8 Анализ категориальных данных
Сегодня мы изучим первый статистический метод, который применяется при анализе категориальных данных. Напомню, что категориальные данные — это те, которые измерены в номинальной (реже — порядковой) шкале. А раз они измерены в номинальной шкале, значит наши данные разбиваются на некоторые категории (группы). А раз есть категории, значит можно посчитать их частоты. А раз можно посчитать частоты, значит можно построить таблицу частот.
8.1 Анализ таблиц сопряженности
Таблицы частот для одной переменной мы с вами строили, когда обсуждали меры центральной тенденции, а именно моду. Однако теперь нас интересует не одна переменная, а две — мы будем искать связь между двумя категориальными переменными.
Давайте на примере. Пусть у нас есть данные о том, как студенты некоторого курса сдали экзамен по анализу данных. Экзамен проходил во вторник. При этом известно, что одна часть студентов усиленно готовилась к экзамену, а другая часть — отмечала понедельник в барах на Китай-городе.
В цифрах:
- всего студентов на курсе 120 человек
- успешно сдали экзамен 94 студента
- готовились к экзамену 86 студентов
- готовились и не сдали экзамен 3 студента
По этим данным мы можем построить таблицу сопряженности (contingency table, cross tabulation, crosstab) (Таблица 8.1).
| Сдали экзамен | Не сдали экзамен | |
|---|---|---|
| Готовились | \(83\) | \(3\) |
| Отмечали понедельник | \(11\) | \(23\) |
Эта таблица отображаем совместное распределение респондентов по двум категориальным переменным. Так как каждая переменная является бинарной, то есть принимает только два возможных значения, то всего ячеек в таблице четыре. Возможно, не вполне понятно, почему в каждой из ячеек такие значения — давайте дополним таблицу ещё одной колонкой и ещё одной строкой (Таблица 8.2).
| Сдали экзамен | Не сдали экзамен | Всего по строкам | |
|---|---|---|---|
| Готовились | \(83\) | \(3\) | \(86\) |
| Отмечали понедельник | \(11\) | \(23\) | \(34\) |
| Всего по столбкам | \(94\) | \(26\) | \(120\) |
Здесь к исходной таблице добавлены маргинальные частоты (те, что «стоят на краю таблицы»), отображающие суммы частот по строкам и столбцам. Можно также дать общий вид такой таблицы, так как строиться она всегда будет по одному и тому же алгоритму (Таблица 8.3), при этом с использованием введённых в таблица обозначений необходимо отметить, что маргинальные частоты (\(n_{1\bullet}\), \(n_{2\bullet}\), \(n_{\bullet1}\), \(n_{\bullet2}\)) и общее количество наблюдений (\(n_{\bullet \bullet}\)) определяются следующим образом:
\[ \begin{aligned} & n_{1\bullet} = n_{11}+n_{12} \\ & n_{2\bullet} = n_{21} + n_{22} \\ & n_{\bullet1} = n_{11} + n_{21} \\ & n_{\bullet2} = n_{12} + n_{22} \\ & n_{\bullet\bullet} = n_{11} + n_{12} + n_{21} + n_{22} \end{aligned} \]
| \(X_2^{(1)}\) | \(X_2^{(2)}\) | \(X_1^{(\bullet)}\) | |
|---|---|---|---|
| \(X_1^{(1)}\) | \(n_{11}\) | \(n_{12}\) | \(n_{1\bullet}\) |
| \(X_1^{(2)}\) | \(n_{21}\) | \(n_{22}\) | \(n_{2\bullet}\) |
| \(X_2^{(\bullet)}\) | \(n_{\bullet1}\) | \(n_{\bullet2}\) | \(n_{\bullet \bullet}\) |
Эта таблица отражает эмпирические частоты — то есть те, которые были посчитанны на собранных нами данных. Здесь \(X_1\) и \(X_2\) — наши переменные, индексы \(^{(1)}\) и \(^{(2)}\) показывают категорию, к которой относится то или иное наблюдение. На пересечении столбца и строки — частота совместного появления признаков \(X_1^{(i)}\) и \(X_2^{(j)}\). Суммы частот по строкам и столбцам — маргинальные частоты [строк и столбцов соответственно].
Итак, эмпирические частоты у нас в наличии. Теперь вспомним алгоритм тестирования статистических гипотез:
Напоминание: алгоритм тестирования статистических гипотез
- Формулировка гипотезы
- Выбор статистического критерия
- Выбор уровня значимости \(\alpha\)
- Расчёт выборочной статистики
- Построение закона распределения статистики критерия при условии, что нулевая гипотеза верна
- Расчёт p-значения (p-value)
- Сопоставление \(\alpha\) и p-value и статистический вывод
8.1.1 Теоретические частоты
Нам нужно сформулировать нулевую гипотезу. Как мы помним, нулевая гипотеза всегда об отсутствии каких-либо различий или взаимосвязей. В нашем случае уместно будет сказать, что между переменными \(X_1\) и \(X_2\) нет связи. Однако это словесное выражение гипотезы — нам же нужно также её как-то математически оформить. Это не только простая задача, как может показаться.
