[1] 1 3 4 6 4 2 4 3 2 4 13 Меры центральной тенденции
Мы знаем, что наши переменные-признаки могут быть некоторым образом распределены — как в генеральной совокупности, так и в выборке. Как именно они распределены, описывается распределением случайной величины.
Вот мы собрали некоторые данные и получили какое-то эмпирическое распределение наших переменных. Нам бы, конечно, хотелось понять, что там такое за распределение. И первым шагом к пониманию этого будет описание распределения.
3.1 Виды статистики
Вообще статистика [как набор методов и инструментов] делится на два вида:
- Описательная статистика (descriptive statistics1) занимается обработкой статистических данных, их наглядным представлением, и собственно описанием через некоторые характеристики.
- Эти характеристики, количественно описывающие особенности имеющихся данных, называются описательными статистиками (descriptive statistics2).
- Задача описательной статистики — ёмко описать имеющиеся данные и составить на основе этих описаний общее представление о них, а также обнаружить особенности, которые могут повлиять на дальнейший анализ.
- Статистика вывода (inferential statistics) занимается поиском ответов на содержательные вопросы, которые мы задаем данным в ходе их анализа в рамках научных и практических исследований.
- Состоит из двух компонентов — тестирования статистических гипотез и статистических методов.
Замечание о машинном обучении
Вы наверняка не раз слышали словосочетание «машинное обучение». Это что-то, что время от времени становится то менее, то более хайпово. На самом деле, статистические методы лежат где-то между статистикой вывода и машинным обучением.
Почему?
Дело в том, что на статистические методы можно смотреть по-разному.
- Если нашей задачей является поиск ответов на исследовательские вопросы о закономерностях, о связи каких-либо факторов или влиянии переменных друг на друга, то мы будем смотреть на статистические модели с точки зрения статистики вывода. Это позволит нам находить ответы на интересующие нас вопросы — причем не важно, говорим мы о научных исследованиях или об исследованиях в индустрии.
- Если перед нами стоит задача хорошо предсказывать одни переменные на основании значений других — например, выдавать рекомендации на Яндекс Музыке или в Яндекс Лавке — то мы будем смотреть на те же статистические модели с точки зрения машинного обучения.
То есть, модели абсолютно одни и те же, но то, какую модель мы назовем хорошей и как мы эту «хорошесть» определим, будет различаться в зависимости от задачи — исследовательская или предиктивная — которая перед нами стоит.
Мы начнем знакомиться со статистикой с описательной статистики, а именно с мер центральной тенденции.
3.2 Меры центральной тенденции
Итак, мы хотим описать наши данные. Точнее, распределения переменных, которые у нас в данных есть. Хотим мы сделать это просто и ёмко. Насколько просто и ёмко? Ну, допустим максимально — одним числом. Кажется, значение переменной, которое лежит в центре распределения, неплохо для этого подойдет.
Как мы будем искать, что там в центре распределения? Зависит от шкалы, в которой измерена конкретная переменная.
| Шкала | Мера центральной тенденции |
|---|---|
| Номинальная | Мода |
| Порядковая | Медиана |
| Интервальная | Среднее арифметическое |
| Абсолютная | Среднее арифметическое, геометрическое и др. |
Однако есть некоторые нюансы.
3.2.1 Мода
Определение 3.1 Мода (mode) — наиболее часто встречающееся значение данной переменной.
Тут все достаточно просто и интуитивно понятно. Пусть у нас есть следующий ряд наблюдений:
Если мы составим таблицу частот, то получим следующее:
x
1 2 3 4 6
2 2 2 4 1 Очевидно, что \(4\) встречается чаще других значений — это и есть мода.
Понятно, что если на нашей шкале нет чисел, а есть текстовые лейблы, это ничего не меняет:
[1] "Москва" "Казань"
[3] "Кёнигсберг" "Барнаул (Алтайский край)"
[5] "Москва" "Санкт-Петербург"
[7] "Санкт-Петербург" "Москва"
[9] "Санкт-Петербург" "Москва"
[11] "Кёнигсберг" "Санкт-Петербург"
[13] "Москва" "Казань"
[15] "Санкт-Петербург" "Санкт-Петербург"
[17] "Казань" "Казань"
[19] "Санкт-Петербург" "Москва"
[21] "Москва" "Санкт-Петербург"
[23] "Санкт-Петербург" "Санкт-Петербург"
[25] "Санкт-Петербург" "Москва"
[27] "Кёнигсберг" "Санкт-Петербург"
[29] "Казань" y
Барнаул (Алтайский край) Казань Кёнигсберг
1 5 3
Москва Санкт-Петербург
8 12 Мода, получается, Санкт-Петербург.
Так мы поступаем с эмпирическим распределением. Если мы имеем дело с генеральной совокупностью, то можем формально определить моду через функцию вероятности (probability mass function, PMF). Модой будет являться значение случайной величины, при котором PMF принимает своё максимальное значение.
