J // Промежуточный проект
В этом проекте вам предстоит предобработать данные и построить несколько визуализаций.
- Проект содержит два варианта задания. Вам необходимо выполнить любой один из предложенных.
- Чтобы сдать первый этап проекта, необходимо загрузить в соответствующий раздел Google Classroom следующие файлы:
- скрипт формата .R (кодировка UTF-8), в котором выполнен проект
- сопроводительный файл с кратким описанием шагов предобработки и визуализации данных, отражающим подход к решению задания (формат PDF, не более одной страницы A4, шрифт Arial или Times New Roman, 12 пт, межстрочный интервал полуторный).
- Возможна сдача файлов формата
.Rmd(RMarkdown) или.qmd(Quarto) (кодировка UTF-8 или UTF-16) со сверстанными (прорендеренными) HTML-файлами к ним. Если выбран такой формат сдачи, сопроводительный текст включается непосредственно в сам файл работы, дополнительный файл PDF сдавать в таком случае не нужно. - Критерии оценивания проекта прикреплены к заданию в Google Classroom.
- Код должен воспроизводиться без каких-либо модификаций на компьютере эксперта.
- Скрипт должен содержать комментарии, поясняющие детали работы кода.
Вариант 1
Для работы вам предлагаются данные, полученные в ходе адаптации опросника на измерение когнитивной нагрузки NASA-TLX, выполненной командой HSE UX LAB1.
Архив с данными тут.
Это было большое исследование, поэтому нас будет интересовать только часть данных. В ходе адаптации, работоспособность опросника проверялась на нескольких задачах, одной из которых было мысленное вращение (mental rotation). Этими данными мы и займемся.
Что такое мысленное вращение (mental rotation)?
Человеку предъявляются две фигуры. Задача испытуемого заключается в том, чтобы определить, являются ли фигуры одинаковыми с точностью до поворота или две фигуры различны. Иллюстрация представлена ниже.
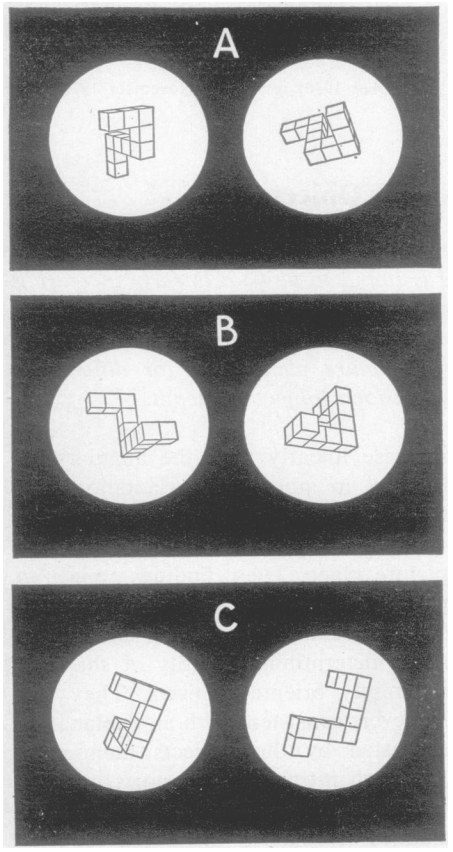
Подробно можно почитать в Shepard and Metzler (1971).
Из дизайна исследования для предобработки данных важно знать, что
- задача мысленного вращения была реализована в трех уровнях сложности — легком (
easy), среднем (medium) и сложном (hard) - в каждом из уровней сложности было 16 проб
- ответ давался нажатием на клавишу со стрелкой — вправо (
right), если фигуры одинаковые, и влево (left), если фигуры различны
Из организации файла сырых данных для предобработки данных важно знать, что
- в каждом файле лежат данные одного респондента
- в каждой строке находятся данные одной пробы
- все файлы имеют одинаковую структуру
Интересующие нас переменные датасета:
- для всех условий:
correctAns— верный ответ (left/right)base_pic— исходная картинка (название файла)rotated_pic— повернутая картинка (название файла)
- для условия
easy:resp_MR_easy.keys— ответ респондента в пробе (left/right)resp_MR_easy.corr— является ли ответ респондента корректным (0/1)resp_MR_easy.rt— время реакции (от начала предъявления стимула до момента нажатия на клавишу, с)
- для условия
medium:resp_MR_medium.keys— ответ респондента в пробе (left/right)resp_MR_medium.corr— является ли ответ респонтента корректным (0/1)resp_MR_medium.rt— время реакции (от начала предъявления стимула до момента нажатия на клавишу, с)
- в условии
hard:resp_MR_hard.keys— ответ респондента в пробе (left/right)resp_MR_hard.corr— является ли ответ респонтента корректным (0/1)resp_MR_hard.rt— время реакции (от начала предъявления стимула до момента нажатия на клавишу, с)
Задание
- Загрузите данные. Изучите их структуру, особенности записи.