Как буду вести себя совместные частоты (\(n_{11}\), \(n_{12}\), \(n_{21}\), \(n_{22}\)), если между переменными нет взаимосвязи? Интуитивно хочется сказать, что все они будут равны:
\[ n_{11} = n_{12} = n_{21} = n_{22} \]
Что ж, это вполне неплохо для нулевой гипотезы, разве что только вместо эмпирических частот нужно будет найти соответствующий параметр генеральной совокупности. Однако такой расклад будет свитедельствовать об отсутствии взаимосвязи медлу переменными только в ситуации, когда маргинальные частоты равны. Это может быть уместо при анализе экспериментальных данных со сбалансированным дизайном — но это частный случай. Нам бы всё же хотелось сформулировать гипотезу для общего случая.
Хорошо, раз мы не можем принять гипотезу о равенстве «частот», давайте попробуем посмотреть, как вели бы себя совместные частоты \(n_{11}\), \(n_{12}\), \(n_{21}\), \(n_{22}\), если между переменными \(X_1\) и \(X_2\) нет взаимосвязи и известны маргинальные частоты \(n_{1\bullet}\), \(n_{2\bullet}\), \(n_{\bullet1}\), \(n_{\bullet2}\).
Здесь нам потребуется одна мысль (Теорема 8.1) из теории вероятностей:
Теорема 8.1 Вероятность совместного появления двух независимых событий равна произведению их вероятностей.
\[ \mathbb{P} (A \cap B) = \mathbb{P} (A) \cdot \mathbb{P} (B) \]
Эмпирическим аналогом вероятности является частота, поэтому справедливо будет следущее Утверждение 8.1.
Утверждение 8.1 Относительная частота совместного появления двух независимых событий равна произведению их относительных частот.
\[ p_{A \cap B} = p_A \cdot p_B \]
Строго доказывать теорему и утверждение мы не будем, ограничимся принятием на веру справедливости теоремы и интуитивным соответствием утверждения с ней.
Как нам это поможет? Мы можем вычислить относительные частоты принадлежности наблюдений к каждой из групп по обеим переменным, то есть для нашей таблицы 8.3:
\[ \begin{aligned} & p_{1\bullet} = \dfrac{n_{1\bullet}}{n_{\bullet \bullet}} \\ & p_{2\bullet} = \dfrac{n_{2\bullet}}{n_{\bullet \bullet}} \\ & p_{\bullet1} = \dfrac{n_{\bullet1}}{n_{\bullet \bullet}} \\ & p_{\bullet2} = \dfrac{n_{\bullet2}}{n_{\bullet \bullet}} \\ \end{aligned} \]
Теперь так как нас интересует ситуация независимости двух переменных — а значит, и независимого попадания к каждую из групп по каждой переменной — отноcительная частота попадания наблюдения в группы \(p_{11}\), \(p_{12}\), \(p_{21}\) и \(p_{22}\) будет вычисляться как произведение вышеобозначенных относительных частот:
\[ \begin{aligned} & p_{11} = p_{1\bullet} \cdot p_{\bullet1} = \dfrac{n_{1\bullet} \cdot n_{\bullet1}}{n^2_{\bullet \bullet}} \\ & p_{12} = p_{1\bullet} \cdot p_{\bullet2} = \dfrac{n_{1\bullet} \cdot n_{\bullet2}}{n^2_{\bullet \bullet}} \\ & p_{21} = p_{2\bullet} \cdot p_{\bullet1} = \dfrac{n_{2\bullet} \cdot n_{\bullet1}}{n^2_{\bullet \bullet}} \\ & p_{22} = p_{2\bullet} \cdot p_{\bullet2} = \dfrac{n_{2\bullet} \cdot n_{\bullet2}}{n^2_{\bullet \bullet}} \\ \end{aligned} \]
Это почти то, что нам нужно! Вот только в таблице сопряженности у нас фигурируют не относительные частоты, а абсолютные — то есть штуки. Но это легко поправить — нам всего лишь нужно умножить относительную частоту на общее число наблюдений. Таким образом, мы получаем общую формулу для теоретических частот:
\[ n^{(\mathrm t)}_{ij} = \frac{n_{i \bullet} \cdot n_{\bullet j}}{n_{\bullet \bullet}} \]
Таблица теоретических частот принимает следующий вид (Таблица 8.4).
| \(X_2^{(1)}\) | \(X_2^{(2)}\) | \(X_1^{(\bullet)}\) | |
|---|---|---|---|
| \(X_1^{(1)}\) | \(n^{(\mathrm t)}_{11} = \dfrac{n_{1 \bullet} \cdot n_{\bullet 1}}{n_{\bullet \bullet}}\) | \(n^{(\mathrm t)}_{12} = \dfrac{n_{1 \bullet} \cdot n_{\bullet 2}}{n_{\bullet \bullet}}\) | \(n_{1\bullet}\) |
| \(X_1^{(2)}\) | \(n^{(\mathrm t)}_{21} = \dfrac{n_{2 \bullet} \cdot n_{\bullet 1}}{n_{\bullet \bullet}}\) | \(n^{(\mathrm t)}_{22} = \dfrac{n_{2 \bullet} \cdot n_{\bullet 2}}{n_{\bullet \bullet}}\) | \(n_{2\bullet}\) |
| \(X_2^{(\bullet)}\) | \(n_{\bullet1}\) | \(n_{\bullet2}\) | \(n_{\bullet \bullet}\) |
Обратим внимание на то, какого результата мы добились:
- мы получили возможность рассчитать теоретические частоты
- исходя из того, что между переменными нет взаимосвязи
- на основе известных (любых) маргинальных вероятностей.
