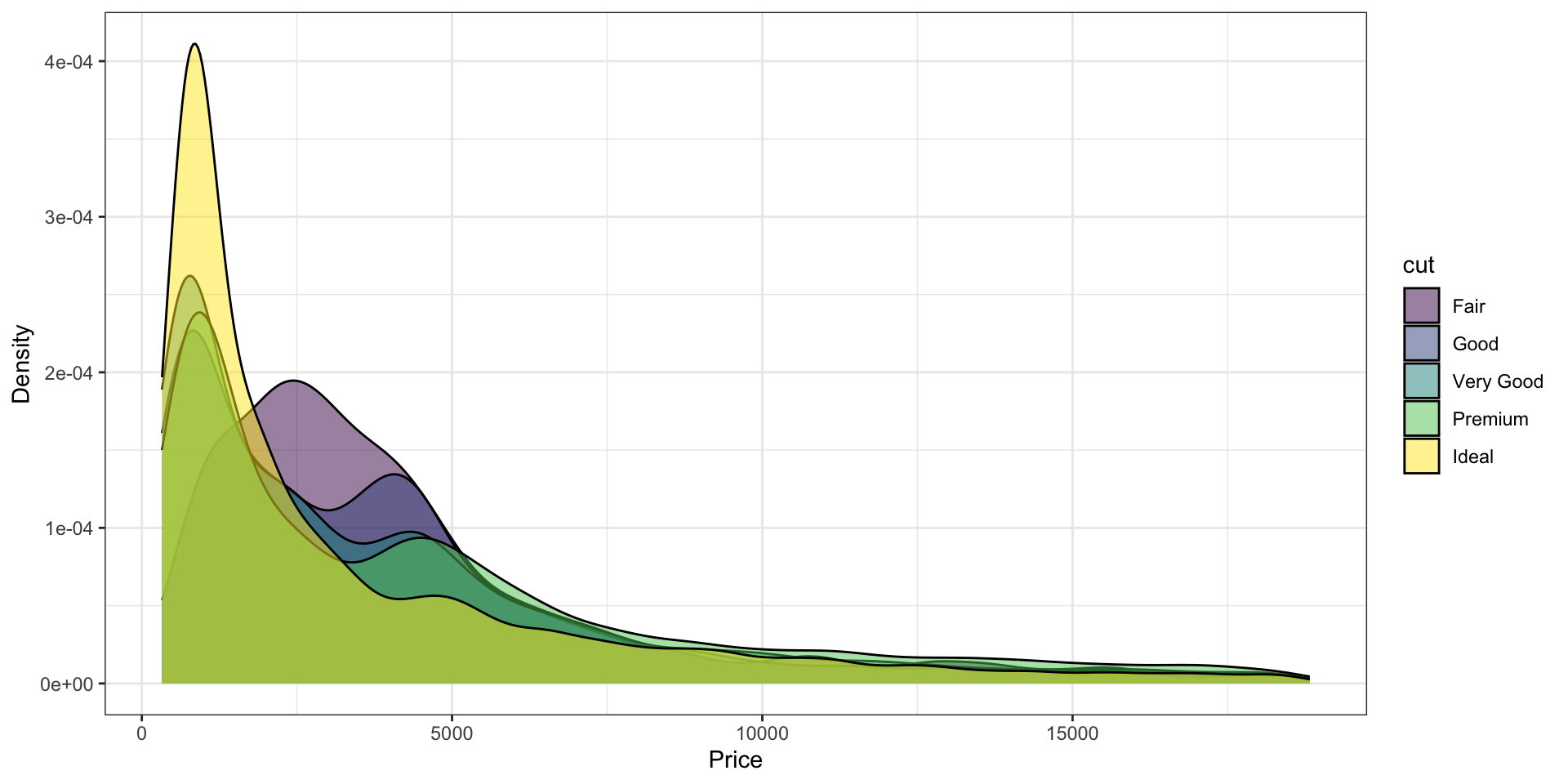
График плотности распределения (Density plot)
