"psych" %in% installed.packages()P9 // Описательные статистики. Корреляционный анализ
Основные задания
Пакеты
Сегодня нам понадобится несколько новых пакетов.
psychggcorrplotggmosaicpwrqgraphreportapaTablesltm
Проверить, установлен ли пакет, можно с помощью команды:
Если какие-то пакеты отсутствуют, то необходимо их установить с помощью функции install.packages().
#1
Мы начнем работать сегодня с психометрическими данными. По ссылке лежат данные количественной апробации опросника на доверие к искусственому интеллекту (Trust in Artificial Intelligent Agents, TAIA).
Структура опросника
Опросник состоит из шести шкал:
- предсказуемость (predictability, PR)
- последовательность (consistency, CO)
- полезность (utility, UT)
- вера (faith, FA)
- надежность (dependability, DE)
- понимание (understanding, UN)
Баллы по шкалам опросника рассчитываются прямой суммой баллов по всем пунктам шкалы. Также в операционализации был выделен общий фактор доверия, выражающийся через сумму баллов по всем шкалам опросника.
В опросник использовалась шестибалльная шкала Ликерта.
- Загрузите данные.
- Изучите их структуру, при необходимости скорректируйте типы переменных.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#2
Посмотрим, что происходит на отдельных шкалах опросника — исследуем шкалы Predictability (PR) и Utility (UT). Визуализируйте распределения баллов по каждому пункту шкал.
Описание формата инпута.
Подсказки
- Так как в операционализации подразумевается, что шкалы относительно независимы друг от друга, разумно построить два графика — один для пунктов шкалы PR, другой для пунктов шкалы UT.
- Для визуации распределения баллов по каждому пункту хорошо подойдет фасетизация.
- Возможно, гистограмма в данном случае не лучший вариант. Попробуйте преобразовать переменную с баллами в коде построения графика, чтобы визуализация выглядела красивее.
#3
Рассчитайте описательные статистики для каждого пункта шкал PR и UT. Итоговая таблица должна включать следуюшие описательные статистики:
- среднее [арифметическое]
- стандартное отклонение
- медиану
- усеченное среднее
- минимум
- максимум
- размах
- коэффициент асимметрии
- коэффициент эксцесса
Воспользуйтесь средствами пакета tidyverse.
Описание формата инпута.
Подсказки
- Так как нам нужно два раза выполнять одни и те же расчеты — а в реальной жизни пришлось бы повторять их шесть раз, так как в опроснике шесть шкал — логично написать функцию, которая будет вычислять необходимые статистики.
- В функцию можно сразу включить и необходимые преобразования датасета, чтобы мы могли ей передавать исходный датасет не заботясь об извлечении нужный переменных и приведению данных нужному формату.
#4
tidyverse, безусловно, мощь и сила, но так как мы сегодня немножко психометрики, то можно воспользоваться и специальными пакетами. Для психометриков написан пакет psych, в котором есть много всего полезного, в том числе функции describe() и describeBy().
- Изучите, как работают эти функции.
- Рассчитайте описательные статистики для пунктов шкал с их помощью.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#5
Отлично, общую ситуацию в шкалах мы осознали. Давайте посмотрим на отношения пунктов друг с дргуом внутри шкал. Для этого хорошо подойдет корреляционная матрица.
- Рассчитайте корреляцинные матрицы для пунктов шкал PR и UT. Сохраните результаты в объекты
pr_corиut_cor. - Рассчитайте корреяционные матрицы для пунктов шкал DE и UN. Сохраните результаты в объекты
de_corиun_cor.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#6
Визуализируйте корреляционные матрицы из предыдущего задания.
Описание формата инпута.
Подсказка
ggcorrplot()
#7
Проведем конвергентную валидизацию методики. Для этого нам необходимо рассчитать корреляцию между баллами по опросникам TAIA и General Trust Scale. Однако сначала необходимо аггрегировать имеющиеся данные.