\[ \text{mode}(X) = \arg \max \big( \text{PMF}(X) \big) \]
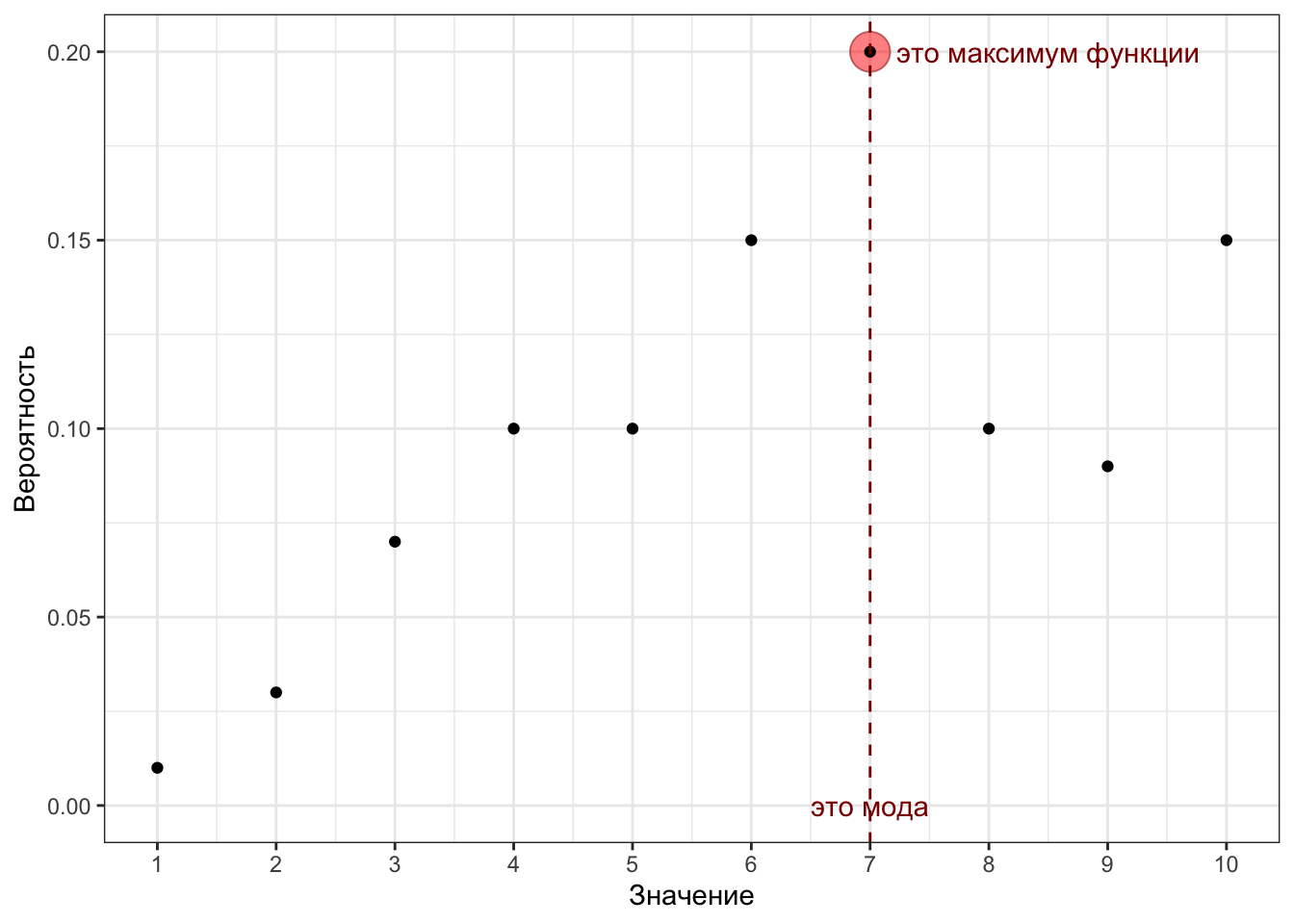
Мода — 7.
3.2.2 Медиана
Определение 3.2 Медиана (median) — значение переменной, которые располагается на середине отсортированного ряда значений.
То есть, она делит все наблюдения переменной ровно пополам, и половина наблюдений оказывается по одну сторону от медианы, а половина — по другую.
Если у нас нечетное число наблюдений, то всё ясно. Пусть есть такой ряд наблюдений:
[1] 2 3 14 9 16 19 28 7 26 18 1Отсортируем его:
[1] 1 2 3 7 9 14 16 18 19 26 28Посмотрим в середину — найдем медиану:
[1] 14А что делать, если число наблюдений чётное? Ведь тогда середина ряда будет между двух чисел. Ну, возьмем их среднее арифметическое — это и будет медиана.
Возьмём такой ряд наблюдений:
[1] 14 10 9 16 30 3 25 8 18 7Отсортируем:
[1] 3 7 8 9 10 14 16 18 25 30Найдём медиану как \((10 + 14) / 2\):
[1] 12Формально это можно написать так:
\[ \text{median}(X) = \cases{ X_{\frac{n+1}{2}}, \quad \text{if} \, n \, \text{is odd} \\ \frac{X_{\frac{n}{2}} + X_{\frac{n}{2}+1}}{2}, \quad \text{otherwise} } \]
где \(X\) — ряд наблюдений данной переменной, \(n\) — число наблюдений, \(X_i\) — наблюдение с индексом \(i\) в сортированном векторе \(X\).
3.2.3 Среднее арифметическое
С этим существом все знакомы еще со школы.
Определение 3.3 Арифметическое среднее (arithmetic mean, mean, average) — сумма всех значений переменной, делёная на их количество.
Иначе говоря:
\[ M(X) = \overline{X} = \frac{1}{n} \sum_{i=1}^n x_i \]
где \(\overline X\) — среднее арифметическое, \(x_i\) — наблюдение в векторе \(X\), \(n\) — количество наблюдений.
Ну, то есть всё сложить и поделить на количество того, чего сложили. Изи.
Вот, скажем, средние по двум рядам наблюдений, которые мы встречали в разделе про медиану:
[1] 2 3 14 9 16 19 28 7 26 18 1[1] 13 [1] 14 10 9 16 30 3 25 8 18 7[1] 143.2.4 Среднее взвешенное
Часто возникает такая ситуация, когда нам нужно посчитать среднее по каким-либо имеющимся характеристикам, но одни характеристики для нас важнее, чем другие. Например, мы хотим вычислить суммарный балл обучающегося за курс на основе ряда работ, выполненных в течение курса. Мы могли бы взять оценки за все работы и усреднить их. Однако мы понимаем, что, скажем, тест из десяти вопросов с множественным выбором явно менее показателен, чем, например, аналитическое эссе или экзаменационная оценка. Что делать? Взвесить параметры!
