HW16 // Конфирматорный факторный анализ
Основные задания
Сегодня мы вновь работаем с датасетом по Большой пятерке (Big Five). Вспомнить структуру модели можно тут.
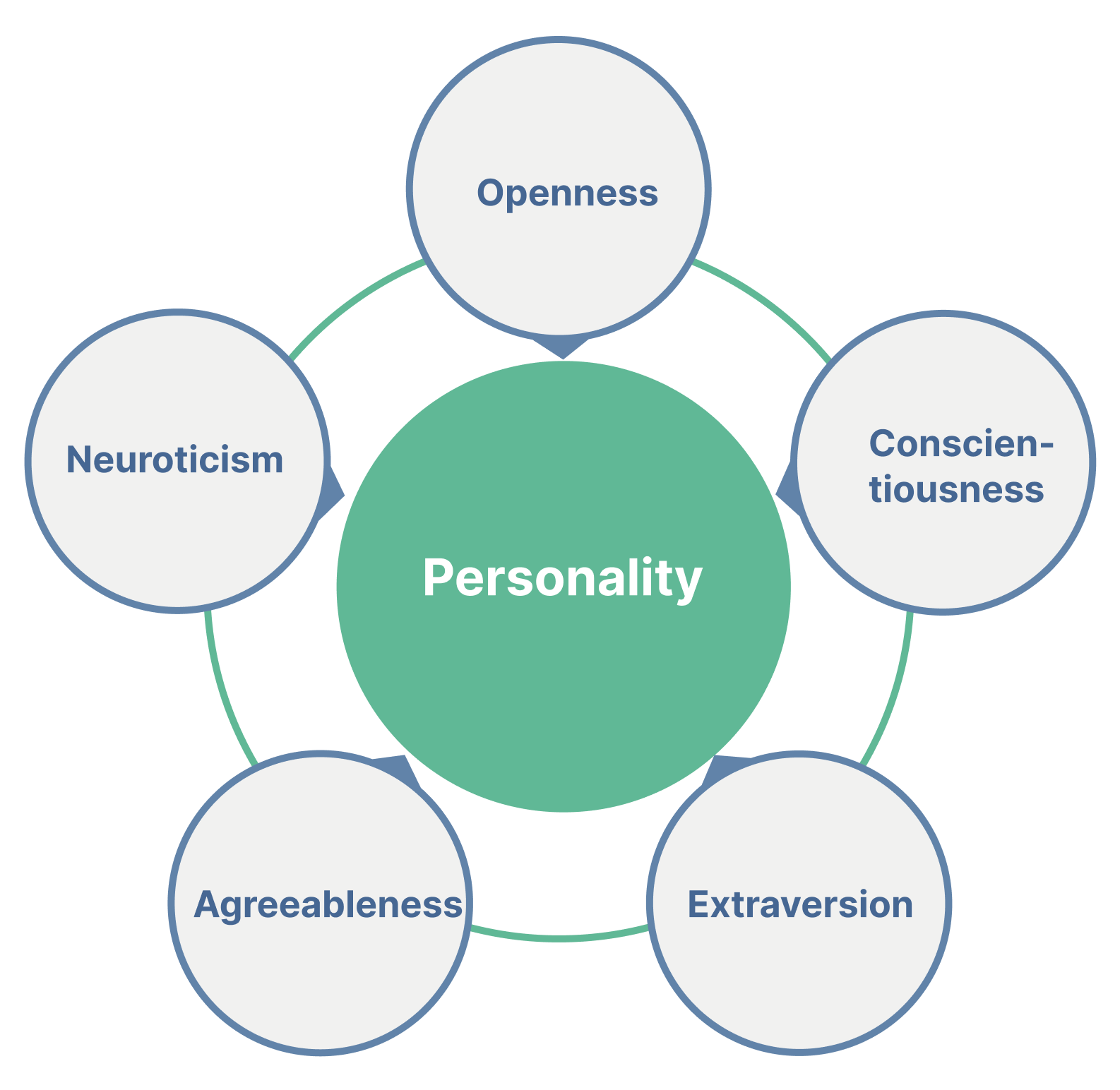
Данные собирались с помощью опросника Big-Five Factor Markers. На измерение каждого фактора в опроснике отведено по десять утверждений — с этими переменными мы будем работать:
EXT1–EXT10— extraversionEST1–EST10— neuroticism (emotional stability)AGR1–AGR10— agreeablenessCSN1–CSN10— conscientiousnessOPN1–OPN10— openness
Подробное описание датасета можно найти в этом файле.
Оригинальный датасет содержит 1 015 342 наблюдения — это очень много, возможно, не хватит оперативной памяти, поэтому мы будем работать с его частью.
#1
- Загрузите данные. Проверьте их структуру и типы переменных.
- При необходимости скорректируйте типы переменных.
- Если в данных есть пропущенные значения или они возникли в ходе предобработки, удалите их из датасета.
Для самопроверки в поле ниже введите количество пропущенных значений в датасете.
Подсказка
Не ведитесь на то, что данные те же — да, это то же исследование, но данные могут быть организованы не так, как в прошлый раз.
#2
- Постройте и визуализируйте корреляционную матрицу по интересующим нас переменным (пунктам опросника).
- Что происходит в данных? Нужно ли что-либо поправить?