Рассчитаем для примера таблицу теоретических частот, соответствующую данным из таблицы 8.5:
| Сдали экзамен | Не сдали экзамен | Всего по строкам | |
|---|---|---|---|
| Готовились | \(\dfrac{86 \cdot 94}{120} = 67.37\) | \(\dfrac{86 \cdot 26}{120} = 18.63\) | \(86\) |
| Отмечали понедельник | \(\dfrac{34 \cdot 94}{120} = 26.63\) | \(\dfrac{34 \cdot 26}{120} = 7.37\) | \(34\) |
| Всего по столбцам | \(94\) | \(26\) | \(120\) |
Эта таблица нам будет необходима для проверки статистической гипотезы.
Однако мы в творческом порыве как будто бы отвлеклись от главного — мы собирались формулировать нулеву гипотезу. На самом деле, нет, не отвлеклись. Теперь мы гововы её-таки сформулировать.
Поскольку статистическая гипотеза должна содержать параметры генеральной совокупности, значит мы будем формулировать гипотезу про совместную вероятность — популяционный аналог совместной частоты. Эта вероятность при справедливости нулевой гипотезы должна вести себя соответственно случаю независимости событий. Итого, получаем, что
\[ \begin{aligned} & H_0: \pi_{ij} = \pi_{i \bullet} \cdot \pi_{\bullet j} \\ & H_1: \exists (i, j): \pi_{ij} \neq \pi_{i \bullet} \cdot \pi_{\bullet j} \end{aligned} \]
Что ж, о, ура! Гипотеза наконец сформулирована. Время переходить к выбору статистического критерия.
8.1.2 Критерий независимости Пирсона
Для тестирование заявленной гипотезы подходит критерий независимости Пирсона (Pearson’s Chi-squared test). Как у любого статистического критерия, у него есть статистика критерия, которая вычисляется следующим образом:
\[ \chi^2 = \sum_{i=1}^k \sum_{j=1}^l \frac{(n_{ij} - n_{ij}^{(\text{t})}) ^2 }{n_{ij}^{(t)}} \overset{H_0}{\thicksim} \chi^2 (\text{df}), \,\, \text{df} = (r-1)(c-1) \] где \(\chi^2\) — значение статистики критерия, \(n_{ij}\) — эмпирическая совместная частота, \(n_{ij}^{(\text{t})}\) — теоретическая совместная частота, \(\chi^2(\text{df})\) — распределение \(\chi^2\) с параметром \(\text{df}\) (степени свободы), \(r\) — число строк в таблице сопряженности, \(c\) — число столбцов в таблице сопряженности.
По сути формула нам позволяет сравнить, насколько эмпирические частоты отклоняются от теоретических — рассчитанных для случая, когда между переменными нет взаимосвязи. Чем сильнее эти отклонения, тем больше будет наблюдаемое значение статистики критерия.
Это общая формула для таблиц сопряженности любого размера. В рассматриваемом нами случае \(k=l=2\), так как таблица сопряженности имеет размер 2×2. Следовательно, число степеней свобооды в нашем случае будет равно \(\text{df} = (2 - 1)(2-1) = 1\).
В частности, для нашего случая (Таблица 8.5 и Таблица 8.2):
\[ \begin{aligned} \chi^2 &= \frac{(83-67.37)^2}{67.37} + \frac{(3-18.63)^2)}{18.63} + \\ & + \frac{(11-26.63)^2}{26.63} + \frac{(23-7.37)^2}{7.37} \approx 59.06 \end{aligned} \] Ура! Мы рассчитали наблюдаемое значение статистики критерия. Далее по алгоритму необходимо выбрать уровень значимости — не будем сильно изощряться и выберем \(0.05\).
Теперь же рассмотрим, распределение статистики критерия при условии, что нулевая гипотеза верна.