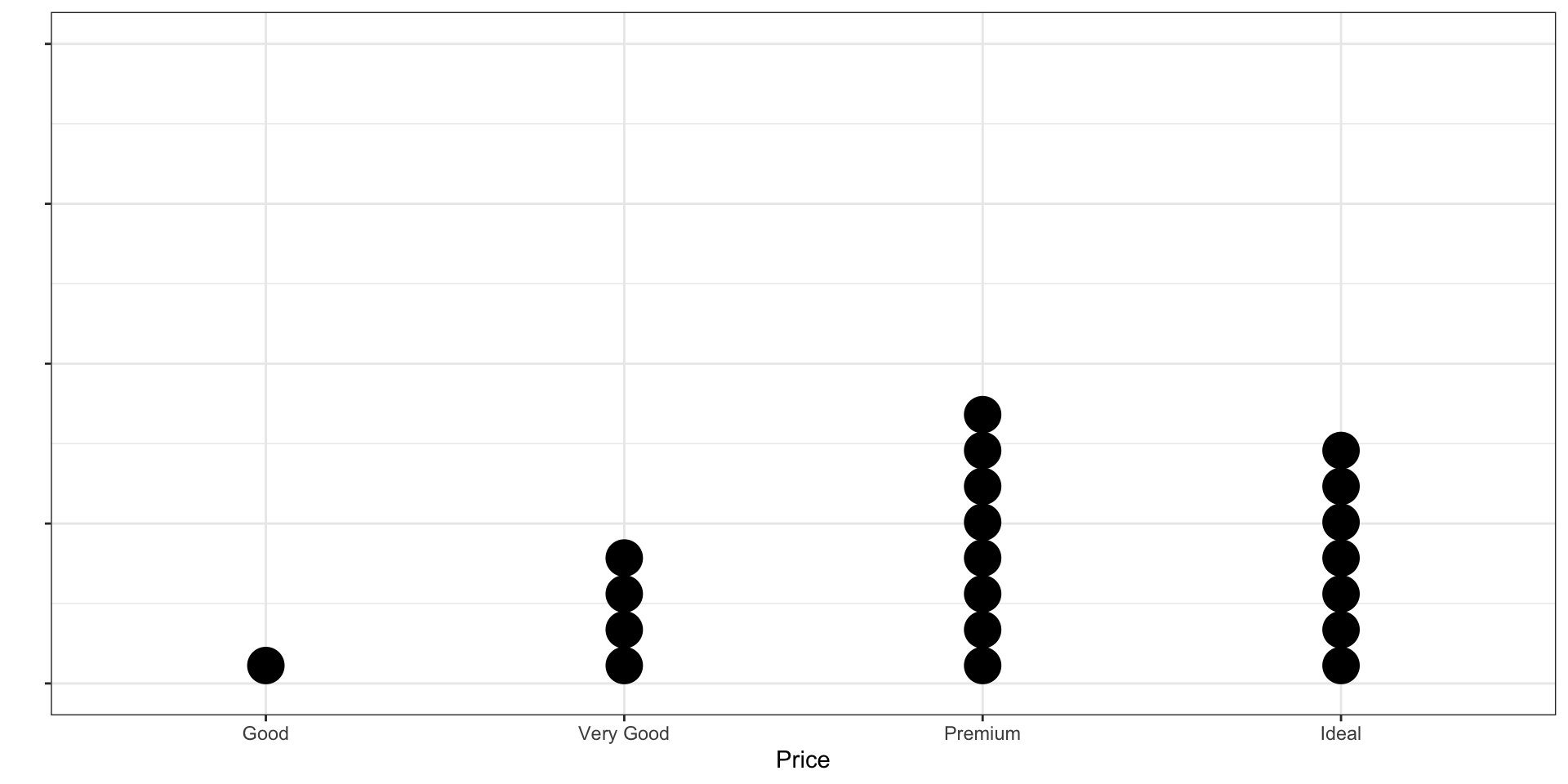
Dot plot
Ящик с усами (Boxplot)