- Предобработайте данные, если это необходимо.
Описание формата инпута.
Подсказка
Обратите внимание на силу корреляций, а также на их направление.
#3
Постройте базовую модель КФА (model1), соответствующую структуре модели Big Five.
При описании структуры модели для обозначения факторов используйте сокращения AGR, CSN, EST, EXT и OPN.
Для самопроверки в поле ниже введите число степеней свободы модели (Degrees of freedom) из аутпута функции summary().
Подсказки
Чтобы построить модель, необходимо:
- задать структуру модели в виде строки с использованием операторов
=~,~~и+— удобнее сохранить её в какую-либо переменную - с помощью функции
cfa()из пакетаlavaanпостроить модель, указав структуру модели и данные, на которых будут подобны её параметры - в структуре модели Big Five есть только пять латентных переменных первого уровня (личностных черт), латентные переменные второго уровня отсутствуют
- при отсутствии латентных переменных второго уровня корреляция между факторами первого уровня функцией
cfa()по умолчанию включаются в модель
#4
Рассчитайте значение метрик качества модели. Помимо основных — CFI, TLI, SRMR, RMSEA — можете выбрать любые, которые считаете необходимыми.
Сделайте вывод о качестве модели и её соответствии данным.
Для самопроверки в поле ниже введите значение RMSEA, округленное до тысячных. В качестве десятичного разделителя используйте точку.
Подсказки
- Значения метрик качества модели можно получить с помощью функции
fitmeasures(), во втором аргументе которой необходимо перечислить требуемые метрики в виде текстового вектора, если вы хотите сократить аутпут. - Для оценки качества модели можете использовать стандартные пороговые значения:
- для CFI и TLI — 0.95
- для SRMR и RMSEA — 0.05
#5
- Приведите результаты моделирования к стандартизированному виду.
- Изучите оценки параметров модели. Сделайте вывод о том, удалось ли обнаружить ожидаемую структуру в данных.
Для самопроверки в модели ниже введите количество факторных нагрузок, которые оказались статистически незначимы.
Подсказки
- Привести аутпут к стандартизированному виду поможет функция
standardizedsolution(). - Эта функция возвращает датафрейм, с которым можно взаимодействовать как с любым датафреймом.
- Для удобства можете отдельно изучить факторные нагрузки, отдельно корреляции и отдельно — остатки модели.
#6
Окей. Давайте выдвинем предположение, что всё-таки за пятью факторами скрывается единый фактор — назовём его Personality. Хотя это не очень согласуется с тем, как была теоретически сформулирована модель, попробуем оценить, получается ли более хорошей модель с G-фактором на имеющихся данных.
Постройте модель КФА (model2), в которой латентными переменными первого уровня будут пять личностных черт модели Big Five, а латентной переменной второго уровня — фактор Personality.
При описании структуры модели для обозначения факторов используйте сокращения AGR, CSN, EST, EXT, OPN и PER (для Personality).
Для самопроверки в поле ниже введите число степеней свободы модели (Degrees of freedom) из аутпута функции summary().
Подсказки
Чтобы построить модель, необходимо:
- задать структуру модели в виде строки с использованием операторов
=~,~~и+— удобнее сохранить её в какую-либо переменную - фактор второго уровня вводится в модель аналогично тому, как вводились факторы первого уровня, однако теперь в качестве «наблюдаемых» переменных выступают факторы первого уровня
- с помощью функции
cfa()из пакетаlavaanпостроить модель, указав структуру модели и данные, на которых будут подобны её параметры - при наличии латентных переменных второго уровня корреляция между факторами первого уровня функцией
cfa()в модель не включаются
#7
Сравните модели model1 и model2 друг с другом с помощью метрик качества модели.
Какая из моделей лучше соответствует данным?
Для самопроверки в поле ниже введите абсолютную разницу между значениями индекса CFI двух моделей, округленную до тысячных. В качестве десятичного разделителя используйте точку.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#8
Изучите индексы модификации модели. Прежде всего интересно узнать, не потеряла ли модель что-то важное, когда из неё были удалены корреляции между личностными чертами.
Выведите индексы модификации для корреляций между факторами первого уровня. Стоит ли включить эти корреляции в модель?
Для самопроверки в поле ниже введите значение наименьшего индекса модификации, округленное до тысячных. В качестве десятичного разделителя используйте точку.
Подсказки
Чтобы отобрать необходимые индексы модификации, необходимо осуществить фильтрацию датафрейма по следующим условиям:
- в колонках
lhsиrhsдолжны быть разные значения - в колонках
lhsиrhsзначения не должны заканчиваться на цифру
#9
- На основании результатов предыдущего задания скорректируйте модель
model2, включив в неё те корреляции, которые могли бы существенно улучшить модель. Постройте модельmodel3. - Сравните три модели (
model1,model2иmodel3) друг с другом с помощью метрик качества модели.
Какая из моделей лучше соответствует данным?
Описание формата инпута.
Подсказки
Как делать задание?
Что надо сделать?
Ответ неверный
#10
Сравните три модели (model1, model2 и model3) друг с другом с помощью теста \(\chi^2\).
Стоит ли включать в модель латентную переменную второго уровня? Что важнее учесть в модели — G-factor (Personality) или корреляции между факторами (личностными чертами)?
Описание формата инпута.