8.1.3 Распределение \(\chi^2\)
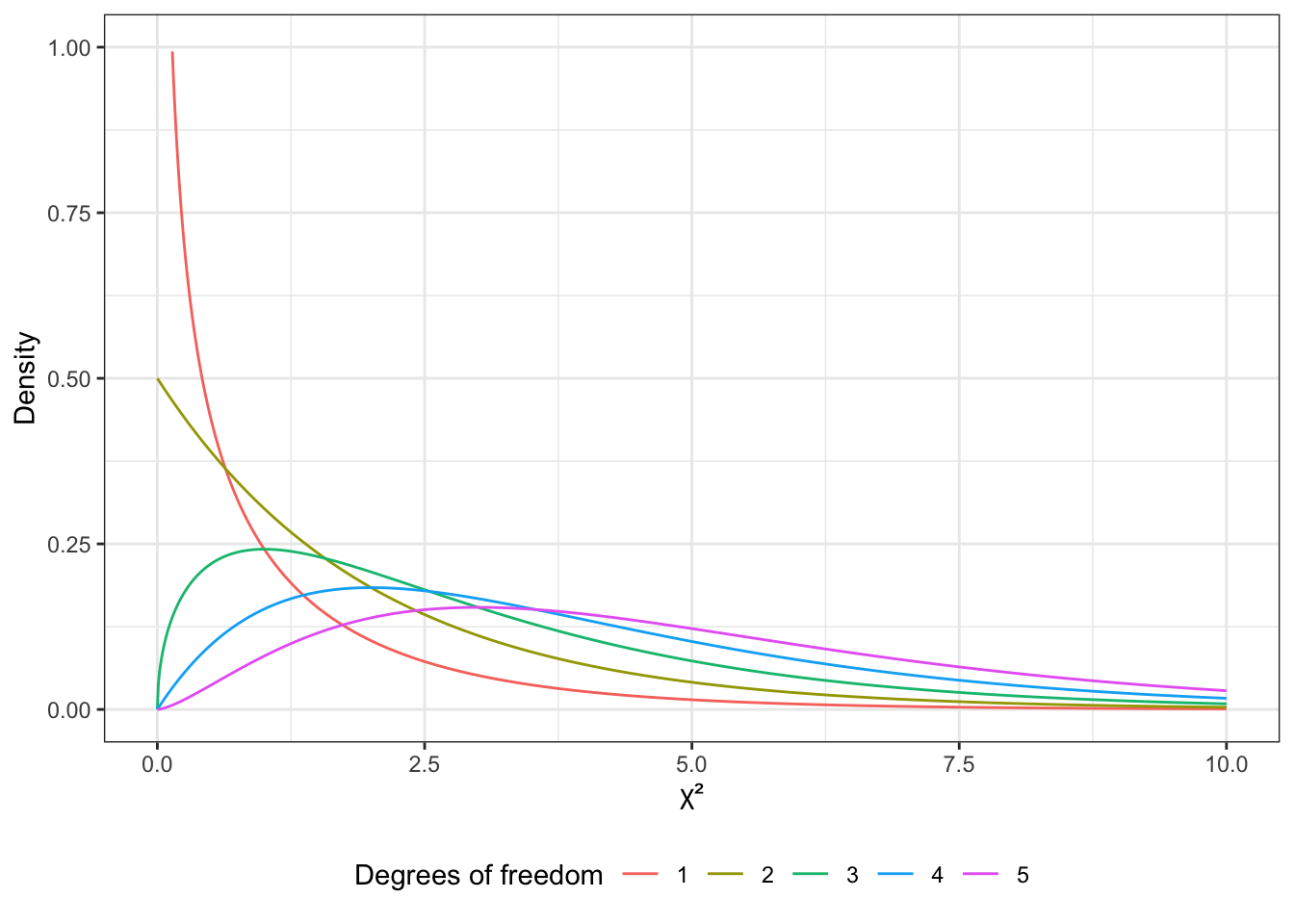
Почему вообще критерий называется «хи-квадрат»? Потому что распределение статистики критерия независимости Пирсона подчиняется распределению \(\chi^2\) при справедливости нулевой гипотезы. Выглядит это распределение так (Рисунок 8.1).
Поскольку мы работаем с таблицей сопряженности 2 × 2 и количество степеней свободы у нас равно 1, то нас будет прицельно интересовать вот это распределение (Рисунок 8.2).
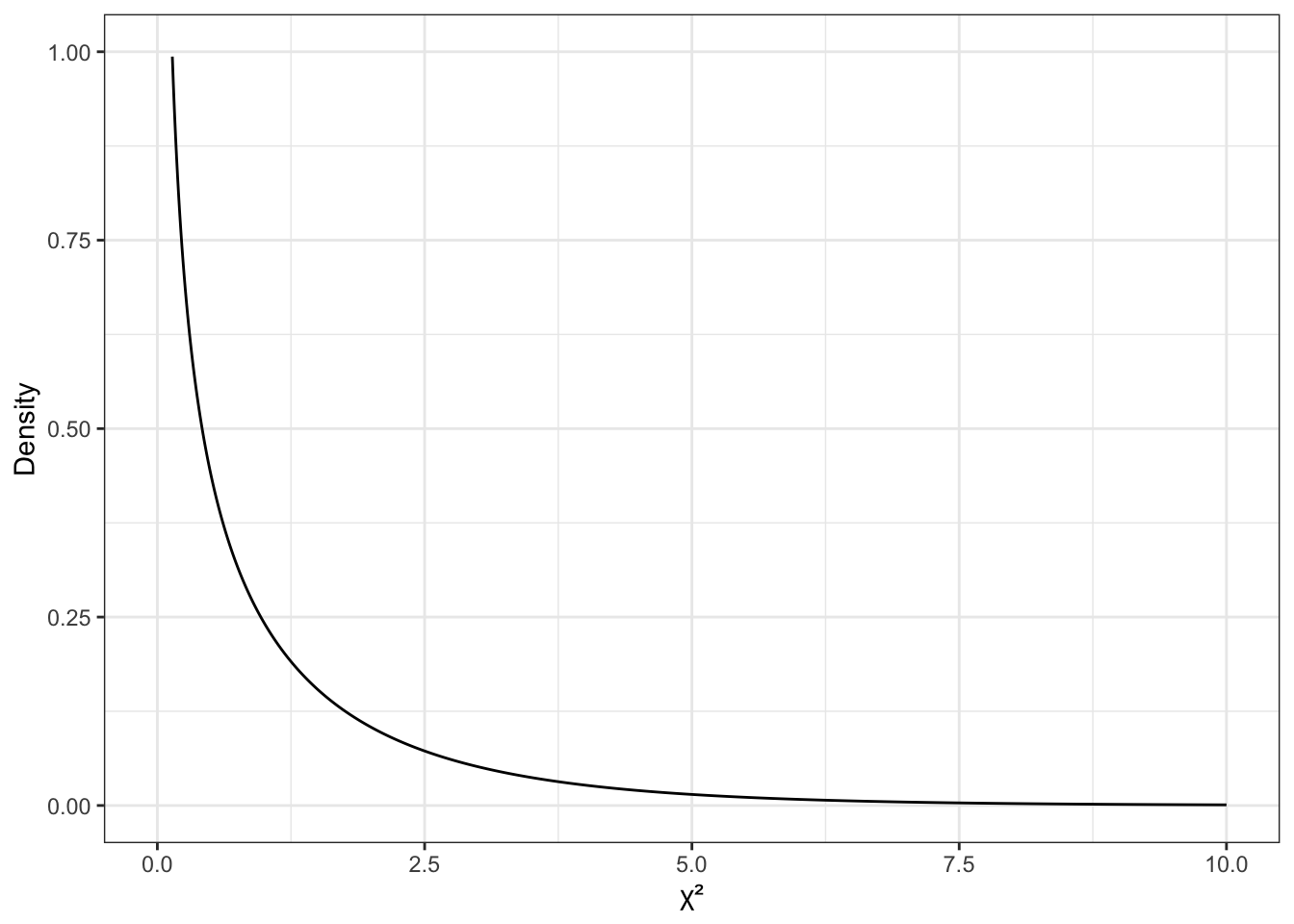
Как мы помним из темы про случайные величины, чем выше график плотности вероятности, тем чаще встречаются значения переменной. В данном случае мы видим, что при справедливости нулевой гипотезы малые значения \(\chi^2\) встречаются очень часто — то есть являются типичными. Большие же значения встречаются редко. Это согласуется с тем, что собственно показывает значение статистики \(\chi^2\):