Что значит взвесить? Умножить на некоторое число. На самом деле, любое. Пусть мы посчитали, что написать эссе в три абстрактных раза тяжелее, чем написать тест, а сдать экзамен в два раза тяжелее, чем написать эссе. Тогда мы можем присвоить баллу за тест вес \(1\), баллу за аналитическое эссе вес \(3\), а экзамену — вес \(6\). Тогда итоговая оценка за курс будет рассчитываться следующим образом:
\[ \text{final score} = 1 \cdot \text{test} + 3 \cdot \text{essay} + 6 \cdot \text{exam} \]
Суперкласс. Однако! Весьма вероятно, что в учебном заведении принята единая система оценивания для всех видов работ — ну, скажем, некая абстрактная десятибалльная система в сферическом вакууме. Получается, если и за тест, и за эссе, и за экзамен у студента по 10 баллов, то суммарный балл 100, что, кажется, больше, чем 10. Чтобы вернуться к изначальным границам баллов, нужно поделить суммарный балл на сумму весов параметров:
\[ \text{final score} = \frac{1 \cdot \text{test} + 3 \cdot \text{essay} + 6 \cdot \text{exam}} {1 + 3 + 6} \]
Кайф! Собственно, это и есть взвешенное среднее. Коэффициенты, на которые мы умножаем значения переменных, называются весами. В общем виде формула принимает следующий вид:
\[ \overline X = \frac{\sum_{i=1}^n w_i \cdot x_i}{\sum_{i=1}^n w_i}, \]
где \(x_i\) — значения переменной, \(w_i\) — веса для этих значений.
Взвешенное среднее часто применяется именно во всякого рода ассессментах, и не только образовательных. Например, вы HR-аналитик и оцениваете персонал. Вы аналитически вычисляете веса коэффициентов (допустим, с помощью линейной регрессии), а далее на их основе высчитываете интегральный балл, по которому будете оценивать сотрудников. Это как один из индустриальных примеров.
3.2.5 Другие средние
Среднее бывает не только арифметическое. Правда встретятся вам другие его виды примерно нигде — то есть о-о-о-очень редко и, скорее всего, в каких-то узкоспециализированных статьях. Но упомянуть их, пожалуй, стоит как минимум ради того, чтобы вы не перепугались излишне, ежели вдруг с ними столкнётесь.
3.2.5.1 Квадратичное среднее
Это весьма полезная вещь.
Определение 3.4 Квадратичное среднее (quadratic mean, root mean square, RMS) — это квадратный корень из среднего квадрата наблюдений.
Ничего не понятно, поэтому по порядку:
- есть наблюдение \(x_i\)
- значит есть и его квадрат \(x_i^2\)
- мы умеем считать обычно среднее арифметическое
- но ведь \(x_i^2\) — это тоже наблюдение (число), просто в квадрате
- значит можем посчитать среднее арифметическое квадратов наблюдений — средний квадрат (mean square) — \(\displaystyle \frac{1}{n} \sum_{i=1}^n x_i^2\)
- теперь извлечём из этого дела корень, чтобы вернуться к исходным единицам измерения — получим то, что нам надо
\[ \text{RMS}(X) = \sqrt{\frac{1}{n} \sum_{i=1}^n x_i^2} \]
Per se3 мы его вряд ли ещё когда-то увидим, но пару раз оно внезапно всплывет.
3.2.5.2 Геометрическое среднее
В психологии и социальных науках встречается редко. Применяется там, где необходимо изучать средние скорости изменения — например, в экономике и финансах при изучении доходности, прибыли и выручки; в демографии при расчете индекса человеческого потенциала и др.
\[ G(X) = \sqrt[n]{\prod_{i=1}^n x_i} \]
3.2.5.3 Гармоническое
Весьма экзотическая конструкция, используемая при работе с величинами, заданными через обратные значения. Встречается в финансах и экономике, страховании, физике.
\[ H(X) = \frac{n}{\displaystyle \sum_{i=1}^n \frac{1}{x_i}} \]
3.3 Сравнение мер центральной тенденции
Сравнивать будем моду, медиану и среднее [арифметическое].
Все три статистики — мода, медиана и среднее — описывают центральную тенденцию — значение изучаемой нами переменной, вокруг которого собираются другие значения. Но если их три и все они используются, значит между ними должны быть какие-то различия. Посмотрим, какие.
3.3.1 Меры центральной тенденции и типы переменных
- Во-первых, очевидно, что моду невозможно посчитать для непрерывной переменной.
- Во-вторых, медиану нельзя посчитать на номинальной шкале. Кстати, почему?
- В-третьих, среднее тоже нельзя посчитать на номинальной шкале.
- В-четвертых, для дискретной переменной значение среднего арифметического будет не особо осмысленно. Ну, скажем, странно сказать, что в аудитории в среднем стоят 15.86 столов или в российских семьях в среднем 1.5 ребенка. Конечно, в ряде случаев можно это как-то более-менее содержательно интерпретировать, но это требует усилий, а мы ленивые, поэтому лучше использовать медиану.
Итого, делаем следующие выводы
- для номинальной шкалы пригодна только мода
- для дискретных переменных подходят мода и медиана
- мода иногда лучше, так как точно всегда будет целым числом
- для непрерывных переменных подходят медиана и среднее
3.3.2 Меры центральной тенденции и форма распределения
Помимо того, что среднее, мода и медиана информативны сами по себе, полезно смотреть на их взаимное расположение.