- Рассчитайте суммарный балл по опроснику для каждого респондента. В ходе количественной апробации было обнаружено, что пункты
co07,ut10, иde04обладают плохими психометрическими характеристиками, а пунктыpr03,pr04,fa03,fa07,de11плохо вписываются в конфирматорную модель. Исключите эти пункты из расчета суммарного балла. - Рассчитайте средний балл по пунктам опросника General Trust Scale. Пункты записаны как
gt01,gt02,gt03,gt04,gt05,gt06. с. Объедините результаты подсчета суммарного балла для TAIA со средними баллами по шкале General Trust Scale по идентификатору респондента (id).
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#8
Визуализируйте связь между интегральными баллами TAIA Scale и General Trust Scale с помощью диаграммы рассеяния.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#9
Протестируйте гипотезу об отсутствии связи между баллами TAIA Scale и General Trust Scale.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#10
В ходе апробации также были собраны данные о частоте использования социальных сетей (переменная f_socnet). В качестве еще одного свидетельства валидности уместно было бы посмотреть, коррелирует ли частота использования социальных сетей с баллом по опроснику TAIA.
- Исследуйте переменную
f_socnet. - Каким коэффициентом корреляции было бы корректнее здесь воспользоваться? с. Рассчитайте корреляцию между интегральным баллом по опроснику и частотой использования социальных сетей. Протестируйте гипотезу об отсутствии искомой связи.
Описание формата инпута.
Подсказка
Частота использования социальных сетей измерялась по данным самоотчета. Ответ на соответствующие вопросы давался с помощью шкалы Ликерта. Агрегировались данные через расчет медианы.
#11
Визуализируйте связь между частотой использования социальных сетей и интегральным баллом по опроснику TAIA.
Описание формата инпута.
Подсказка
Как делать задание?
Что надо сделать?
Ответ неверный
#12
Поработаем с корреляционными матрицами. Для этого нам понадобятся результаты апробации опросника NASA-TLX.
Загрузите данные. Изучите их структуру. При необходимости скорректируйте типы переменных.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#13
Постройте корреляционные матрицы по шкалам опросника (ME, PH, TI, PE, EF, FR) для разных уровней сложности (level) задачи мысленного вращения (task, MR). Сохраните их в объекты mr_easy_cor, mr_medium_cor, mr_hard_cor.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#14
Сейчас у нас есть данные в том, как коррелируют шкалы друг с другом в разных уровнях сложности задачи мысленного вращения. Однако нам хотелось бы получить обобщенную информацию о том, как ведут себя шкалы в задаче мысленного вращения. Для этого необходимо усреднить три полученные матрицы.
Конечно, велик соблазн взять и просто усреднить все три матрицы через среднее арифметическое, однако это далеко не лучший способ. Сначала воспользуемся z-преобразованием Фишера.
Приведите рассчитанные корреляции к z-оценкам с помощью преобразования Фишера. Сохраните результаты в объекты mr_easy_cor_, mr_medium_cor_, mr_hard_cor_ соответственно.
Описание формата инпута.
Подсказка
atanh()
#15
Теперь все готово к усреднению корреляций.
- Рассчитайте средние z-оценки корреляций по полученным матрицам.
- Выполните обратное преобразование, чтобы вернуться к исходным диапазонам значения корреляций.
Сохраните результат в объект mr_pooled_cor.
Описание формата инпута.
Подсказка
tanh()
#16
Окей, мы насчитали много всякого. Хотелось бы теперь это каким-то образом экспортировать, что можно было использовать при написании отчетов, статей и т.д.
Самый простой вариант — это перенаправить консольный вывод в файл. Для этого есть функция sink().
Сохраните аутпут функции cor.test из задания 9 в файл converg_valid_results.txt.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#17
Вариант экспорта результатов из предыдущего задания в целом весьма рабочий, однако далеко не оптимальный. Скажем, если мы выгрузим в таком варианте корреляционную матрицу, нам все равно придется перебивать её в док статьи руками. Не хлтелось бы так.
Пакет apaTables облегчает нам жизнь и позволяет экспортировать уже отформатированные в APA-формате таблицы корреляций.