- малые значения \(\chi^2\) соответствуют малым отклонениям эмпирических частот от теоретических, то есть типичны для случая, когда между переменными нет связи;
- большие значения \(\chi^2\) соответствуют больши́м отклонениям эмпирических частот от теоретических, поэтому нетипичны для случая, когда между переменным нет связи.
Отобразим выбранный уровень значимости (красная область в хвосте графика 8.3)
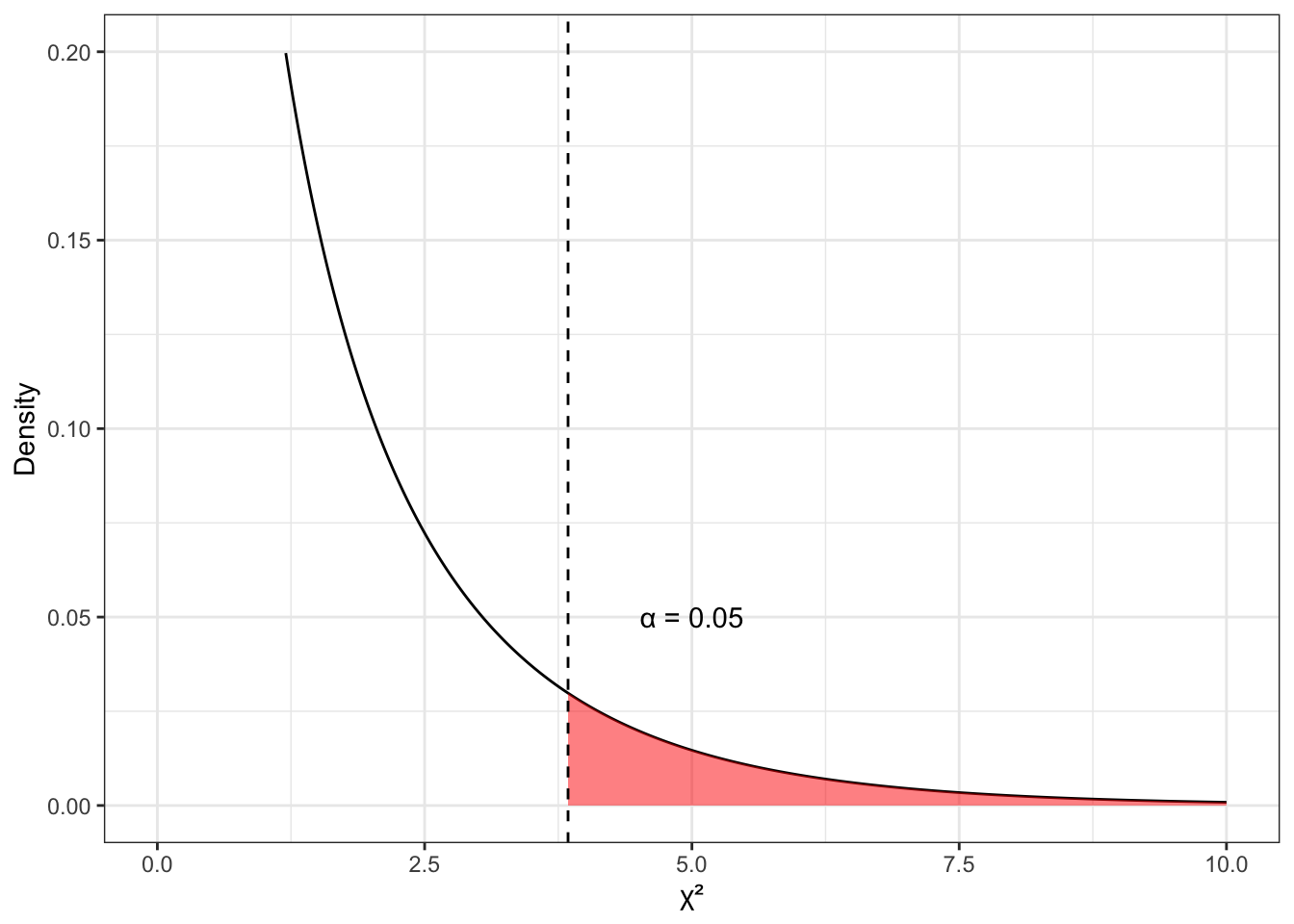
Мы немного ограничили ось \(y\) в пределах от 0 до 0.3, чтобы лучше видеть, что происходит — это связано с сильно асимметричной формой распределения. Красная область под графиком — это то, что мы назвали критическая область, или область отклонения нулевой гипотезы, она же область статистического вывода.