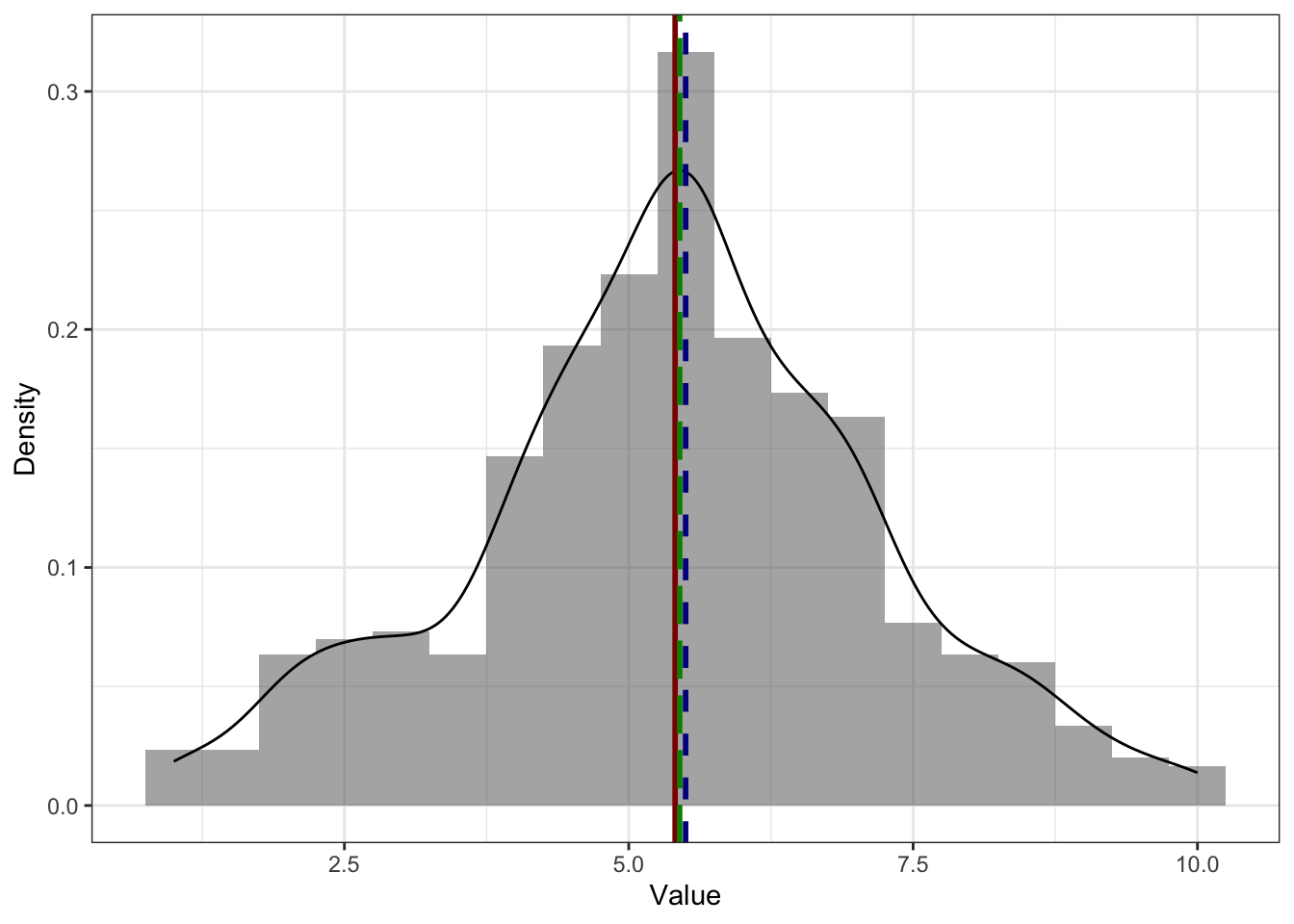
- На симметричном распределении мода, медиана и среднее совпадают [или, по крайней мере, находятся очень близко друг к другу].
Здесь и далее: красная (сплошная) линия — среднее, синяя (короткопунктирная) — медиана, зелёная (длиннопунктирная) — мода.
- На асимметричном распределении мода [практически] в пи́ке
.Практически, потому что мода для непрерывной переменной определена по функции плотности вероятности [черная линия на графике], которая не всегда точно аппроксимирует (в данном случае то же, что и сглаживает) эмпирическое распределение. На картинке ниже мы видим, что по гистограмме мода должна была бы быть в районе самого высокго столбика, однако при сглаживании гистограммы пик немного съехал, и мода оказалась в вершине графика функции плотности вероятности.
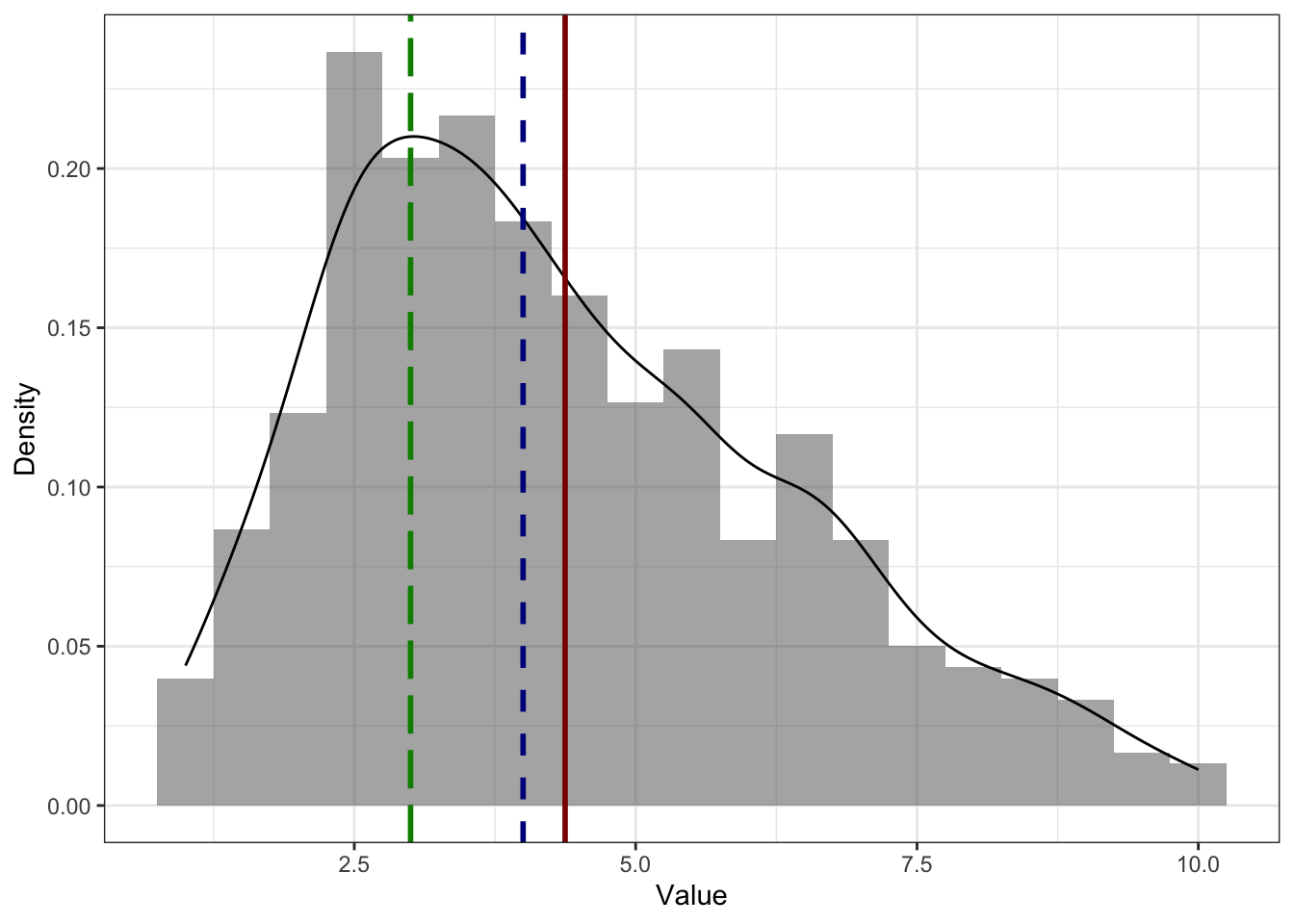
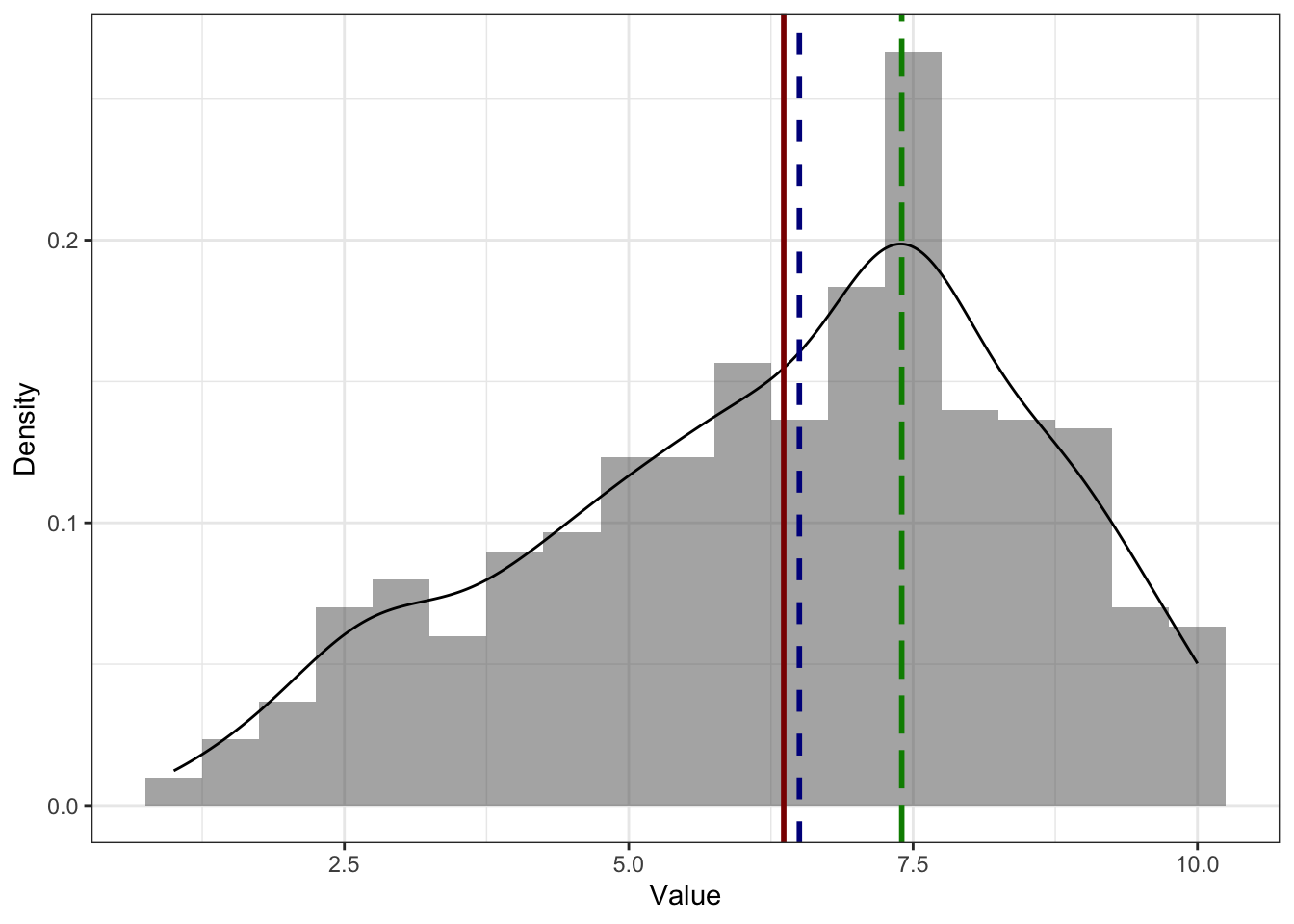
- На асимметричном распределении медиана и среднее смещены в сторону хвоста. Среднее смещено сильнее медианы.
Это связано с тем, что медиана зависит только от количества наблюдений, а среднее — ещё и от самих значений. На картинках выше примеры для распределения с правосторонней асимметрией (потому что хвост справа) — среднее (красная линия) правее медианы (синяя линия) — и левосторонней асимметрией (так как хвост слева) — среднее (красная линия) левее медианы (синяя линия).
Для того, чтобы лучше разобраться с тем, как экстремальные значения влияют на моду и медиану посмотрим такой пример. Пусть у нас есть оценки за выпускную квалификационную работу. Например, такие:
[1] 6 7 7 8 8Среднее — 7.2, медиана — 7. Если округлить среднее, то можно считать, что среднее и медиана совпали. Ну, ок.
Но в комиссии сидят ещё два требовательных доктора наук, которые поставили оценки, сильно отличающиеся от остальных:
[1] 6 7 7 8 8 3 4Посчитаем медиану и среднее теперь. Среднее — 6.1428571, медиана — 7. Медиана осталась на месте, а вот среднее теперь округлится до 6. Казалось бы, это немного, но в смысле оценок — это прилично, и может сильно повлиять на GPA.
Итого, среднее более чувствительно к нетипичным значениям (очень большим или очень малым).