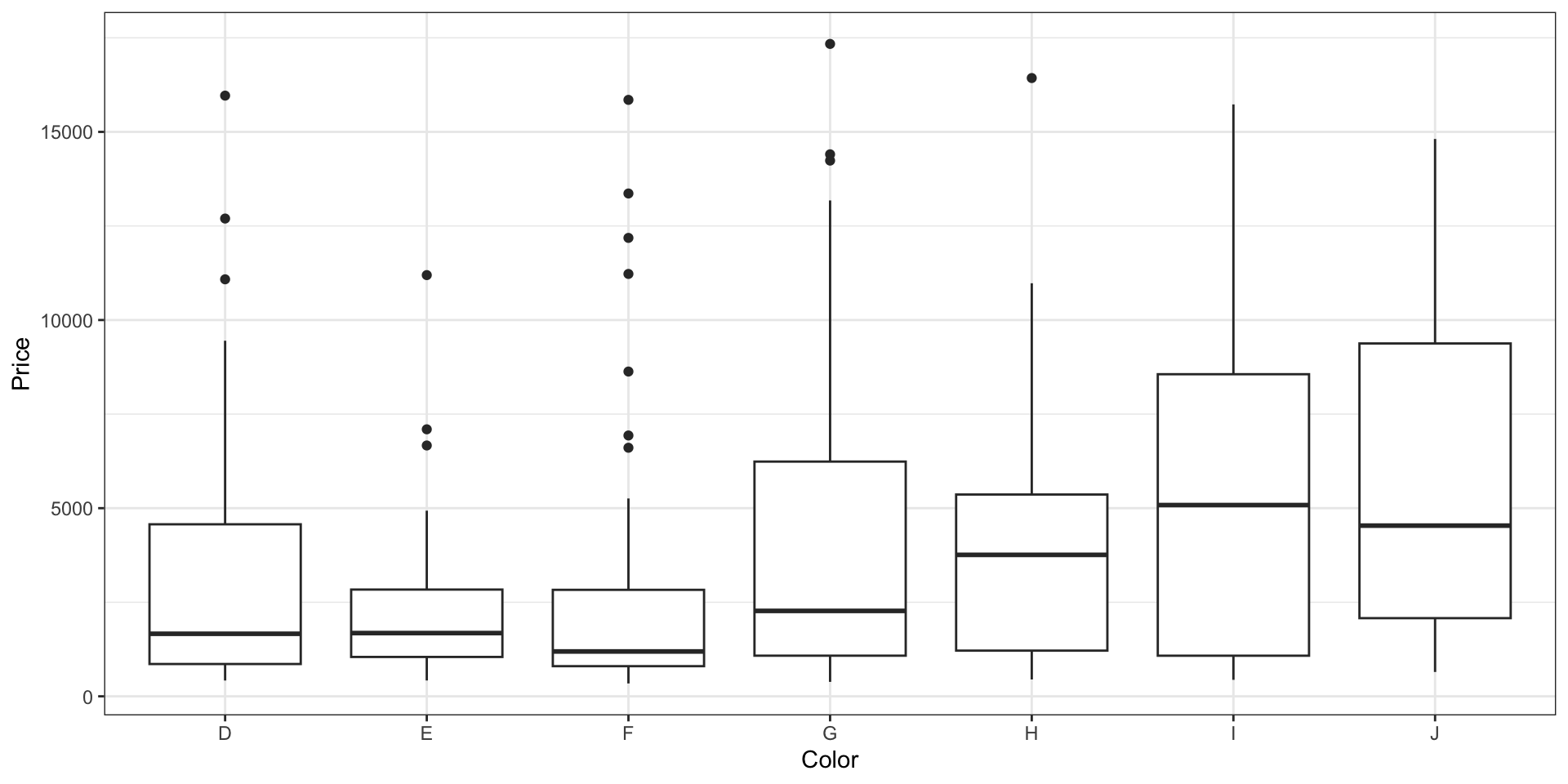
Violin plot
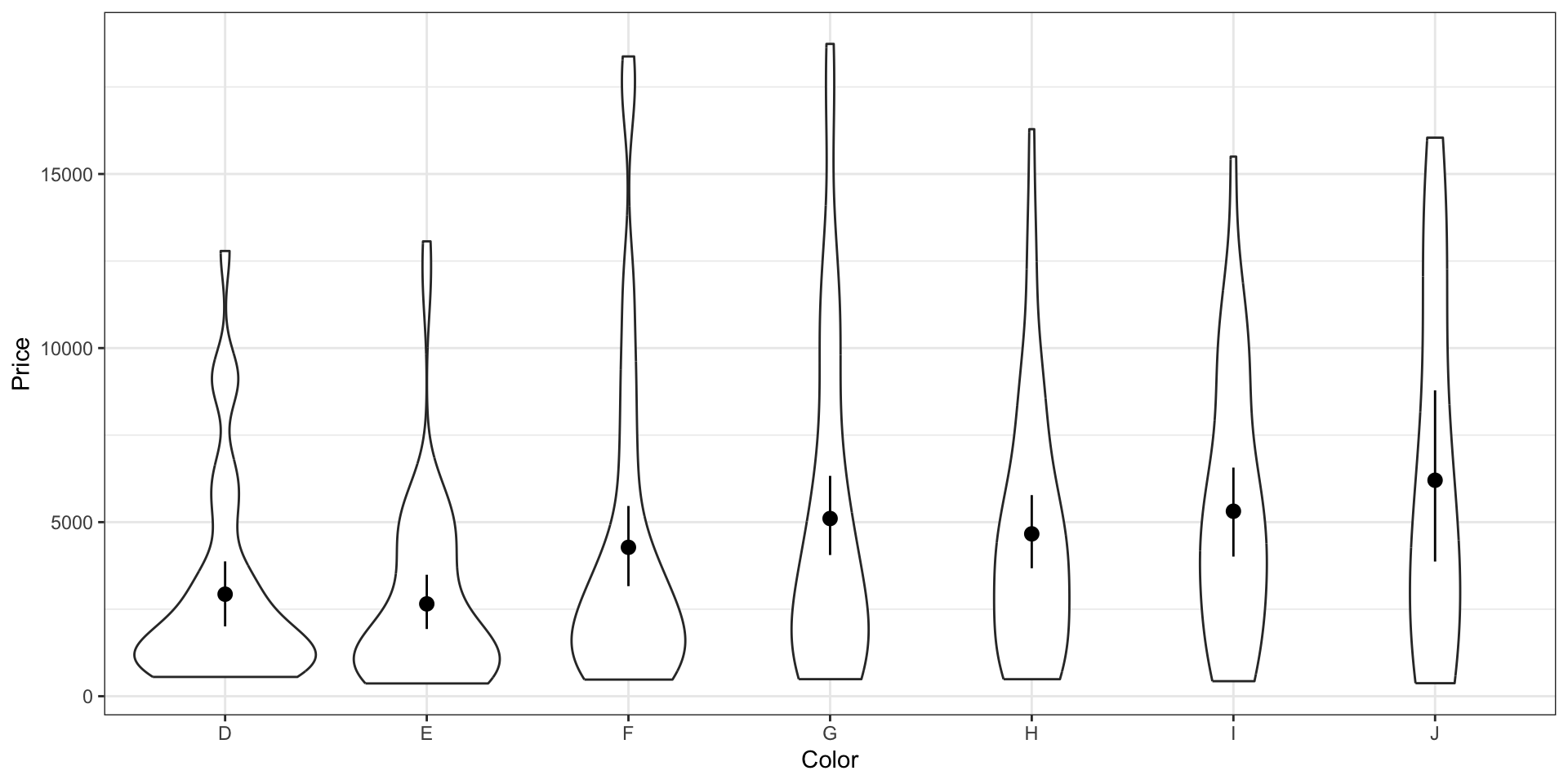
