7 Тестирование статистических гипотез
Мы затеваем исследование, чтобы проверить какие-либо гипотезы. Поэтому в ходе статистического анализа мы, главным образом, заняты тем, что тестируем статистические гипотезы. Ведь на какого рода вопросы мы отвечаем с помощью анализа?
- Различаются ли группы между собой?
- Значимо ли влияние какого-либо фактора? → Различаются ли группы между собой?
- Хороша ли та модель, которую мы построили? → Отличается ли она от нулевой модели?
И так далее. Так или иначе, всё сводится к тому, что мы ищем какие-то различия. Но силу того, что у нас неопределённость и вариативность в данных, мы просто так «в лоб» сказать о различиях по оценкам параметров не можем. Приходится тестировать статистические гипотезы.
7.1 Базовые понятия
Определение 7.1 Гипотеза (\(H\)) — это предположение, которое подлежит проверке на основе результатов наблюдений.
Гипотезы, как мы знаем, бывают трех видов:
- Теоретическая — про конструкты
- Эмпирическая — про переменные (зависимые и независимые)
- Статистическая
- с одной стороны, про данные — что мы получили в данный конкретный момент, собрав вот эти конкретные данные
- с другой стороны, про параметры генеральной совокупности — так как мы стремимся всё же изучать их, работая с выборкой
Статистические гипотезы бывают простыми и сложными.
- Простая гипотеза (simple hypothesis) — это такое предположение, которое включает в себя какое-либо однозначно определяемое утверждение.
Например, истинная величина параметра соответствует некоторому строго заданному значению: \(H: \theta = \theta_0\). Другой вариант — две генеральные совокупности имеют одно и то же значение одной и той же характеристики: \(H: \theta_1 = \theta_2\).
- Сложная гипотеза (composite hypothesis) предполагает множественность вариантов для параметра, которые укладываются в рамки проверяемого предположения. Например, \(H: \theta > \theta_0\) или \(H: \theta_1 \neq \theta_2\).
В рамках самого хода тестирования гипотез существует проверяемая (нулевая) гипотеза (null hypothesis) (\(H_0\)). Её обычно стараются предельно упростить, поэтому она чаще всего формулируется как простая гипотеза. В противовес ей выдвигается альтернативная гипотеза (alternative hypothesis) (\(H_1\)), которая будет иметь, как следствие, вид сложной гипотезы.
Что же может случиться в ходе проверки статистической гипотезы?
7.2 Возможные результаты проверки гипотез
Мы изучаем в исследовании какую-либо закономерность, которая в реальном мире может существовать, а может и не существовать. В силу неопределённости и вариативности наших данных мы может либо обнаружить интересующую нас закономерность, либо не обнаружить её.
В качестве нулевой гипотезы мы выдвигаем предположение о том, что закономерность отсутствует — так мы упрощаем нашу нулевую гипотезу. Пусть \(H_0\) обозначает, что предположение об отсутствии закономерности, которое мы проверяем справедливо, а \(H_1\) — не справедливо. На основании данных мы можем либо не отклонить наше предположение (\(\hat H_0\)), либо отклонить (\(\hat H_1\)).
Тогда имеем следующую ситуацию (Таблица 7.1).
| \(H_0\) | \(H_1\) | |
|---|---|---|
| \(\hat H_0\) | ✓ | Ошибка II рода |
| \(\hat H_1\) | Ошибка I рода | ✓ |
Мы видим, что из четырёх возможных ситуаций две нас устраивают — там мы делаем корректный вывод об отсутствии или наличии закономерности. Две другие нас не устраивают, так как мы в этих случаях совершаем ошибки.
- Ошибка I рода возникает, когда в генеральной совокупности искомой закономерности нет, но мы в силу случайных флуктуаций в данных её нашли.
- Ошибка II рода возникает, когда в генеральной совокупности искомая закономерность есть, но мы в силу каких-либо причин её не нашли.
Ошибки — это нехорошо, они нас не устраивают. Надо каким-то образом их контролировать.
- Ошибка I рода контролируется достаточно просто. Так как в ситуации ошибки I рода мы получили некий результат — нашли закономерность, которую искали — мы можем посчитать вероятность, с которой потенциально ошиблись. А собственно контролировать ошибку мы будем с помощью уровня значимости \(\alpha\).
- Уровень значимости \(\alpha\) выбирается до начала процедуры тестирования гипотезы и задает вероятность, с который мы позволяем себе ошибиться — отклонить нулевую гипотезу, при условии, что она верна.
- Ошибку II рода контролировать сложнее, так как мы не получили результата — не нашли закономерность, которую искали. Но ситуации ошибки II рода — ложноотрицательного вывода — «противоположна» ситуация истинно положительного вывода — когда мы обнаружили закономерность, при условии, что она есть. Соответственно, нам будет полезна какая-то метрика, которая позволит сказать, что мы сделали всё возможное для того, чтобы обнаружить искомую закономерность.
- Вероятность ошибки II рода обозначается \(β\) — тогда вероятность того, что мы не совершили ошибку II рода будет \(1-\beta\). Эта величина называется статистической мощностью — она связана с размером эффекта и объемом выборки. На основании статистической мощности и ожидаемого размера эффекта можно рассчитать требуемый объем выборки.
Размер эффекта — это оценка величины, или силы, закономерности в генеральной совокупности. О нём мы будем говорить подробнее в последующих главах, так как на примере конкретных статистических методов этот концепт будет более осязаем.
Соберем все обозначения в единую табличку (Таблица 7.2)1.
| \(H_0\) | \(H_1\) | |
|---|---|---|
| \(\hat H_0\) | \(\mathbb P (\hat H_0 | H_0)\) | \(\mathbb P (\hat H_0 | H_1) = \beta\) |
| \(\hat H_1\) | \(\mathbb P (\hat H_0 | H_0) = \alpha\) | \(\mathbb P (\hat H_1 | H_1) = 1 - \beta\) |
Уровень значимости \(\alpha\) выбирается близким к нулю — конвенциональным значением для социальных наук считается \(0.05\). Вообще \(\alpha\) можно выбрать сколь угодно малым, однако при выборе уровня значимости руководствуются принципом разумной достаточности, так как если устремить \(\alpha\) к нулю, то устремится к нулю и вероятность отклонения нулевой гипотезы.