Есть ещё один интересный вариант распределений — бимодальные. Посмотрим пример ниже:
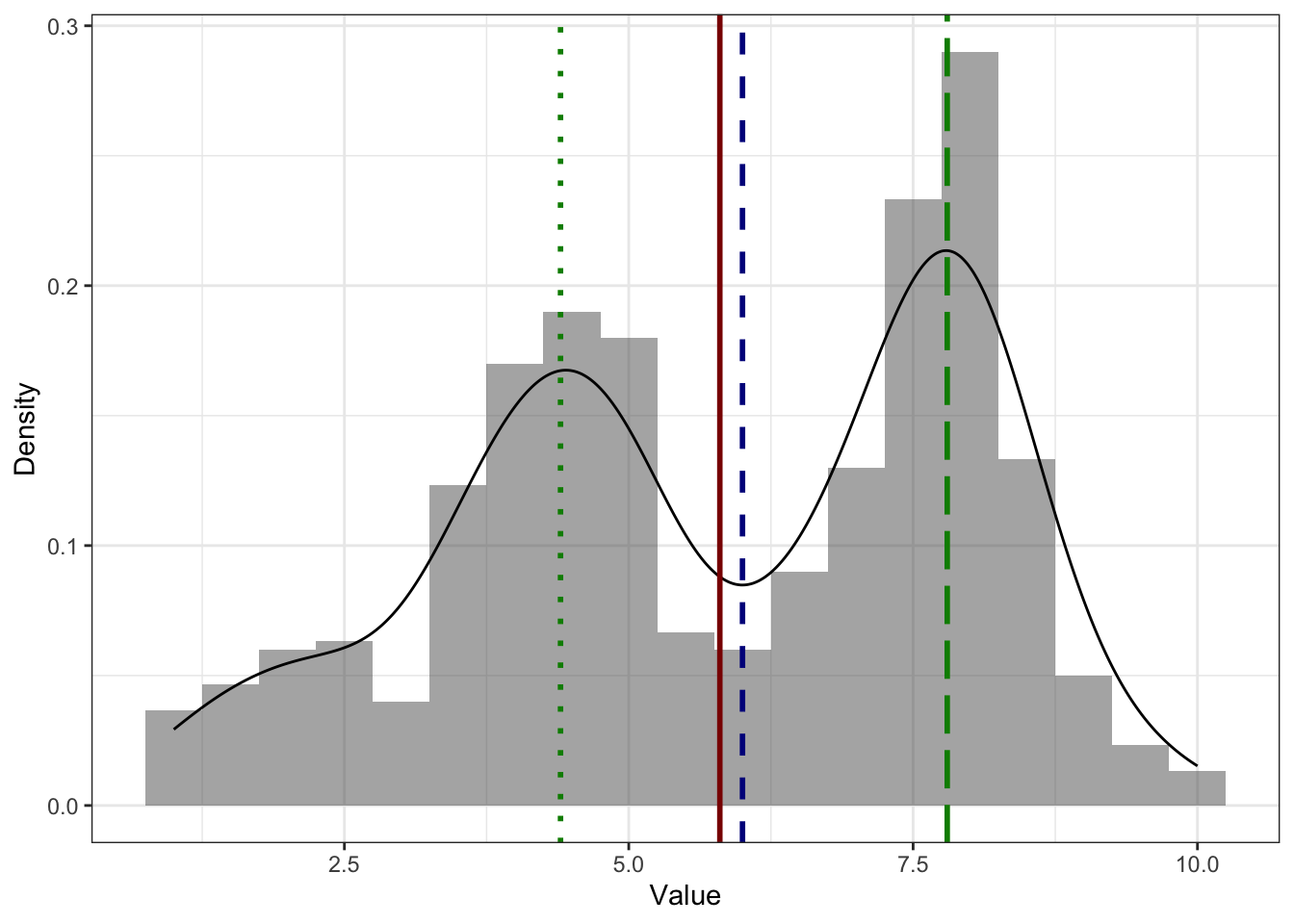
Мы видим, что на графике есть два пика, однако строго математически мода всё же одна (зелёная пунктирная линия) — и она в более высоком пике. Это логично, ибо там самые часто встречающиеся (самые вероятные) значения.
И все жё содержательно мы не можем пренебречь вторым пиком (зелёная точечная линия). Почему он нам важен? Обычно бимодальное распределение — это повод задуматься о том, что наша выборка неоднородна. Бимодальное распределение как бы сложено из двух с центрами в двух пиках. Иначе говоря, в нашей выборке как будто бы две подвыборки, которые обладают разными распределениями интересующего нам признака.
Что с этим делать? Хорошо всегда иметь в данных какие-либо дополнительные переменные — как минимум соцдем — чтобы мы могли по данным попытаться предположить, какую группировку мы могли забыть учесть при планировании исследования.
Со средним и медианой в случае бимодального распределения происходит примерно то же, что и в случае асимметричного распределения — второй пик смещает к себе обе меры центральной тенденции, причем среднее вновь сильнее, чем медиану.
3.4 Свойства среднего арифметического
Мы упомянем три основных свойства, к которым будем обращаться в последующих темах.