Выгрузите корреляцию матрицу mr_pooled_cor в формате APA.
Описание формата инпута.
Подсказка
apaTables::apa.cor.table(corr_matrix, filename = "...")
#18
Корреляционная матрица это хорошо, но для описания результатов нам также пригодится какой-то способ форматировать аутпут функции cor.test() в текстовое описание результатов корреляционного анализа. Здесь нам поможет пакет report.
Возьмите аутпут функции cor.test() из задания 9 и отформатируйте его в текстовое описание результатов корреляционного анализа.
Описание формата инпута.
Подсказка
report::report()
#19
Отлично, результаты в красивом оформлении у нас есть. Но что делать, есть мы только в начале исследовательского пути, и нам нужно рассчитать объем выборки, необходимой для проведения корреляционного анализа? Тут нам пригодится пакет pwr.
Рассчитайте объем выборки, необходимый для достижения достаточной статистической мощности, если ожидаемый размер эффекта средний.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#20
Напоследок посмотрим ещё на один интересный способ визуализации корреляционной матрицы в виде графа. На таком графике корреляции отображаются линиями между переменными — чем толще линия, тем сильнее корреляция. Цвет обозначает направление корреляции. Кроме того, переменные группируются в зависимости от силы связей между ними.
Постройне такой граф с помощью функции qgraph() из пакета qgraph на данных TAIA.
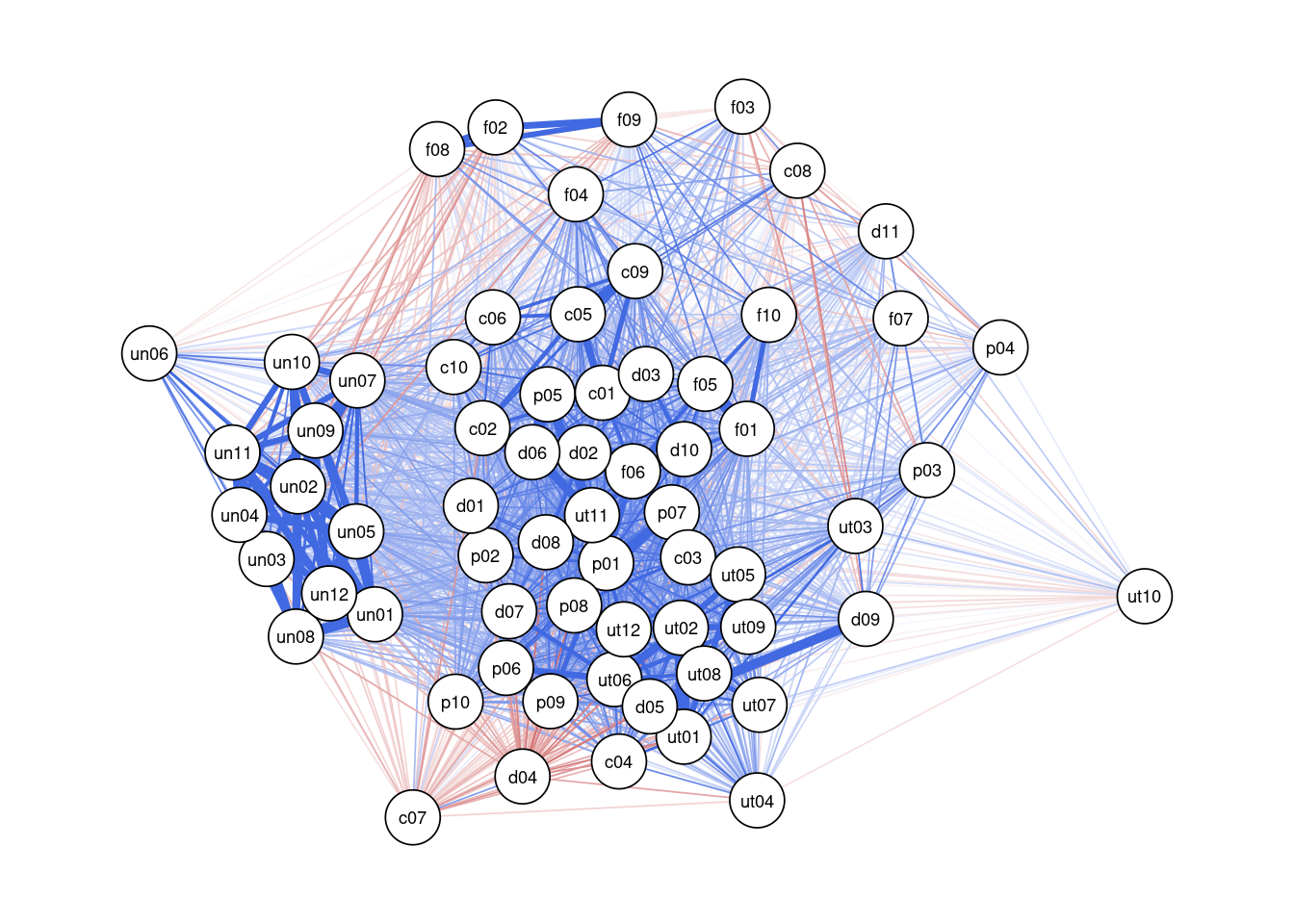
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
Дополнительные задания
#1
Исследуйте корреляцию между частотой использования социальных сетей (f_socnet) и количеством цифровых ассистентов, используемых респондентом (n_dighelp).
- Исследуйте переменные.
- Какой коэффициент корреляции здесь лучше всего использовать?
- Проведите статистический тест и проинтерпретируйте результаты.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#2
Визуализируйте результаты корреляционного анализа из предыдущего задания.
Описание формата инпута.
Подсказка
ggmosaic
geom_mosaic()
#3
Ещё один свидительством валидности может стать связь между областью работы респондента — связанная с цифровыми технологиями или не связанная — и баллом по опроснику. В данных апробации TAIA есть переменная dig_job, которая равна TRUE, если область работы респондентна связана с цифровыми технологиями, и FALSE, если не связана.