Достаточной статистической мощностью (\(1-\beta\)) считается \(0.8\). Аналогично, устремляя мощность к единице (\((1-\beta) \to 1 \Rightarrow \beta \to 0\)), мы устремляем вероятность не отклонения нулевой гипотезы к нулю.
Необходимо также помнить, что ошибки первого и второго рода связаны между собой так, что
\[ \alpha \to 0 \Rightarrow \beta \to 1 \]
7.3 Алгоритм тестирования статистических гипотез
Для тестирования гипотез есть два сценария: первый и тот, которым мы будем пользоваться. Первый вариант чуть более классический, второй — более гибкий.
Note 7.1: Сценарий номер раз
- Формулировка гипотезы
- Выбор статистического критерия
- Выбор уровня значимости \(\alpha\)
- Расчёт выборочной статистики
- Построение закона распределения статистики критерия при условии, что нулевая гипотеза верна
- Определение границ критической области
- Определение, попадает ли наблюдаемое значение статистики в критическую область и статистический вывод
Note 7.2: Сценарий номер два
- Формулировка гипотезы
- Выбор статистического критерия
- Выбор уровня значимости \(\alpha\)
- Расчёт выборочной статистики
- Построение закона распределения статистики критерия при условии, что нулевая гипотеза верна
- Расчёт p-значения (p-value)
- Сопоставление \(\alpha\) и p-value и статистический вывод
Разберёмся на примере, что значит каждый из обозначенных шагов в обоих алгоритмах.
Пусть у нас есть следующая ситуация: мы изучаем студентов трёх неких факультетов психологии и хотим выяснить, каков их уровень открытости к опыту [как личностной черты]. Пусть также у нас есть результаты по опроснику Большой пятерки в T-шкале2. Опираясь на теорию черт, мы воспользуемся допущением, что в генеральной совокупности личностные черты распределены нормально, а исходя из устройства T-шкалы, мы можем сказать, что интересующая нас переменная «открытость к опыту» имеет в генеральной совокупности нормальное распределение со средним 50 и стандартным отклонением 10, то есть \(X \thicksim \mathcal N (50, 100)\).
Для проверки гипотезы мы имеем следующие данные:
| Факультет | Количество респондентов | Средний балл по шкале «Открытость к опыту» |
|---|---|---|
| A | 50 | 51 |
| B | 50 | 53 |
| C | 50 | 47 |
| D | 30 | 47 |
Итак, сформулируем гипотезы. Рассмотрим сначала такой случай:
- Теоретическая: уровень открытости к опыту у студентов отличается от среднего уровня.
- Эмпирическая: балл по шкале «Открытость к опыту» отличается от среднего значения по данной шкале.
Теоретические и эмпирические гипотезы не касаются напрямую статистического анализа, так как мы в рамках него заняты тестированием статистических гипотез. Однако поскольку статистические гипотезы должны быть согласованы с эмпирическими, которые, в свою очередь, должны быть согласованы с теоретическими, мы прописали эти весьма незамысловатые гипотезы. Теперь же сформулируем статистические.
7.3.1 Формулировка гипотезы
Для обозначенной эмпирической гипотезы подойдут следующие статистические:
\[ \begin{aligned} H_0&: \mu = 50 \\ H_1&: \mu \neq 50 \end{aligned} \]
В формулировке гипотезы фигурирует \(\mu\) — так обозначается среднее генеральной совокупности. Действительно, как мы отмечали в начале главы, статистические гипотезы формулируются в терминах параметров генеральной совокупности. И действительно, как мы говорили в первой главе, мы хотели бы изучать всех студентов того или иного факультета, но в силу ограниченности ресурсов работаем с выборкой. Может показаться, что проверяя гипотезу «балл по шкале “Открытость к опыту” отличается от среднего значения по данной шкале», мы должны сравнивать балл каждого респондента со средним, но это, конечно же, не так, поскольку нас интересует, отличается ли в среднем балл респондентов от среднего по шкале — в данном случае 50. Балл каждого отдельного респондента отличаться от 50, безусловно, будет3 ввиду неопределенности и вариативности данных.
7.3.2 Выбор статистического критерия
Теперь необходимо подобраться статистический критерий для проверки заявленных статистических гипотез. Здесь может возникнуть вопрос — зачем нам в принципе какой-то статистический критерий? Ведь у нас есть выборочные средние (см. табл. 7.3) и число, с которым нам необходимо эти средние сравнить — в данном случае \(50\). Скажем, для факультета \(A\) мы имеем средний балл \(51\), а для факультета \(B\) — \(53\): ясно же, что \(51 \neq 50\) и \(53 \neq 50\). Почему мы не можем вывод просто вот так?
Вновь нам необходимо вспомнить, что ввиду неопределенности и вариативности статистических данных мы могли случайно получить наблюдаемые абсолютные различия между средним и заданным значением. Вполне возможно, что в генеральной совокупности среднее на самом деле \(50\), однако из-за случайных ошибок в ходе измерения или формирования выборки, полученное \(51\) не будет статистически отличаться от \(50\). Для того, чтобы проверить, насколько имеющиеся отклонения неслучайны и необходим статистический критерий.
Для проверки разных статистических гипотез будут использоваться разные статистические критерии, с которым мы будем постепенно знакомиться далее. Для проверки нашей гипотезы о равенстве среднего некоторому заданному значению подойдет z-тест.
Любой статистический критерий, по сути, является собой некоторую формулу, которая позволяет получить значение статистики критерия. В случае z-теста это будет формула для получения z-значения.
Формула расчёта статистики z-теста такова:
\[ z = \frac{\overline X - \mu_0}{\text{se}_X} = \frac{\overline X - \mu_0}{\dfrac{\sigma_X}{\sqrt{n}}}, \tag{7.1}\]
где \(\overline X\) — выборочное среднее (оценка среднего генеральной совокупности), \(\mu_0\) — некоторое заданное значение, с которым необходимо сравнить среднее, \(\text{se}_X\) — стандартная ошибка случайной величины \(X\) (см. соответствующий раздел), \(\sigma_X\) — дисперсия случайной величины \(X\), \(n\) — количество наблюдений в выборке.