- Приведите данные к виду Tidy Data, используя пакет
tidyverse. Предобработанные данные не должны содержать пропущенных значений. Финальный датасет должен содержать следующие колонки:id— идентификатор респондента (число или строка)level— уровень сложности задачи (строка,easy/medium/hard)trial— номер пробы в данном уровне сложности задачи (число)correct_ans— корректный ответ (строка)base_pic— исходная картинка (строка, название файла)rotated_pic— повернутая картинка (строка, название файла)key— ответ респондента в пробе (строка)is_correct— является ли ответ респондента корректным (число,0/1, из «сырых» данных)rt— время реакции (число)
- Удалите из данных выбросы по времени реакции. Выбросами считайте наблюдения, которые отклоняются от среднего значения более чем на 2.5 стандартных отклонения. Выбросы рассчитываются для каждого респондента отдельно с учетом уровней сложности задачи.
- Выгрузите предобработанные данные в формате CSV (кодировка UTF-8).
- Постройте график, отображающий распределение времени реакции в трех условиях сложности задачи мысленного вращения. Все подписи, присутствующие на графике, должны быть выполнены на русском языке. График должен быть оформлен так, чтобы его можно было напечатать на черно-белом принтере.
- Экспортируйте визуализацию в формате JPEG. Разрешение должно быть достаточным для печати.
- Аггрегируйте данные: рассчитайте среднее время реакции и точность (accuracy) для каждого респондента в каждом уровне сложности задачи. Точность вычисляйте как долю корректных ответов респондента в данном уровне сложности.
- Выгрузите аггрегированные данные в формате CSV (кодировка UTF-8).
- Постройте график, отображающий зависимость точности (accuracy) от уровня сложности сложности задачи. Все подписи, присутствующие на графике, должны быть выполнены на английском языке. Технических ограничений на цветовую палитру нет.
- Экспортируйте визуализацию в формате JPEG. Разрешение должно быть достаточным для печати.
Вариант 2
Для работы вам предлагаются данные World Happiness Report 20192.
Архив с данными тут.
Исходный датасет (countries.csv) содержит информацию о разных странах мира. Данные включают в себя следующие переменные:
Overall rank— обобщенный ранг страны по всем показателямCountry or region— название страны (или территории)Score— показатель уровня счастью в странеGDP per capita— ВВП (внутренний валовой продукт, gross domestic product) на душу населения
и другие показатели (Social support, Healthy life expectancy, Freedom to make life choices, Generosity, Perceptions of corruption), фиксировавшиеся в данном исследовании.
Дополнительно представлен датасет regions.csv.
Задание
- Загрузите данные. Изучите их структуру, особенности записи.
- Приведите данные к виду Tidy Data, используя пакет
tidyverse. К предобработанным данным предъявлены следующие требования:- предобработанные данные не должны содержать пропущенных значений
- финальный датасет должен содержать всю информацию исходного датасета, а также регион, в котором находится страна
- названия столбцов датасета не должны содержать пробелов и заглавных букв
- Выгрузите предобработанные данные в формате CSV (кодировка UTF-8).
- Аггрегируйте данные по регионам. В аггрегированных данных по каждому из показателей отчета должны быть посчитаны среднее и стандартное отклонение.
- Выгрузите аггрегированные данные в формате CSV (кодировка UTF-8).
- Постройте график, отражающий уровень счастья в каждой стране для европейских стран. Страны на графике должны быть сгруппированы по регионам. График должен быть оформлен так, чтобы его можно было напечатать на черно-белом принтере.
- Экспортируйте визуализацию в формате JPEG. Разрешение должно быть достаточным для печати.
- Постройте график, отображающий связь между ВВП на душу населения и уровнем счастья для стран Африки. Отобразите общий тренд. Страны должны быть сгруппированы по региону, однако при отображении тренда группировка учитываться не должна. Оптимизируйте визуализацию так, чтобы пространство графика использовалось наиболее эффективно. Технических ограничений на цветовую палитру нет.
- Экспортируйте визуализацию в формате JPEG. Разрешение должно быть достаточным для печати.