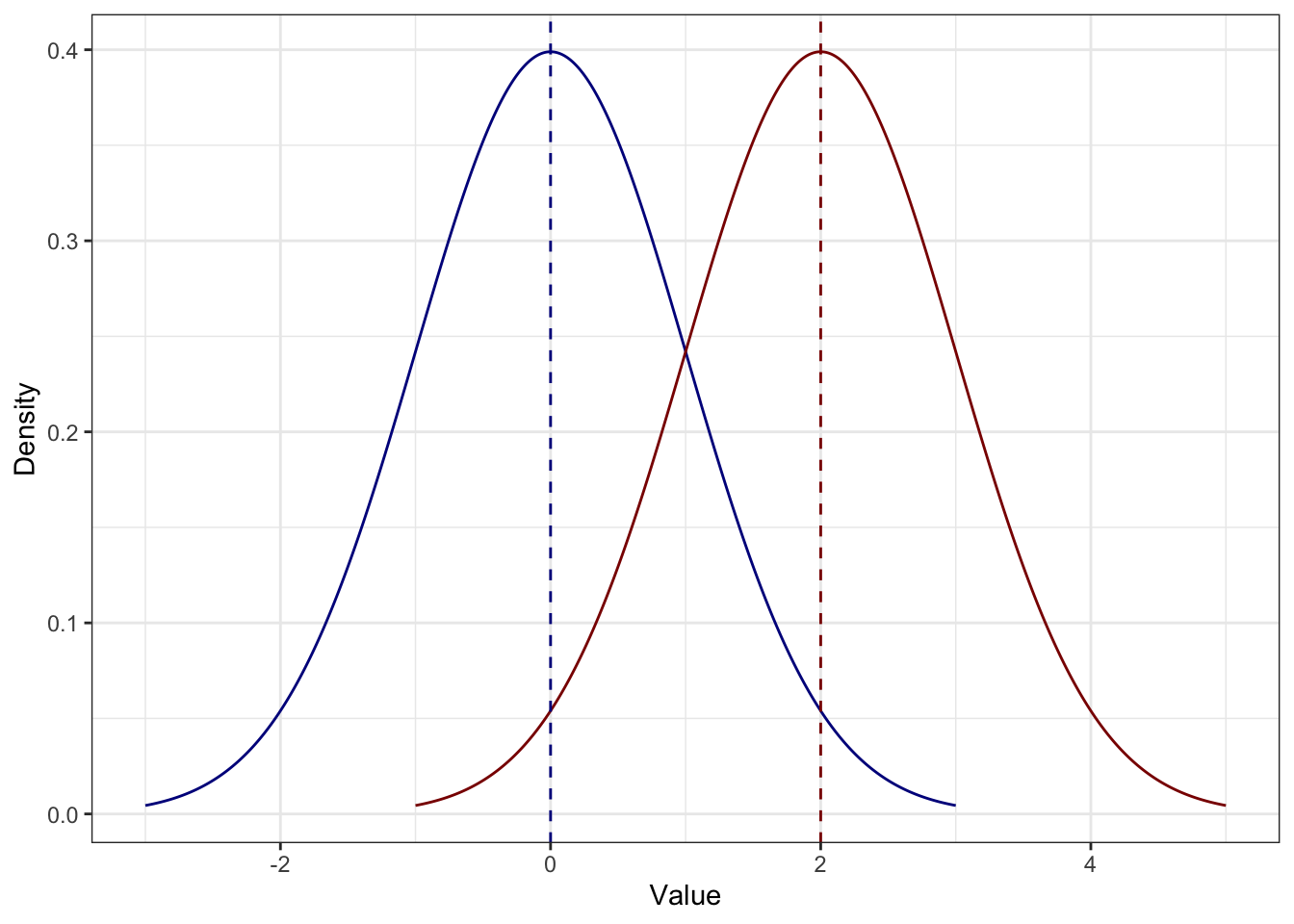
Утверждение 3.1 Если к каждому значению распределения прибавить некоторое число (константу), то среднее изменится на ту же константу.
\[ M_{X+c} = M_X + c \]
Доказательство. \[ \begin{split} M_{X+c} &= \frac{\sum_{i=1}^n (x_i + c)}{n} = \\ &= \frac{\sum_{i=1}^n x_i + nc}{n} = \\ &= \frac{\sum_{i=1}^n x_i}{n} + c = M_X + c \end{split} \]
Иначе говоря, распределение просто сдвинется. Например, если к каждому значению синего распределения прибавить \(2\), получится красное:
Утверждение 3.2 Если каждое значение распределения умножить на некоторое число (константу), то среднее изменится во столько же раз.
\[ M_{X \times c} = M_X \times c \]
Доказательство. \[ \begin{split} M_{X \times c} &= \frac{\sum_{i=1}^n (x_i \times c)}{n} = \\ &= \frac{c \times \sum_{i=1}^n x_i}{n} = \\ &= \frac{\sum_{i=1}^n x_i}{n} \times c = M_X \times c \end{split} \]
Например, здесь каждое значение синего распределения умножили на \(3\) и получили красное:
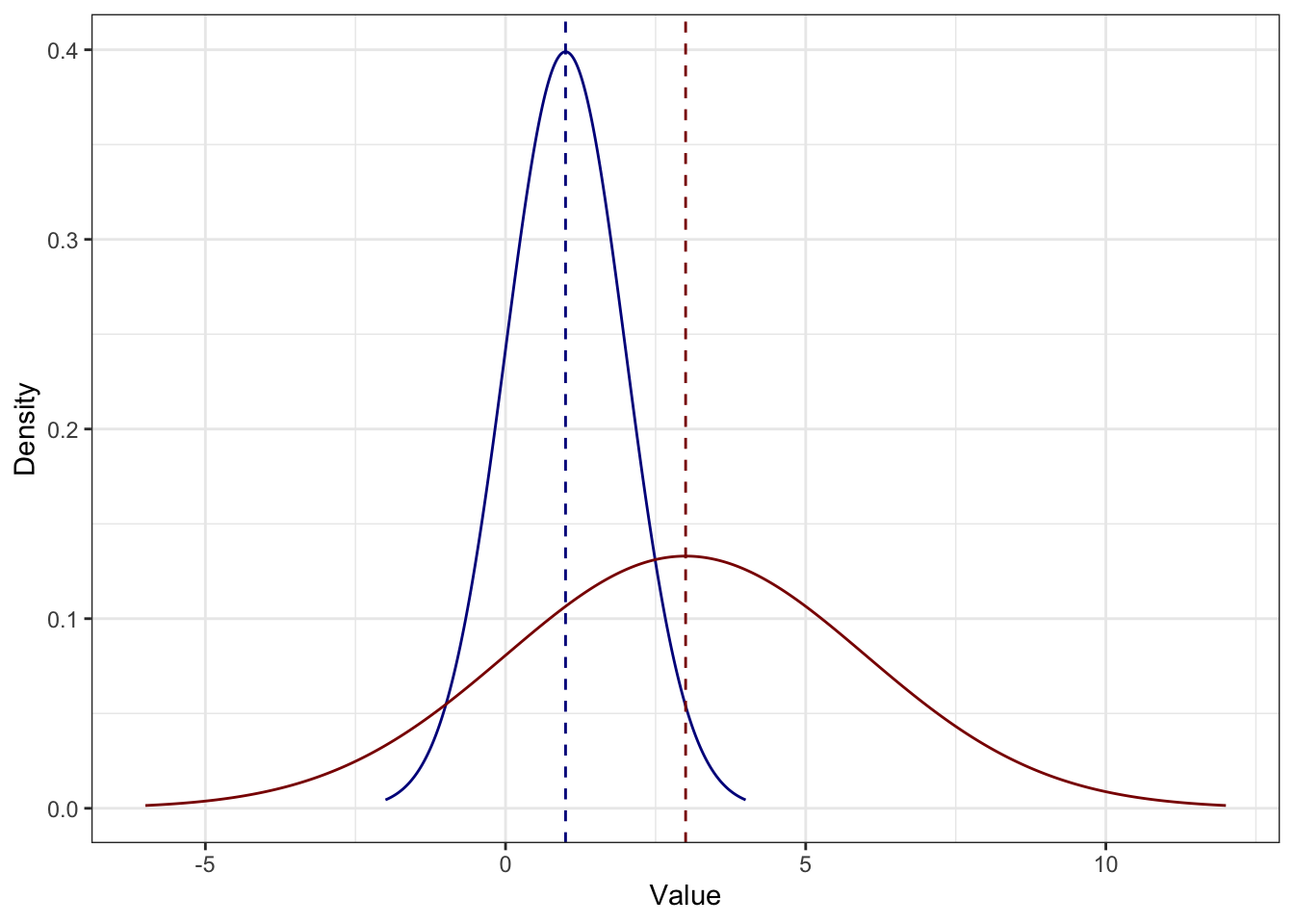
Тут, правда, явно что-то ещё произошло, но мы пока этого не знаем.