7.3.3 Выбор уровня значимости
Здесь мы воспользуемся конвенциональным значением: \(\alpha = 0.05\). Вообще вы можете выбрать и более низкое значение в рамках собственного исследования.
Все вышепройденные шаги алгоритма тестирования гипотез в ситуации реального исследования должны быть выполнены до начала сбора данных при планировании исследования.
7.3.4 Расчёт выборочной статистики
Теперь обратимся к имеющимся у нас данным (Таблица 7.3) и рассчитаем наблюдаемое значение z-статистики для каждой из выборок, используя формулу -Уравнение 7.1.
\[ \begin{aligned} z_\text{A} = \frac{51 - 50}{10/\sqrt{50}} \approx 0.707 \\ z_\text{B} = \frac{53 - 50}{10/\sqrt{50}} \approx 2.121 \\ z_\text{C} = \frac{47 - 50}{10/\sqrt{50}} \approx -2.121 \\ z_\text{D} = \frac{47 - 50}{10/\sqrt{30}} \approx -1.643 \\ \end{aligned} \]
Итак, мы получили четыре z-значения для факультетов A, B, C и D. Здесь возникает вполне закономерный вопрос — и чо?
7.3.5 Распределение статистики
Нам необходимо сделать вывод об отсутствии или наличии закономерности — такова была изначальная задача. Мы получили наблюдаемые значения z-статистики — видимо, нам необходимо сделать вывод на их основе.
Ясно, что z-статистика — это случайная величина. Если посмотреть на формулу её расчёта (7.1), то можно заметить, что её значение зависит от выборочного среднего. Выборочное среднее же само является случайной величиной, так как зависит от того, какие значения попадут в выборку, а формирование выборки случайно.
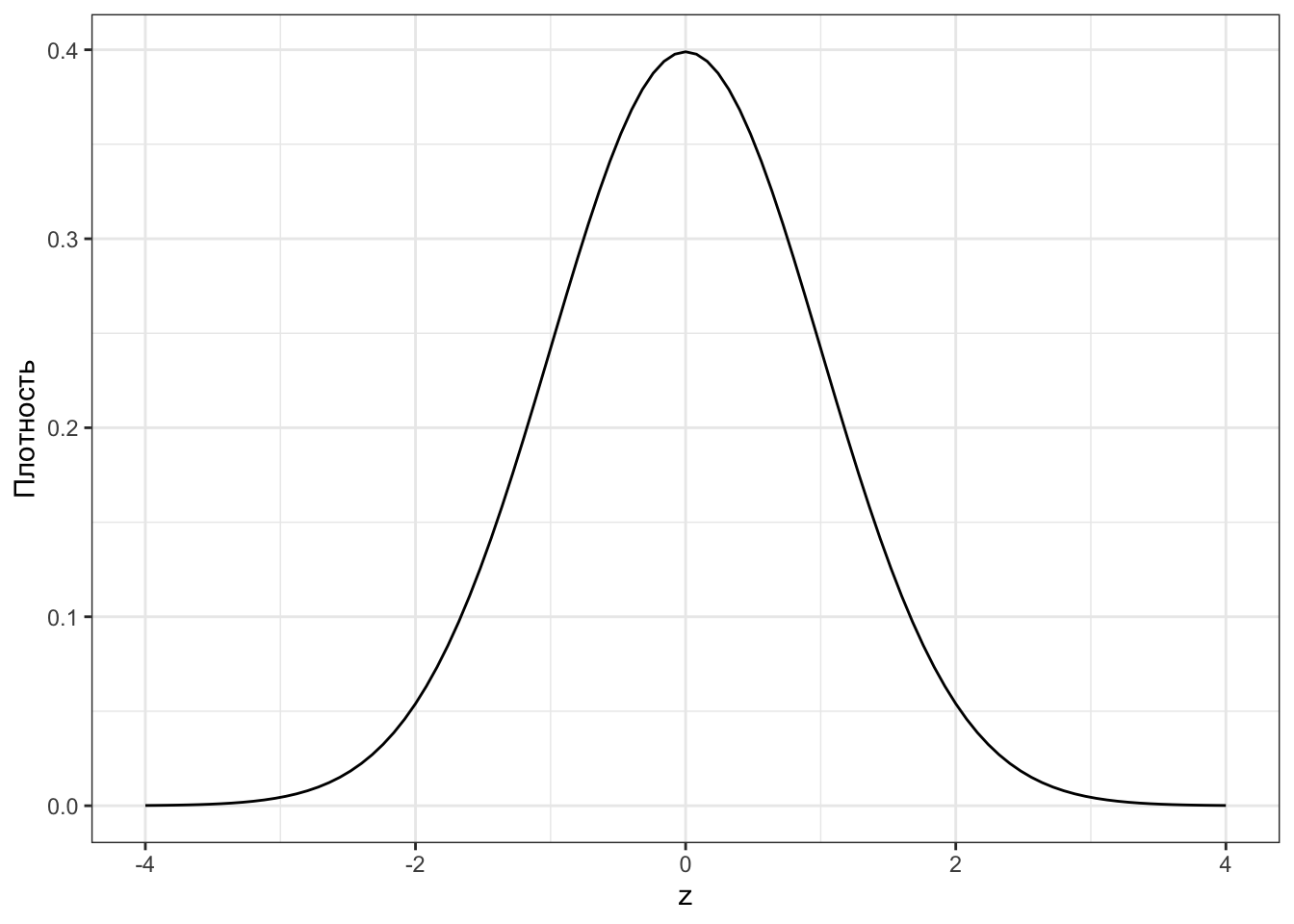
Если z-статистика есть случайная величина, то у неё должно быть какое-то распределение, как и у любой случайной величины. И действительно, z-статистика при справедливости нулевой гипотезы подчиняется стандартному нормальному распределению:
\[ z \overset{H_0}{\thicksim} \mathcal{N}(0, 1) \]
Собственно, именно поэтому она и является z-статистикой, так как с помощью буквы \(z\) в статистике обычно обозначается стандартно нормально распределённая случайная величина.