Итак, принципиально возможны две ситуации:
- рассчитанное значение \(\chi^2\) попало в критическую область (Рисунок 8.4 (a))
- в этом случае \(\mathsf{p} < \alpha\)
- следовательно, мы получили значение статистики критерия, нехарактерное для случая, когда верна нулевая гипотеза
- значит, у нас есть основания отклонить нулевую гипотезу и принять альтернативную;
- следовательно, мы получили значение статистики критерия, нехарактерное для случая, когда верна нулевая гипотеза
- в этом случае \(\mathsf{p} < \alpha\)
- рассчитанное значение \(\chi^2\) не попало в критическую область (Рисунок 8.4 (b))
- в этом случае \(\mathsf{p} > \alpha\)
- следовательно, мы получили значение статистики критерия, характерное для случая, когда верна нулевая гипотеза
- значит, у нас нет оснований отклонить нулевую гипотезу.
- следовательно, мы получили значение статистики критерия, характерное для случая, когда верна нулевая гипотеза
- в этом случае \(\mathsf{p} > \alpha\)
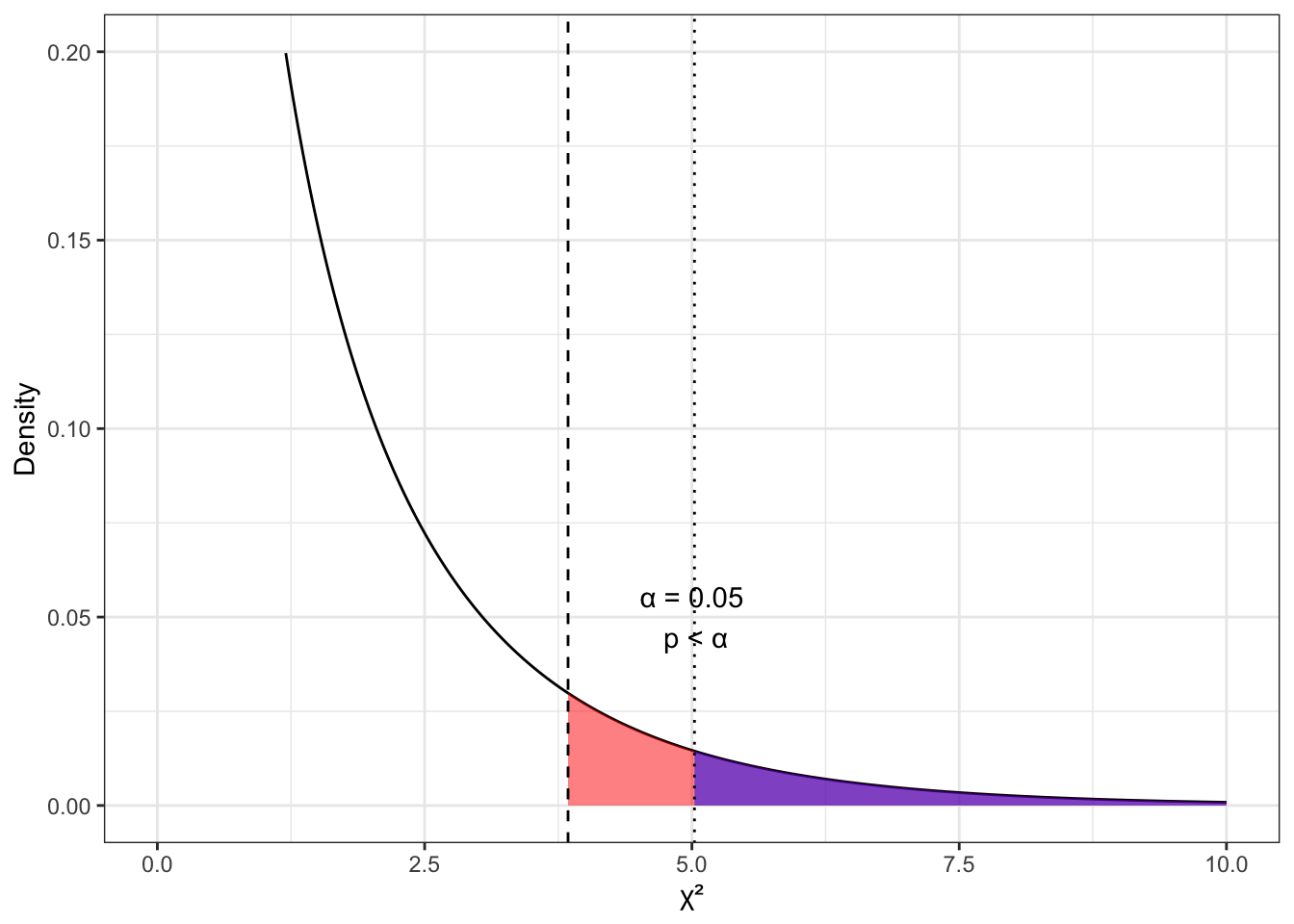
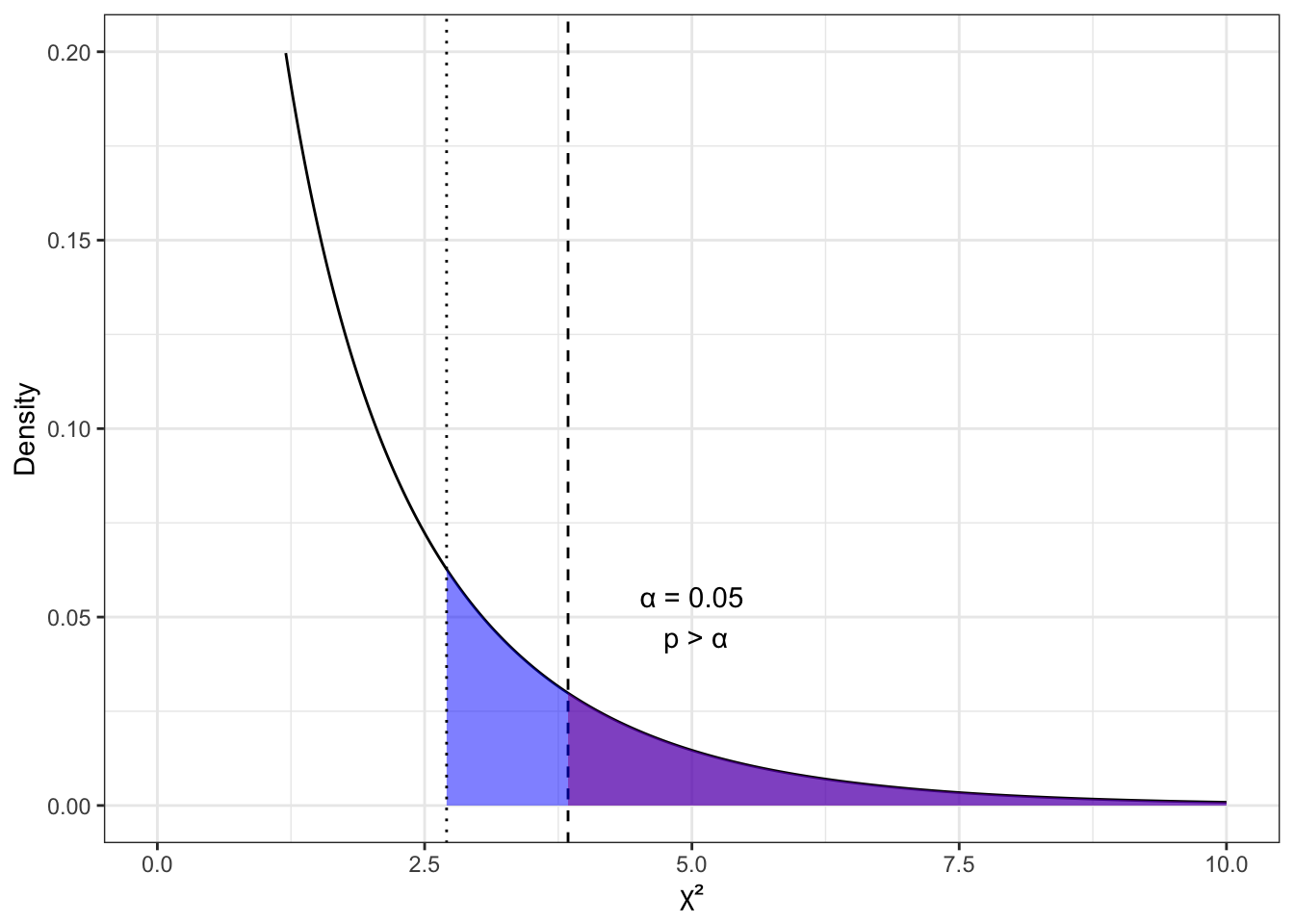
Глядя на значение статистики критерия, рассчитанное для нашего случая — напомню, мы насчитали выше \(\chi^2 \approx 59.06\) — и сопоставив его с картиной 8.3, можно прикинуть, что \(\mathsf{p} < .001\), следовательно, отклоняя нулевую гипотезу, мы можем сказать, что в данном исследовании обнаружено, что подготовка к экзамену связана с успешностью его сдачи. Вот это новость никогда бы не подумали…
8.1.4 Размер эффекта для критерия независимости Пирсона
То, что мы обнаружили различия или взаимосвязь — это хорошо. Но какова сила этой связи? Иначе говоря, какова величина размера эффекта?
Определение 8.1 Размер эффекта — численное выражение силы взаимосвязи между переменными (или различий между группами).