Утверждение 3.3 Сумма отклонений от среднего значения равна нулю.
\[ \sum_{i=1}^n(x_i - M_X) = 0 \]
Доказательство. \[ \begin{split} \sum_{i=1}^n(x_i - M_X) &= \sum_{i=1}^n x_i - \sum_{i=1}^n M_X = \\ & = \sum_{i=1}^n x_i - nM_X = \\ & = \sum_{i=1}^n x_i - n \times \frac{1}{n} \sum_{i=1}^n x_i = \\ &= \sum_{i=1}^n x_i - \sum_{i=1}^n x_i = 0 \end{split} \]
Но можно это осмыслить и более просто графически.
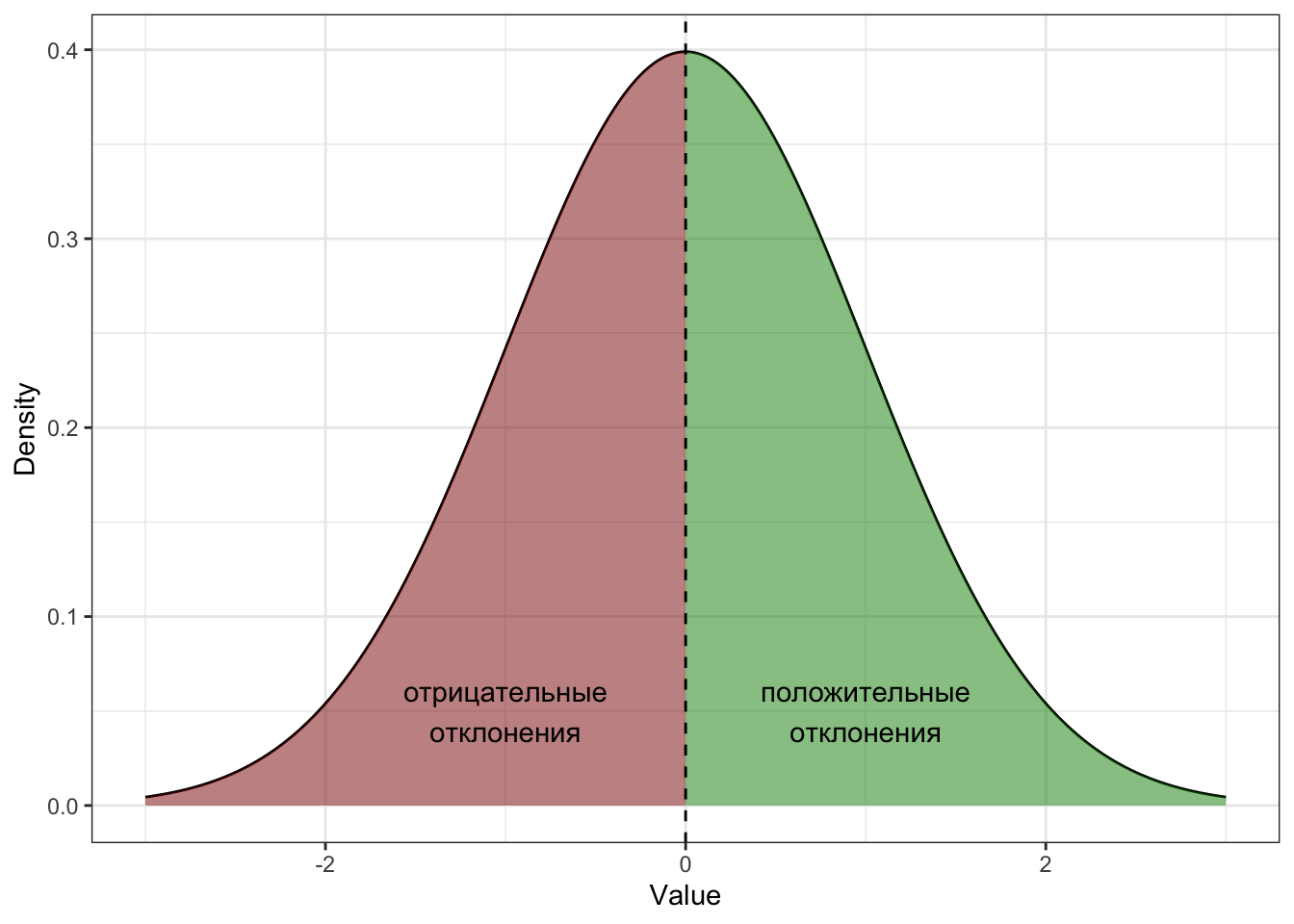
Определение 3.5 Отклонение — это разность между конкретным значением переменной и средним по этой переменной.
\[ d_i = \overline X - x_i \]
И, действительно, так как среднее находится в центре распределения, то часть значений лежит справа, а часть слева. Значит, будут как положительные, так и отрицательные отклонения — и их сумма в итоге будет равна нулю.