Поскольку z-статистика есть непрерывная случайная величина, то её распределение задается плотностью вероятности (Рисунок 7.1). Как мы помним, подобный график показывает нам, что значения из «середины» распределения встречаются часто, а значения из хвостов — реже.
Чем нам это поможет в статистическом выводе? Обратим внимание на одну из ключевых вещей — мы строим распределение статистики критерия при условии, что нулевая гипотеза верна.
- Во-первых, потому что ситуация справедливости нулевой гипотезы — это единственный возможный случай, когда \(\mu = 50\). Если верна альтернативная — \(\mu \neq 50\) — то возможно великое множества вариантов. В частности, поэтому нулевая гипотеза чаще всего формулируется в виде простой гипотезы.
- Во-вторых, имея распределение статистики при справедливости нулевой гипотезы, мы можем сказать, насколько типично то или иное значение, когда верна нулевая гипотеза.
7.3.6 Критическая область vs p-value
Что ж, у нас есть идея, как оценить типичность того или иного z-значения для случая, когда верна нулевая гипотеза об отсутствии различий. Осталось определиться с тем, какие именно значения будут считаться нетипичными — необходимо выбрать диапазон нетипичных значений.
Здесь нам на помощь приходит уровень значимости \(\alpha\) — именно он определяет, какие значения статистики мы будем считать нетипичными. Выберем такие диапазоны из хвостов распределения, чтобы вероятность попадания значений в них была равна \(\alpha\), то есть \(0.05\). Эти диапазоны называются критической область (сritical region), а зная, как устроена плотность распределения, мы можем рассчитать критическое значение (critical value) \(z_\text{cr}\), которое будет являться границей критической области (Рисунок 7.2).
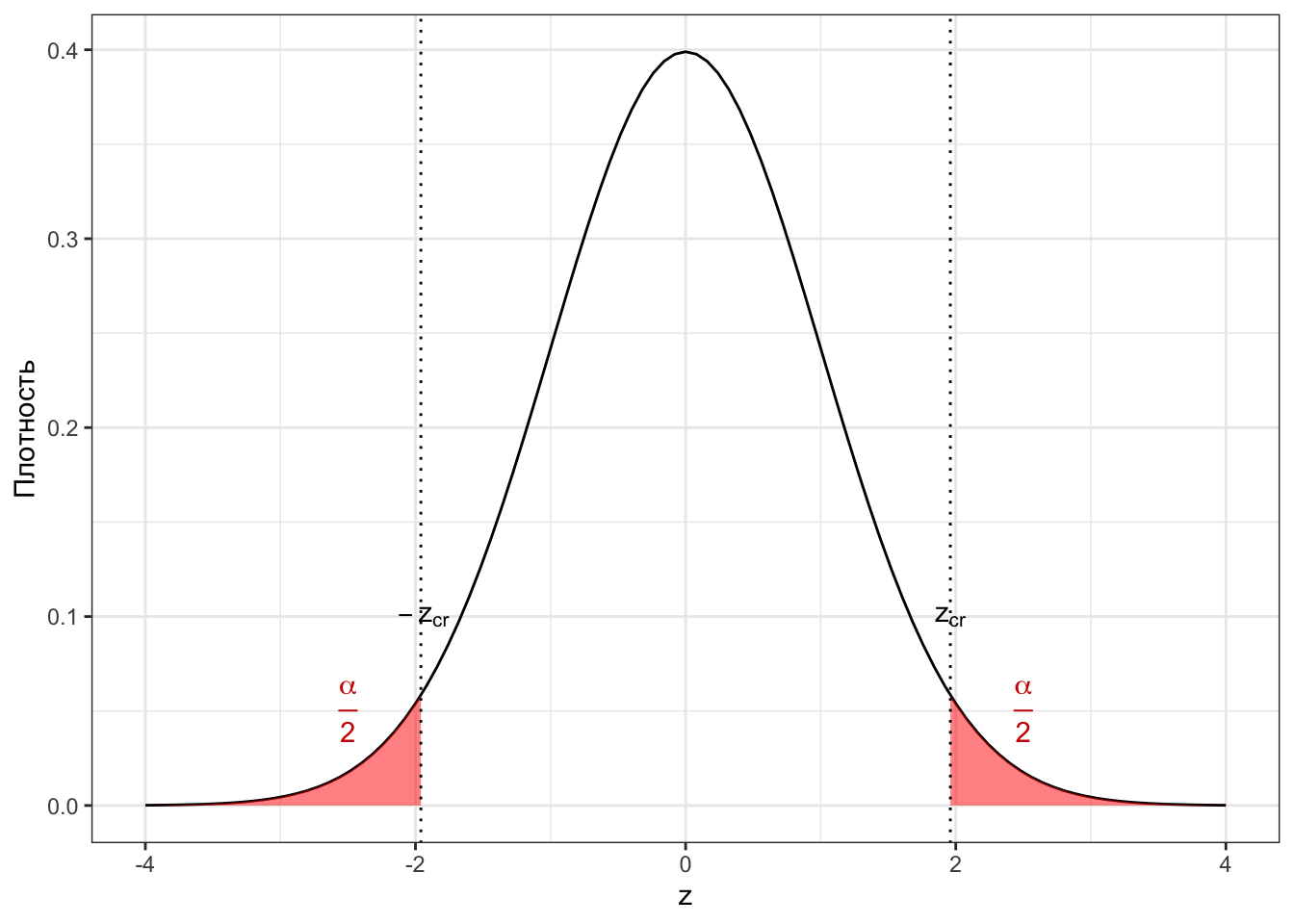
Первый сценарий (7.1) учит нас, что после того, как была определена критическая область, необходимо узнать, попадает или нет наблюдаемое значение статистики в критическую область. Давайте проверим это для имеющихся у нас значений (Рисунок 7.3).
