HW10 // Дисперсионный анализ. Ковариационный анализ
Основные задания
Данные поведенческого эксперимента
Сегодня в нашем меню данные эксперимента, проведенного на благо юзабилити-индустрии.В исследовании изучалось влияние перцептивных характеристик иконок на эффективность их обнаружения. Да, снова зрительный поиск…
В эксперименте варьировались следующие параметры стимулов:
- тип стимула (
type):flat— плоский,grad— содержит градиент - тень (
shadow):TRUE— есть,FALSE— нет
Также традиционно варьировалось число стимулов в пробе (setsize) — 3, 6, 9. Перед каждой пробой испытуемому предъявлялась целевая иконка. Если испытуемый нашёл целевую иконку среди всех предложенных, он нажимал (key) стрелку вправо (right), если не обнаружил — стрелку слево (left). Так как ответ давался клавишами, в дизайне исследования были предусмотрены «пробы-ловушки» (pres), в которых не было целевого стимула. Пробы, в которых целевой стимул присутствовал, обозначены как p, а пробы, в которых целевой стимул отсутствовал — a.
Все испытуемые проходили все экспериментальные условия. Зависимой переменной в эксперимента было время ответа испытуемого (время реакции, time).
Глобальный вопрос к результатам эксперимента: какие факторы влияют на скорость поиска иконок?
#1
- Загрузите данные, проверьте их структуру.
- Отберите только корректные пробы, в которых присутствует целевой стимул.
В качестве ответа для самопроверки введите число строк в получившемся после отбора необходимых проб датасете.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#2
- Приведите переменную
setsizeк факторному типу данных и агрегируйте (усредните) данные по каждому респонденту с учетом всех экспериментальных условий. - Проверьте, что данные эксперимента сбалансированы по количесву наблюдений в каждом сочетании условий.
В качестве ответа для самопроверки если данные сбалансированы, введите в поле ответа да, если не сбалансированы, введите нет.
Подсказки
Как агрегировать данные?
- Чтобы получить агререгированные данные, необходимо посчитать среднее значение времени реакции каждого испытуемого в каждом сочетании экспериментальных условий.
- Для этого необходимо задать группировку датасета по экспериментальным переменным (
type,shadow,setsize) и идентификатору испытуемого (id). Здесь пригодится либо функцияgroup_by(), либо аргумент.byфункцииsummarise(). - Далее нужно вычислить среднее (
mean()) по переменнойtime.
Как проверить сбалансированность?
- Чтобы выяснить, сбаласированы ли данные, необходимо посчитать количество наблюдений в каждом сочетании экспериментальных условий в агрегированных данных.
- Для этого необходимо задать группировку датасета по экспериментальным переменным (
type,shadow,setsize). Здесь пригодится либо функцияgroup_by(), либо аргумент.byфункцииsummarise(). - Далее нужно вычислить количество наблюдений в группах (
n()).
Ответ неверный
- Проверьте группировку в агрегации данных.
- Проверьте группировку в оценке сбалансированности данных.
#3
Проведите дисперсионный анализ экспериментальных данных. В качестве факторов модели используйте переменные setsize, type и shadow. В качестве зависимой переменной используйте время реакции. Модель дисперсионного анализа должна быть согласована с экспериментальным дизайном. Проинтерпретируйте результаты. При необходимости проверите попарные сравнения (post hoc тесты).
В качетсве ответа для самопроверки в поле ниже введите значение F-статистики, полученные для фактора shadow, округленное до сотых. В качестве десятичного разделителя используйте точку.
Подсказки
Какая должна быть модель?
- В описании данных сказано, что все испытуемые проходили все экспериментальные условия.
- Значит, все экспериментальные переменные являются внутригрупповыми.
- Следовательно, в модели дисперсионного анализа эти переменные должны задачать within-subject эффекты.
Какие попарные сравнения нужны?
- Какие группы наблюдений мы будем сравнивать в post hoc тестах зависит от того, что получилось в дисперсионном анализе:
- если получилось значимое взаимодействие, то и в попарных сравнениях нас интересуют, прежде всего, различия между группами по сочетаниям условий.
- если значимым получились только основные эффекты, то и в попарных сравнениях мы будем изучать различия по группам, задаваемым отдельными факторами.
- Если результаты дисперсионного анализа показывают отсутствие значимости всех факторов, то попарные сравнения бессмысленны.
Какую поправку использовать?
- Если вам всё же необходимы post hoc тесты, то нельзя обойтись без поправки на множественные сравнения.