Ну, пусть так. У нас ведь уже посчитана статистика \(\chi^2\), и как мы говорили выше, она оценивает величину отклонений эмпирических частот от теоретических, что в общем-то и показывает величину различий. Да? Да же?
Отчасти да, но нет. Значение статистики критерия — любого, и критерий согласия Пирсона здесь не исключение — зависит от числа наблюдений. Так, мы может получить большое значение \(\chi^2\) даже при малых различиях в частотах, если объём выборки достаточно велик. Следовательно, сама статистика критерия не подходит для оценки размера эффекта.
Метрик размера эффекта для критерия независимости Пирсона существует несколько, из всех мы ограничимся упоминанием \(\varphi\)-коэффициента и \(V\) Крамера.
8.1.4.1 \(\varphi\)-коэффициент
Эта метрика размера эффекта считается на основе значения статистики \(\chi^2\), «убирая» из неё влияние количества наблюдений:
\[ \varphi = \sqrt{\frac{\chi^2}{N}} \]
Данная метрика применяется для таблица сопряженности 2×2, которые наиболее часто встречаются в практике. Значение \(\varphi\)-коэффициента изменяются в пределах от 0 до 1, а для интерпретации предлагаются следующие пороговые значения:
- \(0.10\) — малый эффект
- \(0.30\) — средний эффект
- \(0.50\) — большой эффект
8.1.4.2 \(V\) Крамера
Для таблиц сопряженности любого размера подходит метрика \(V\) Крамера, считающаяся несколько похоже на \(\varphi\)-коэффициент:
\[ V = \sqrt{\frac{\chi^2}{N \cdot \min(r-1, c-1)}}, \]
где \(r\) и \(c\) — количество строк и столбцов в таблице сопряженности соответственно.
Интерпретация значения \(V\) Крамера зависит от числа степеней свободы, которое для этой статистиски считается как \(df = \min(r-1, c-1)\):
- \(\text{df} = 1\) — совпадает с \(\varphi\)-коэффициентом:
- \(0.10\) — малый эффект
- \(0.30\) — средний эффект
- \(0.50\) — большой эффект
- \(\text{df} = 2\):
- \(0.07\) — малый эффект
- \(0.21\) — средний эффект
- \(0.35\) — большой эффект
- \(\text{df} = 3\):
- \(0.06\) — малый эффект
- \(0.17\) — средний эффект
- \(0.29\) — большой эффект
8.2 Критерий согласия Пирсона
Кроме критерия независимости Пирсона, существует ещё критерий согласия Пирсона. По сути, это некоторая вариации того, что мы изучили выше — и он даже проще, так как мы сравниваем эмпирические частоты с некоторыми заранее известными теоретическими. Собственно, поэтому он называется критерием согласия — согласовано ли наше эмпирическое распределение с некоторым заранее известным теоретическим.
Откуда мы знаем теоретические частоты? Ну, в общем случае — ниоткуда. Ведь это частоты генеральной совокупности, а о ней, как известно, ничего достоверно неизвестно. По этой причине любые критерии согласия в целом используются в исследовательской практике весьма редко. Обычно они являются частью какого-либо другого статистического метода.
И все же исследовательскую задач для критерия согласия Пирсона придумать можно. Скажем, вы аппробируете психометрический опросник, и вам надо показать, что ваша выборка аппробации репрезентативна относительно генеральной совокупности в отношении распределения респондентов по полу. Генеральная совокупность — Российская Федерация. Где взять теоретические частоты — ведь мы не можем исходить из предположения, что доли мужчин и женщин в России одинаковы? Хвала небесам, у нас есть Росстат — он же Федеральная служба государственной статистики — который нам рассказал, что мужчин в РФ 46%, а женщин по несложным подсчетам — 54%.
Пусть мы собрали выборку в 495 человек, из которых 262 — мужчины, а 233 — женщины. Таковы наши эмпирические частоты. Теоретические частоты будут рассчитываться по формуле \(n_i^{(\text{t})} = p_i \cdot N\), где \(p_i\) — теоретическая доля, \(N\) — количество наблюдений в выборке. Итого, для мужчин \(0.46 \cdot 495 = 227.7\), а для женщин \(0.54 \cdot 495 = 267.3\).
- Формула для расчета статистики критерия вот:
\[ \chi^2 = \sum_{i} \frac{(n_i - n_i^{(\text{t})})^2}{n_i^{(\text{t})}} \overset{H_0}{\thicksim} \chi^2(c-1), \] где \(c\) — количество колонок в таблице частот.
- Нулевая гипотеза (ограничимся нестрогой словесной формулировкой): эмпирические частоты не отличаются от теоретических.
- Статистический вывод выполняется по стандартному алгоритму.
Для нашего случая имеем:
\[ \chi^2 = \frac{(262 - 227.7)^2}{227.7} + \frac{(233 - 267.3)^2}{267.3} \approx 9.56 \overset{\chi^2(1)}{\Rightarrow} \mathsf{p} \approx .002 \]
Снова видим \(\mathsf{p} < \alpha\) (приняв \(\alpha = 0.05\)), значит мы получили значение статистики, не характерное для ситуации справедливости нулевой гипотезы, и у нас есть основания отклонить нулевую гипотезу и принять альтернативную о том, что эмпирические частоты отличаются от теоретических.
Получается, что наша выборка не особо репрезентативна. Грустно…