Протестируйте гипотезу о связи тестового балла с областью работы респондента.
Описание формата инпута.
Подсказкa
ltm::biserial.cor()
#4
Кроме области работы (dig_job), в данных есть еще переменная dig_spec, которая равна TRUE, если респондент получил специальность, связанную с цифровыми технологиями, и FALSE, если его специальность не была связана с цифрой.
Проверьте, если ли связь между тем, какую специальность респондент получил, и в какой области он работает.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#5
На основе результата, полученного в предыдущем задании, рассчитайте \(\phi\)-коэффициент для оценки корреляции между переменными dig_job и dig_spec.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#6
Напишите функцию для вычисления стандартной ошибки коэффициента корреляции.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#7
Напишите функцию, которая рассчитывает доверительный интервал для коэффициента корреляции на основе стандартной ошибки.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#8
Напишите функцию, которая рассчитывает требуемый объем выборки для корреляционного анализа на основе стандартной ошибки.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#9
Напишите функцию для вычисления моды дискретной переменной.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#10
Иногда в ходе исследования возникает задача сравнить две корреляционный матрицы. Например, у нас есть результаты оригинальной апробации психометрической методики, где представлены матрица корреляций пунктов и/или шкал, и в ходе адаптации мы также получает аналогичную корреляционную матрицу. Собственно, возникает вопрос: похожи ли те корреляции, котоыре мы получили, на корреляции оригинальной статьи?
Для того, чтобы ответить на этот вопрос, можно воспользоваться функцией cortest() из пакета psych.
Проверьте, отличается ли матрица mr_pooled_cor от корреляционной матрицы оригинального исследования.
Функция cortest в качестве аргументов просит две матрицы R1 и R2 и соответствующие объемы выборок n1 и n2, на которых эти корреляции были посчитаны. Объем выборки оригинального исследования составил 6 человек, объем выборки адаптации — 69 человек.
Описание формата инпута.