- Основных варианта два — поправка Холма и поправко Бонферрони. Одна более мягкая, другая более жесткая.
- Какую нужно использовать, зависит от выполнения допущения о сферичности данных. Если допущение по фактору выполнено, то можно использовать более мягкую, если не выполнено — необходима более жесткая.
Ответ неверный
#4
Визуализируйте результаты дисперсионного анализа.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#5
Экспортируйте таблицу с результатами дисперсионного анализа.
Описание инпута.
Подсказки
- Способ экспорта таблицы в результатами зависит от того, с помошью какой функции вы проводили дисперсионный анализ:
- если использовалась
aov(), то необходима функцияapa.aov.table()из пакетаapaTables - если использовалась
ezANOVA()из пакетаez, то необхоимо обратить к результатам работы функции, извлечь из них объектANOVAи выгрузить его, например, с помощью функцииwrite_excel_csv()(для более простого преобразования в Excel-формат далее).
- если использовалась
Данные приложения доставки
Теперь немного коснемся индустрии. Из исследователя ученого мы резко преобразовались в исследователя-аналитика компании доставки продуктов. Разработчики сделали новый — по их мнению, более удобный — дизайн приложения для заказов и выкатили его для тестирования на части пользователей. Другая часть пользователей видела старый дизайн.
У вас есть данные за период тестирования:
id— идентификатор пользователяgroup— группа пользователей:test— тестовая, которая видела новый дизайнcontrol— контрольная, которая видела старый дизайн
segment— сегмент пользователей:low— низкий, неактивные пользователя приложения, совершают мало заказовhigh— высокий, активные пользователя приложения, совершают много заказов
order— количество заказов пользователя в течение периода тестирования
Тимлид разработчиков пришел к вам со следующим вопросом: стоит ли выкатывать новый дизайн на всех пользователей? Ответьте на вопрос, опираясь на имеющиеся данные.
#6
- Загрузите данные, проверьте их структуру.
- Проверьте сбалансированность данных по количеству наблюдений в каждом сочетании условий.
В качестве ответа для самопроверки если данные сбалансированы, введите в поле ответа да, если не сбалансированы, введите нет.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#7
На основе результатов предыдущего задания определите, какой тип сумм квадратов необходимо использовать при проверки гипотез для ответов на вопросы заказчика.
Задание не предполагает написание кода. В скрипте кратко изложите ход своего рассуждения и закомментируйте эти строки.
Описание формата инпута.
Подсказки
- Всего возможно три типа сумм квадратов — I, II и III.
- У первого типа сумм квадратов есть неприятная особенность.
- Использование второго и третьего сумм квадратов определяется сбалансированностью данных.
#8
Постройте линейную модель, которая позволит ответить на поставленный тимлидом разработчиков вопрос, в необходимой параметризации.
В качестве ответа для самопроверки в поле ниже введите значение интерсепта построенной модели, округленное до сотых. В качестве десятичного разделителя используйте точку.
Подсказки
- Способ параметризации модели зависит от выбранного типа сумм квадратов
- в одном случае способ параметризации не имеет значения
- в другом необходим только определенный способ параметризации, иначе результаты тестирования гипотез будут некорректны
- Так как значение интерсепта модели будет зависеть от выбранного способа параметризации, ошибка при самопроверки может быть связана с неверно выбранной парамтеризацией модели.
#9
Проведите дисперсионный анализ с помощью построенной в предыдущем задании модели. Проинтерпретируйте полученные результаты.
В качетсве ответа для самопроверки в поле ниже введите значение F-статистики, полученное для фактора group, округленное до целого.
Подсказки
Тестирование с помощью конкретного типа сумм квадратов
- Большинство функций дисперсионного анализа работают со вторм типом сумм квадратов.
- Функция
Anova()из пакетаcarпозволяет прописать в аргументtype, какой именно тип сумм квадратов необходимо использовать.
Ответ неверный
- Проверьте способ параметризации модели
- Проверье используемый тип сумм квадратов
- Проверьте округление — значение необходимо округлить до целого
#10
- Визуализируйте результаты анализа.
- На основе визуализации дайте ответ на вопрос тимлида разработчиков.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
Дополнительные задания
Продолжим погружать в фонетические данные
На практике мы работали с данными о гласных русского языка.
Мы изучали, как различается длительность гласных в зависимости от ступени редукции и позиции в слове. Однако редукция влияет не только длительность гласных но и на их спектральный (частотный) состав. Давайте посмотрим, различаются ли частотные характеристики отдельных гласных в зависимости от ступени редукции.