График интервальных оценок (Error bar)
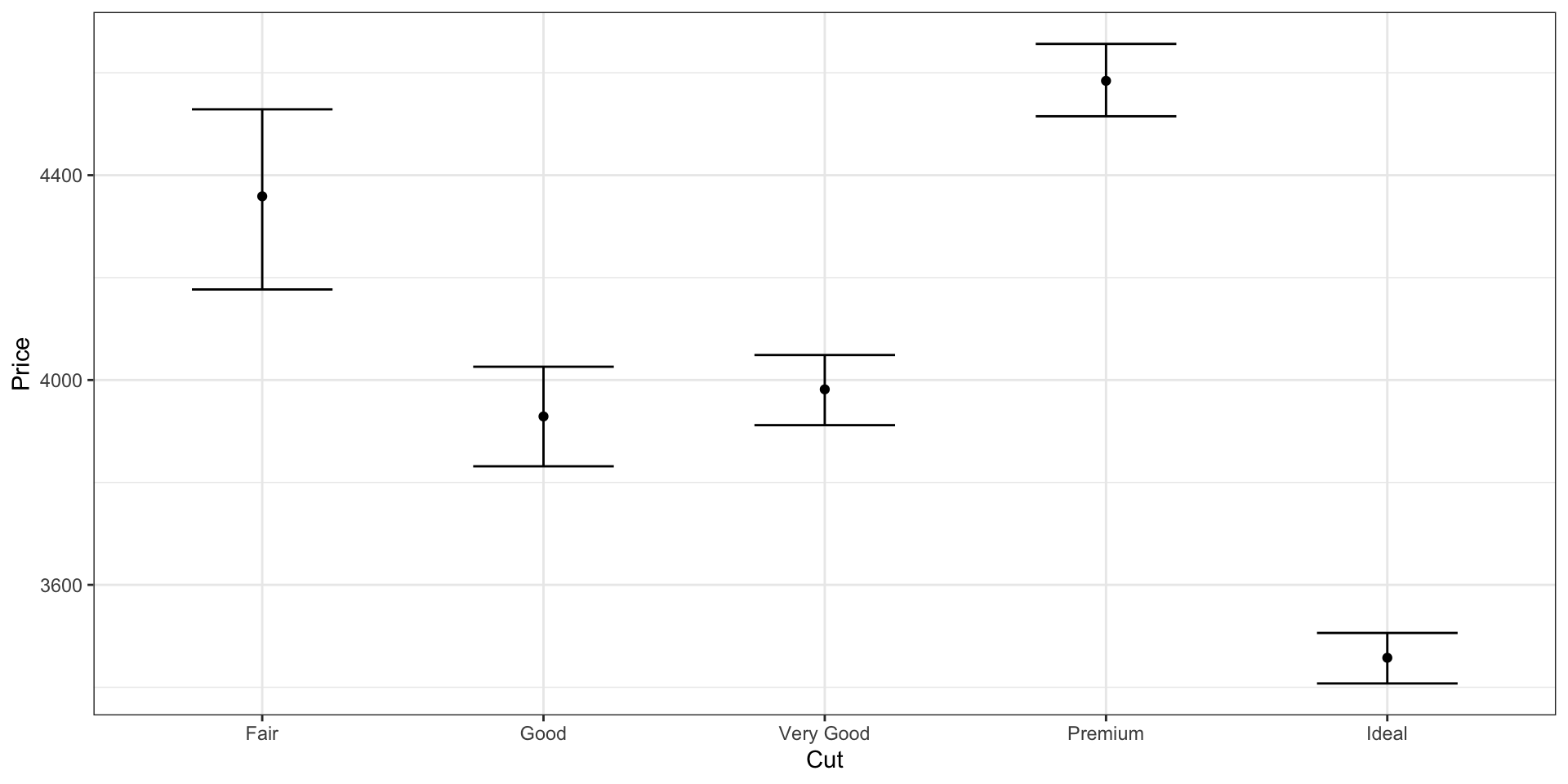