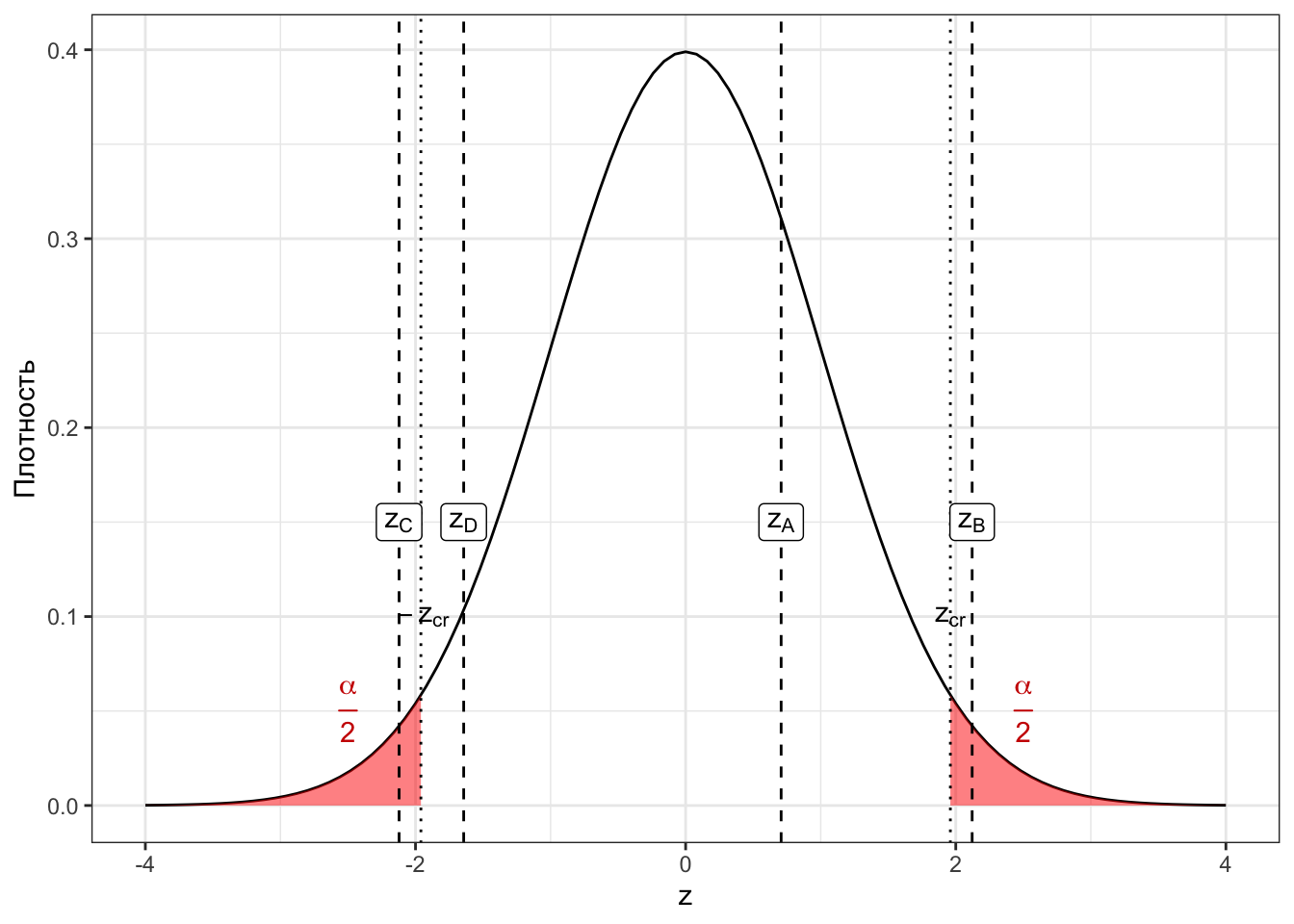
Видно, что
- \(z_\text{A}\) и \(z_\text{D}\) не попадают в критическую область,
- а \(z_\text{B}\) и \(z_\text{C}\) — попадают.
Тогда мы можем заключить, что
- так как \(-z_\text{cr} < z_\text{A} < z_\text{cr}\) и \(-z_\text{cr} < z_\text{D} < z_\text{cr}\), то для факультетов A и D мы получили значение статистики критерия типичное для случая, когда нулевая гипотеза верна;
- так как \(z_\text{B} > z_\text{cr}\) и \(z_\text{С} < -z_\text{cr}\), то для факультетов B и C мы получили значение статистики критерия нетипичное для случая, когда верна нулевая гипотеза.
На основании этого мы далее сделаем статистический вывод.
Однако перед этим посмотрим на иной способ определения типичности наблюдаемых значений. Во втором сценарии вместо критической области требуется расчёт некоего p-значения. Что это такое и зачем оно нам может быть нужно?