Нас будут интересовать следующие переменные:
phoneme— обозначение фонемы- к нередуцированным гласным относятся
o,i,a,u,e,ɨ - к первой ступении —
ɐ,ɪ,ʊ,ɨ̞ - ко второй ступении —
ə̝,ə,əᶷ
- к нередуцированным гласным относятся
f1— частота первой формантыf2— частота второй форманты
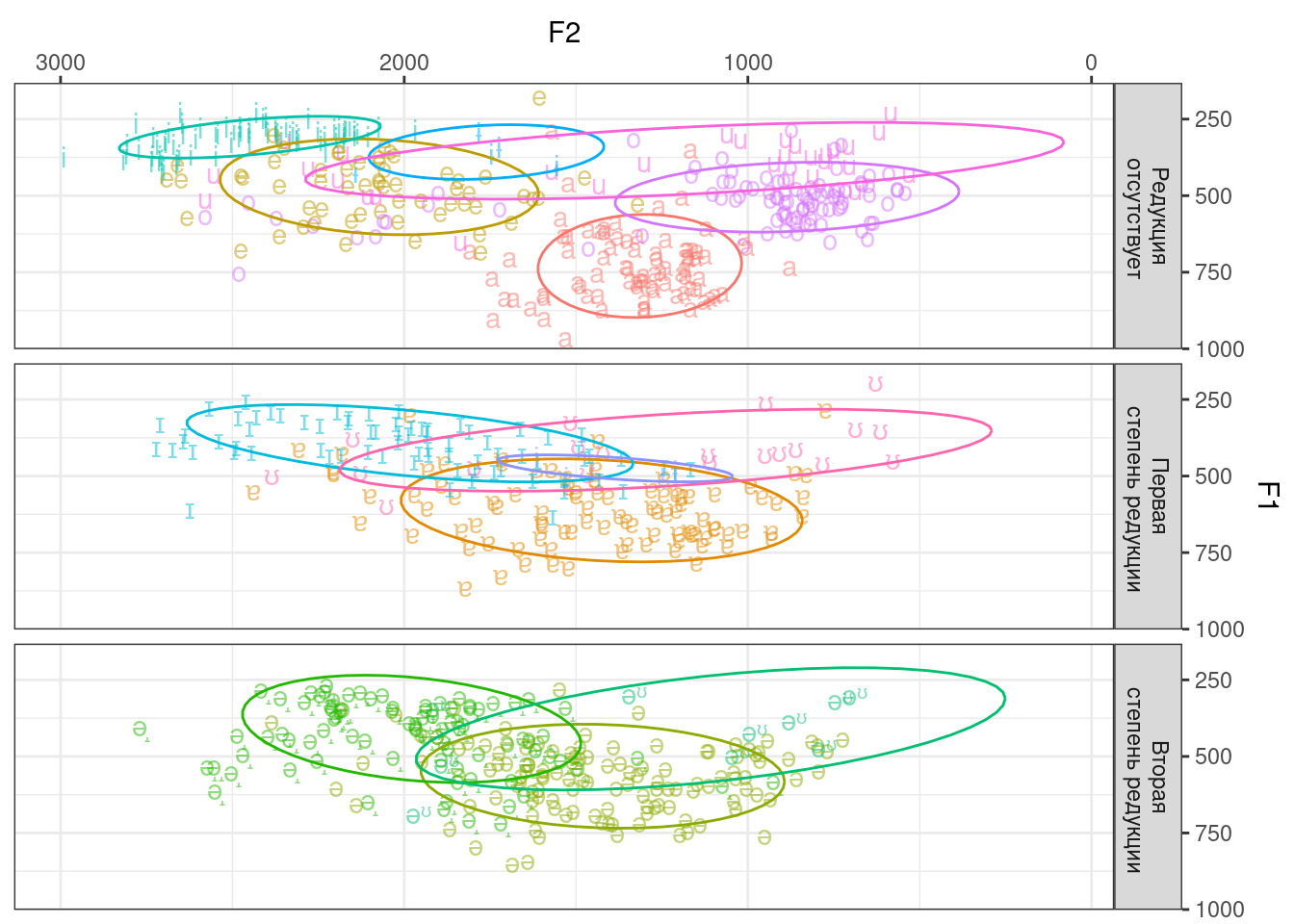
Когда-то в домашке по визуализации в одном из дополнительных заданий надо было нарисовать такую картинку, которая отображает вокалической пространство русского языка:
Но будем решать задачу постепенно.