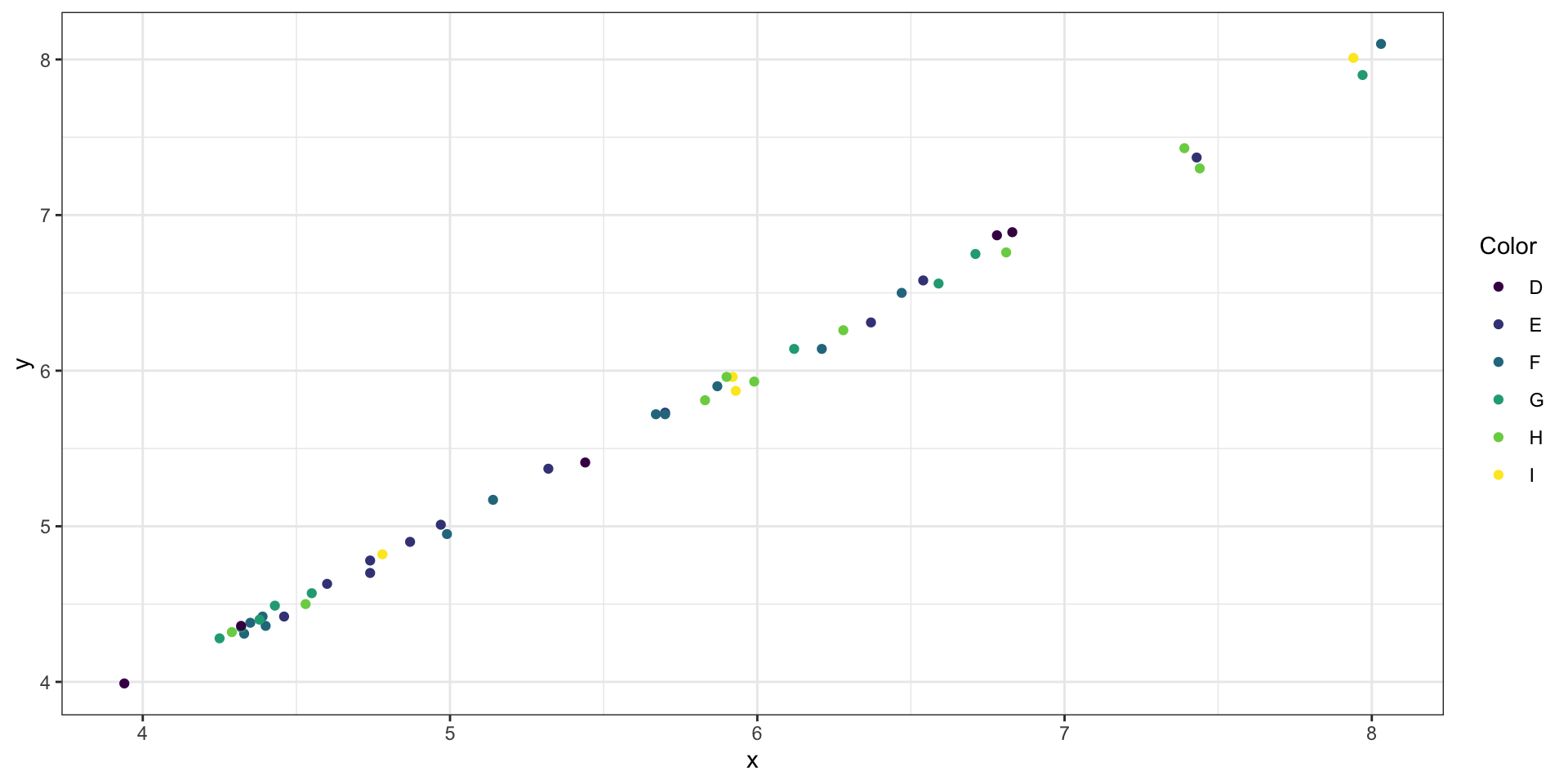
Диаграмма рассенияния (Scatter plot)
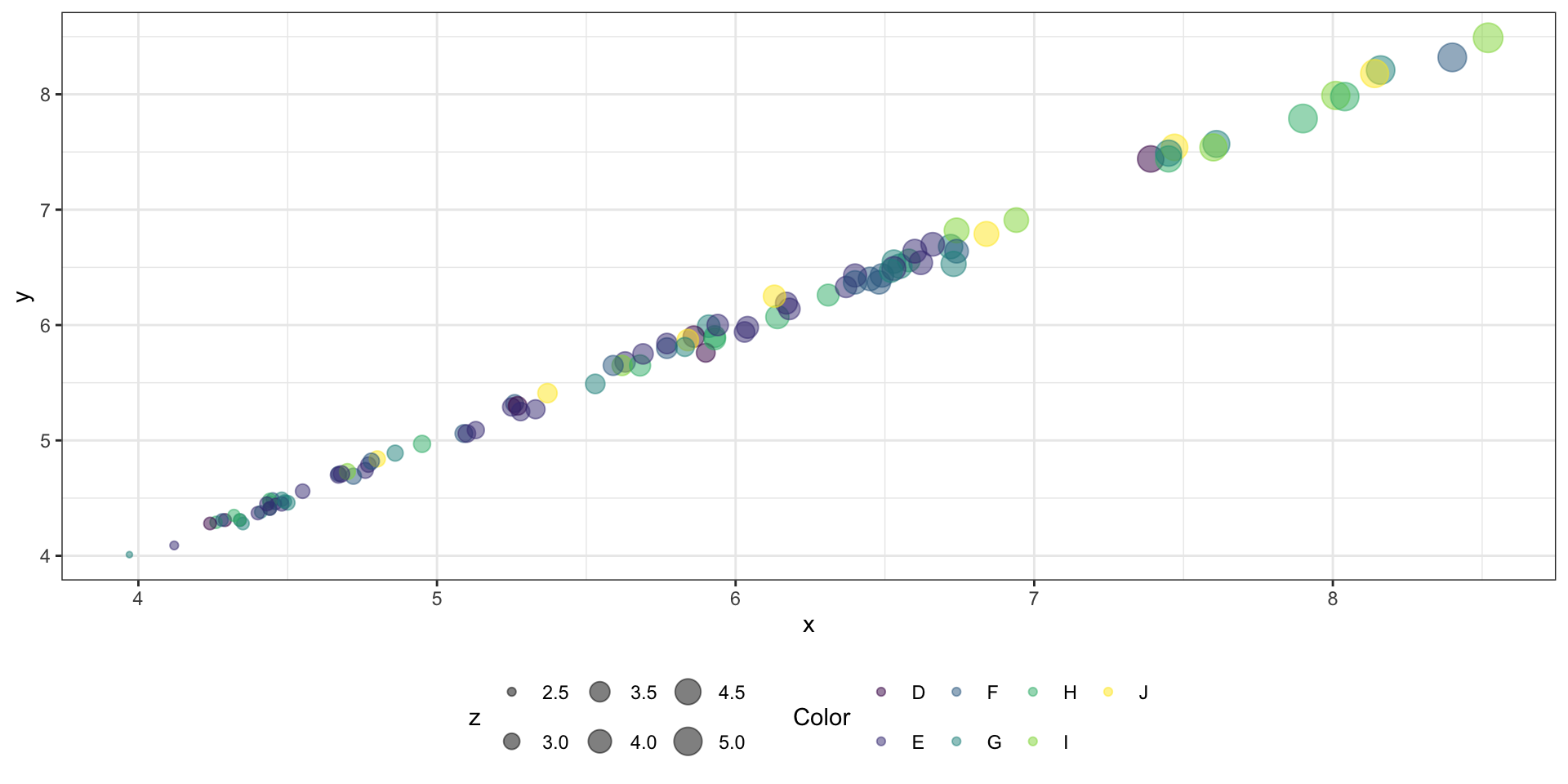
Пузырьковая диаграмма (Bubble plot)
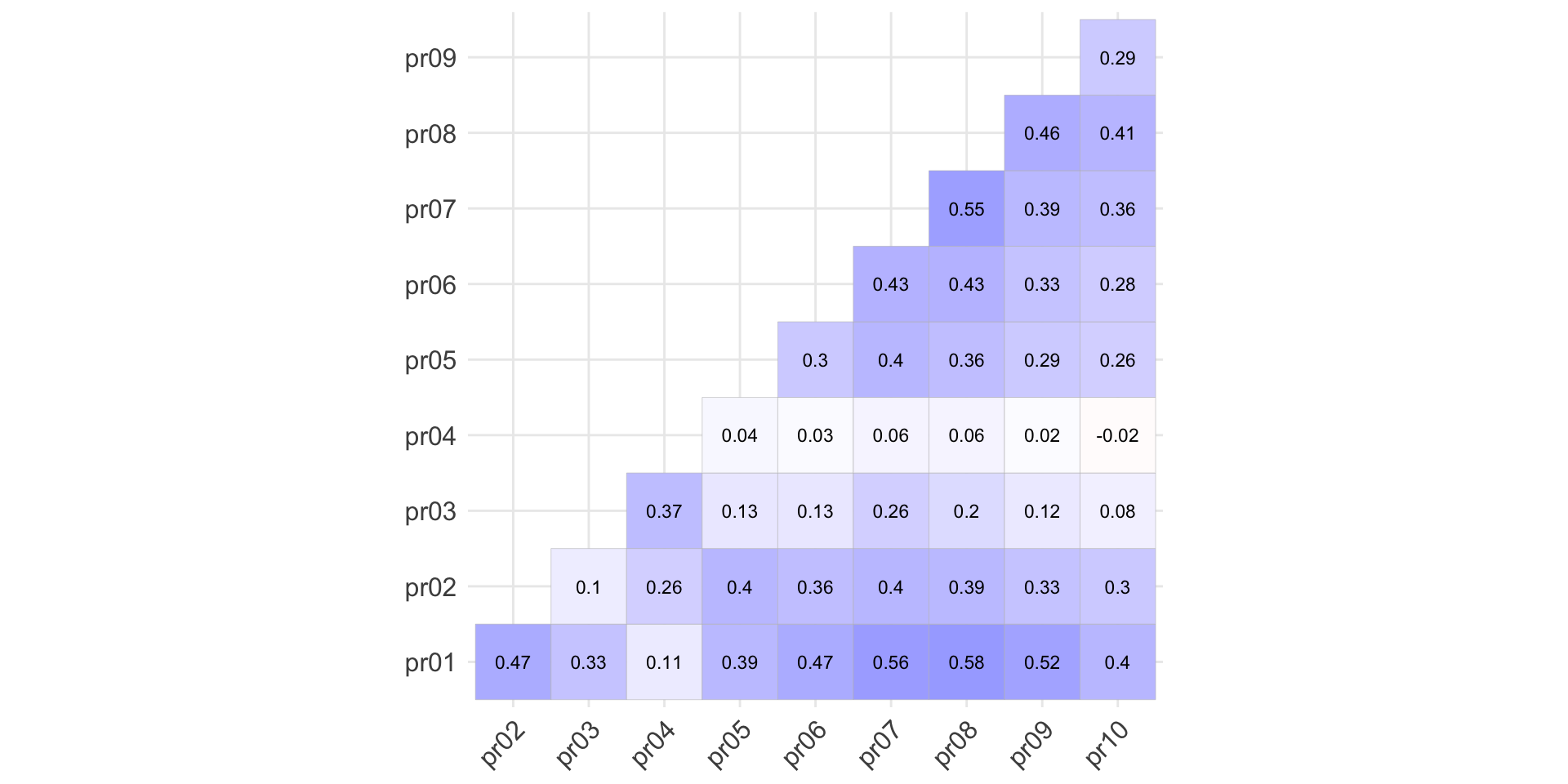
Корреляционная матрица (Corrplot)
L2 // Предобработка данных. Дата и время. Визуализация данных
![]()