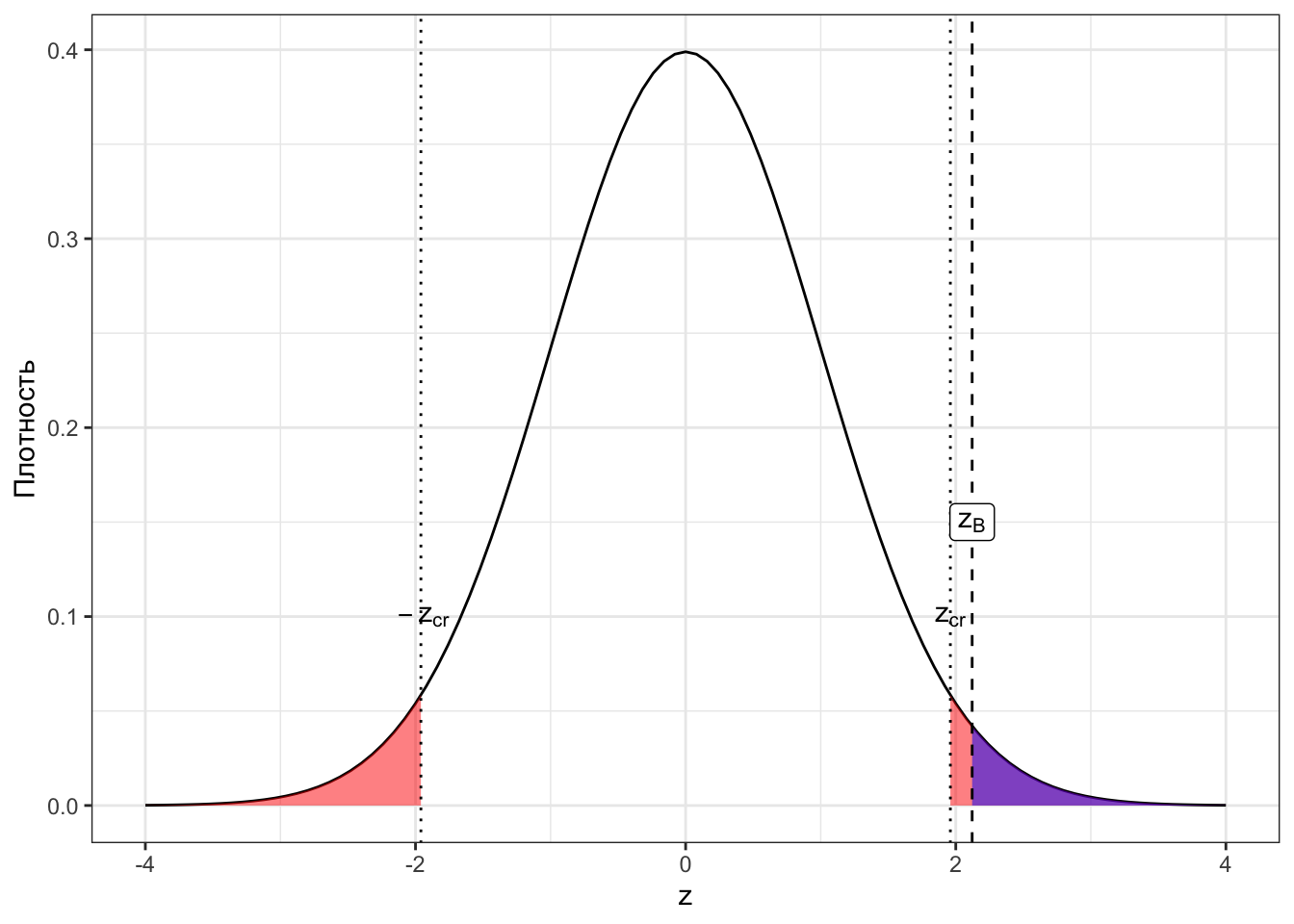
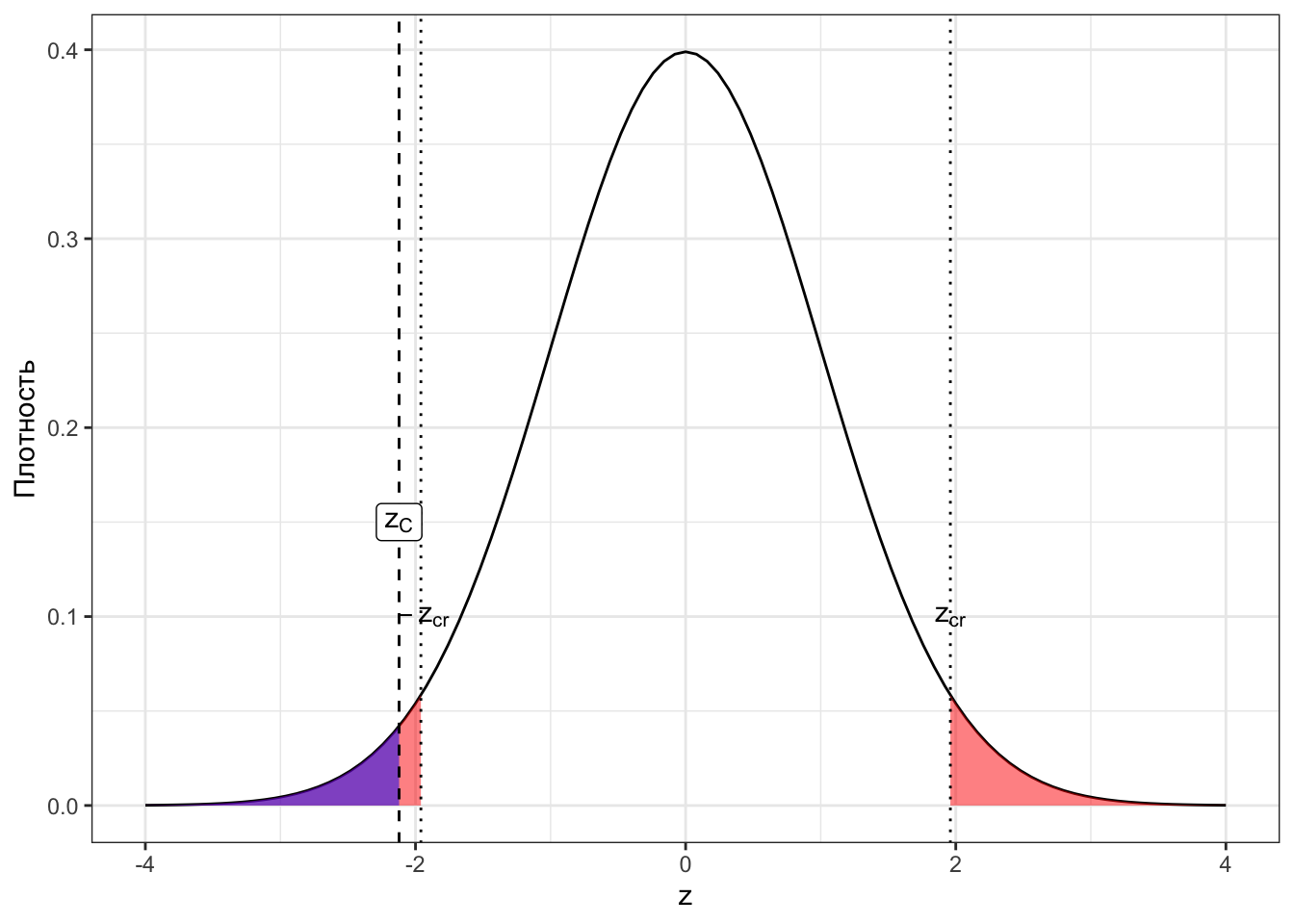
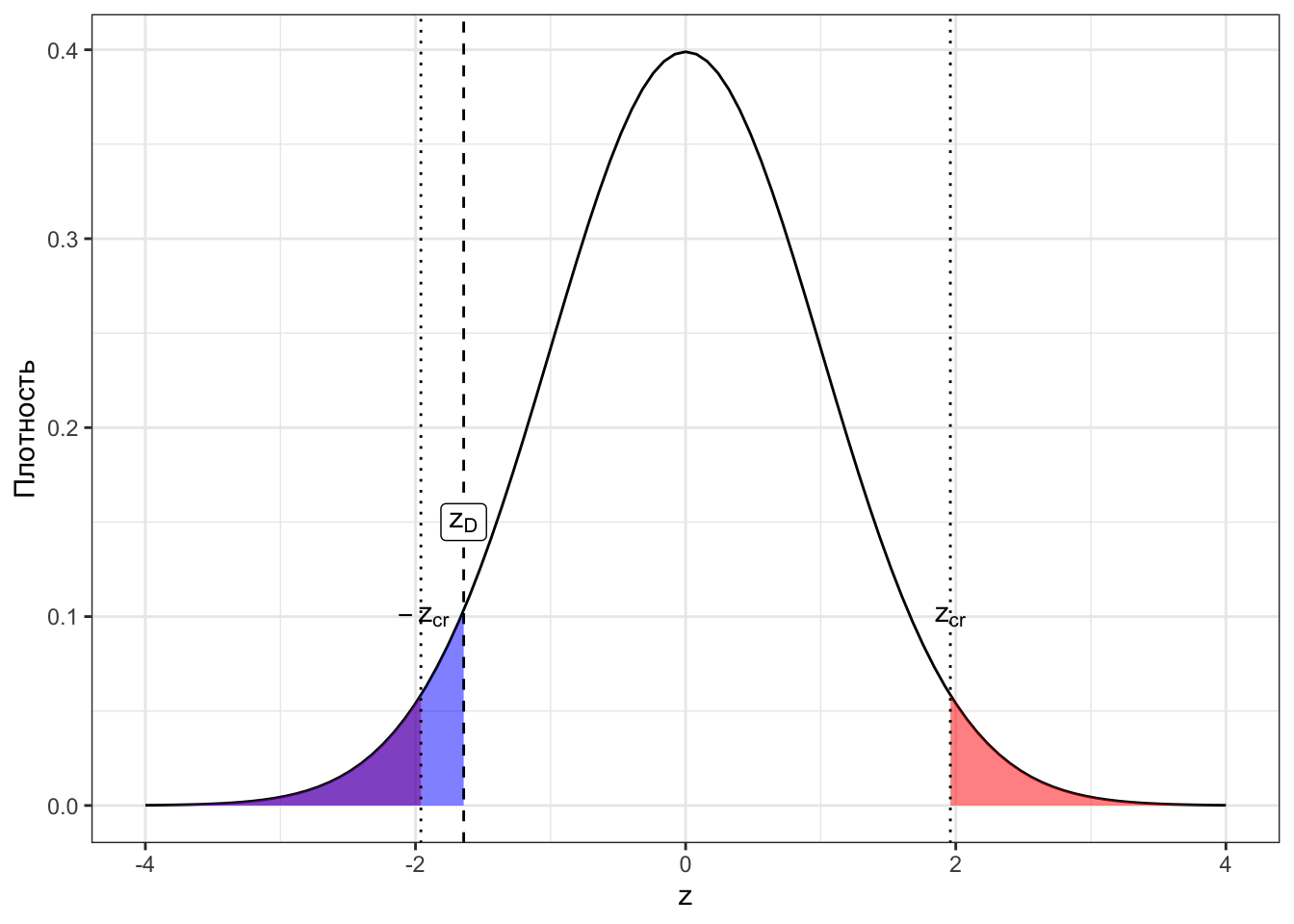
Посмотрим сначала на картинки для наших случаев. Закрашенная область под графиками — это p-значения для соответствующих z-статистик (Рисунок 7.4).