#1
Загрузите данные, приведите переменную phoneme к факторному типу данных.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#2
Чтобы модели не были чрезмерно сложны, возьмем для сравнения только нередуцированные гласные и гласные первой ступени редукции. Нас будут интересовать следующие контрасты:
ivsɪevsɪavsɐovsɐuvsʊ
Создайте матрицу кодировки для этих контрастов.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#3
Протестируйте гипотезы о различии частотных характеристик первой форманты (f1) по заданным контрастам. Проинтерпретируйте полученные результаты.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#4
Протестируйте гипотезы о различии частотных характеристик второй форманты (f2) по заданным контрастам. Проинтерпретируйте полученные результаты.
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#5
Визуализируйте полученные результаты. Постройте график, представленный ниже.
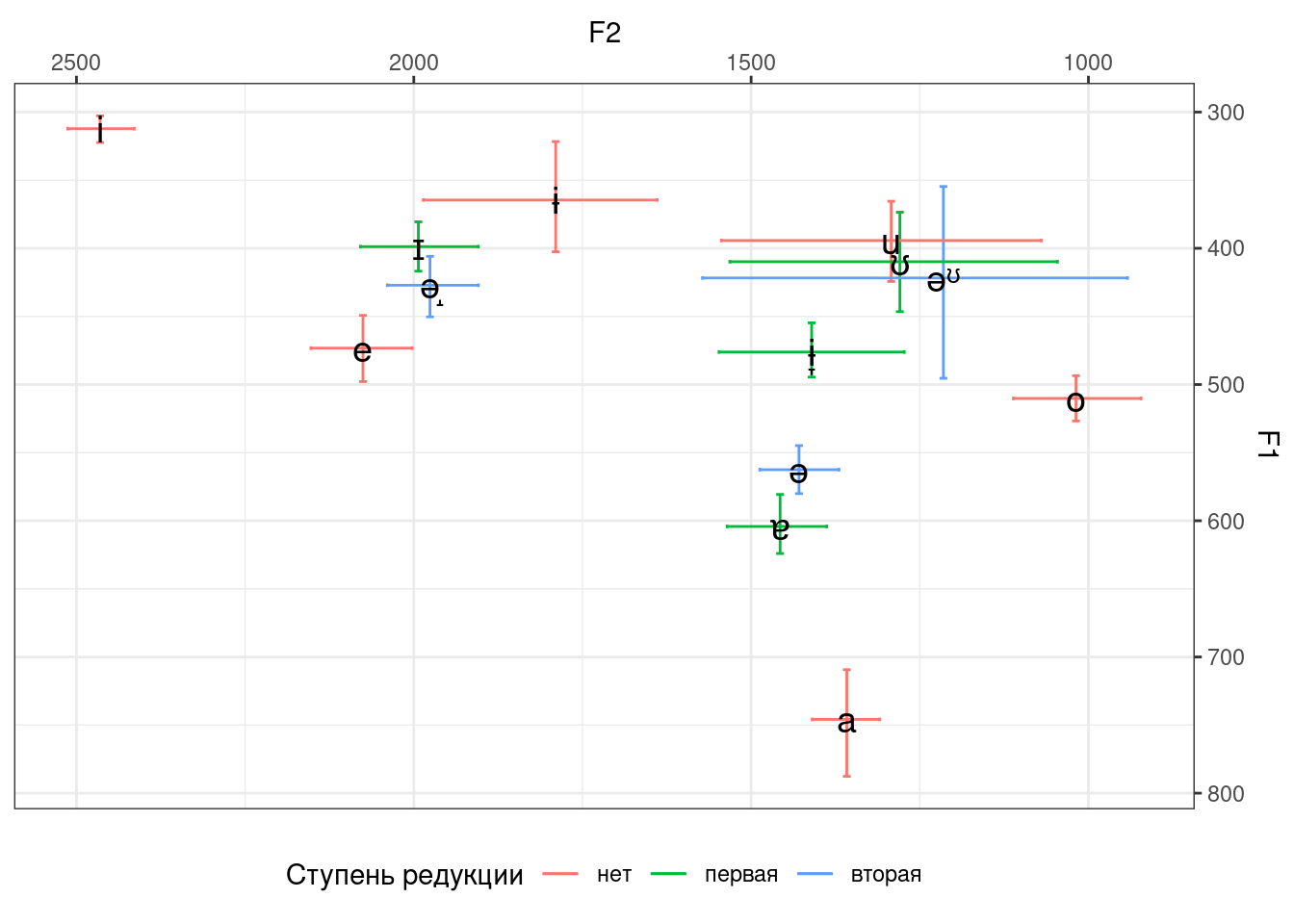
Описание формата инпута.