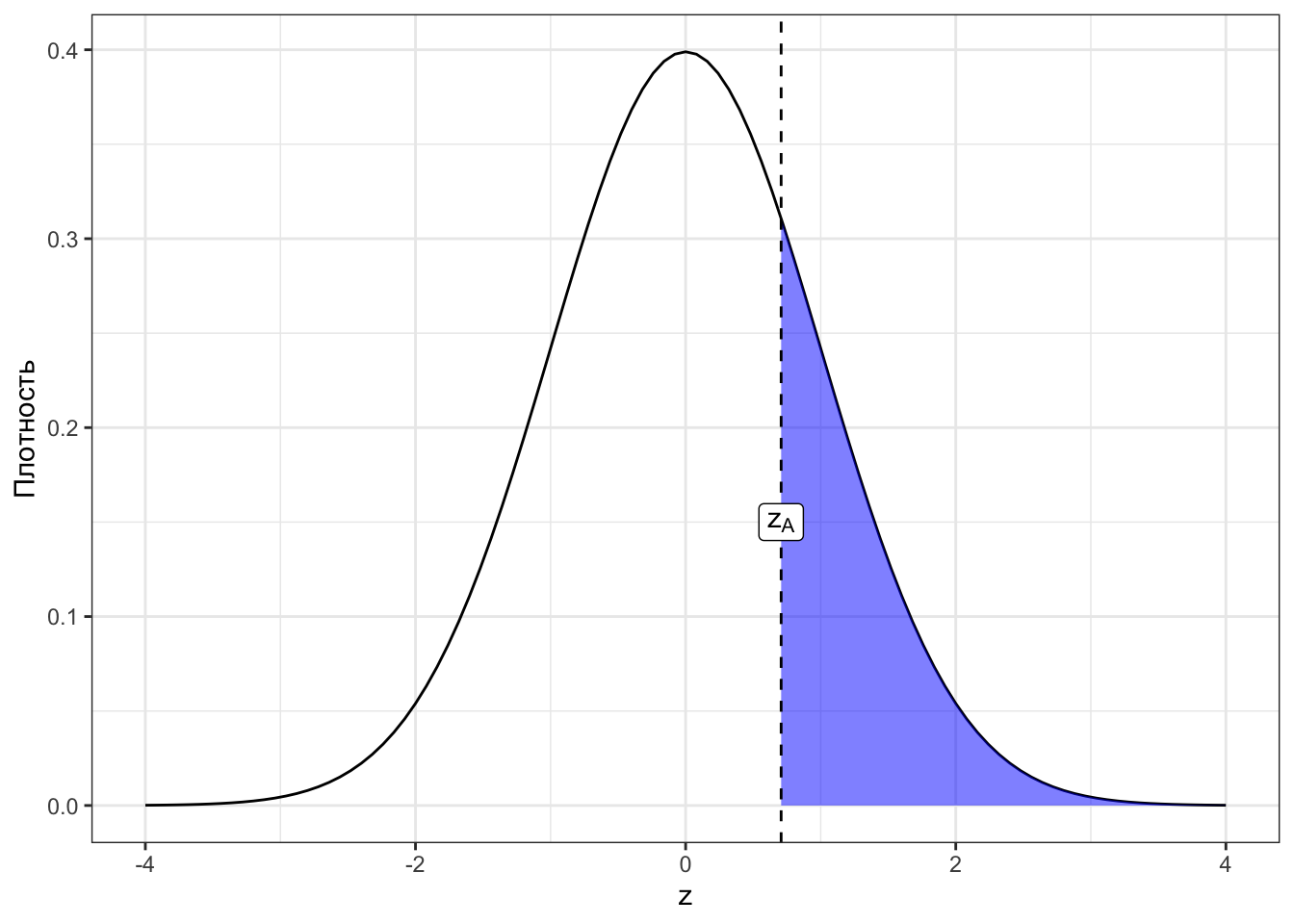
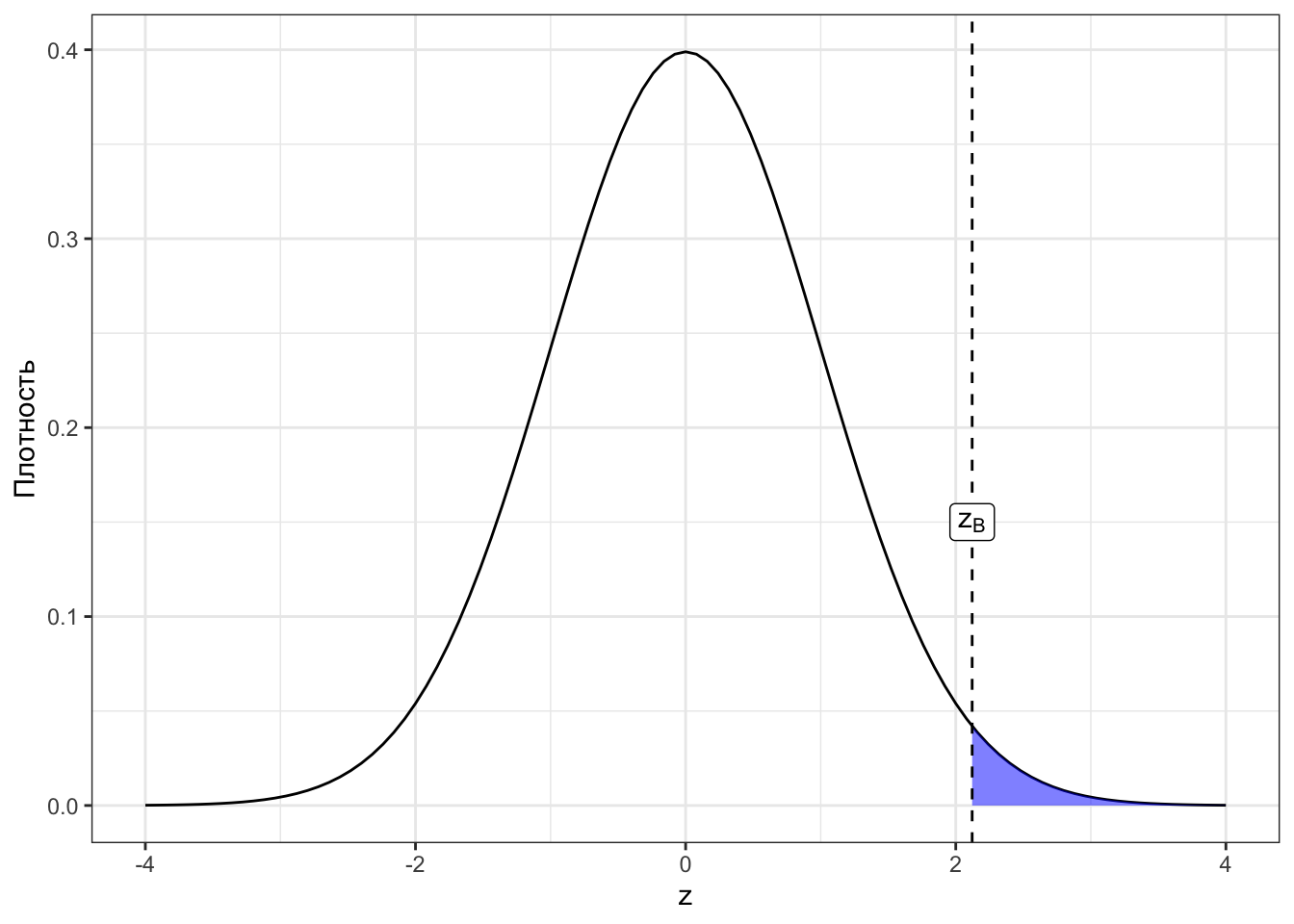
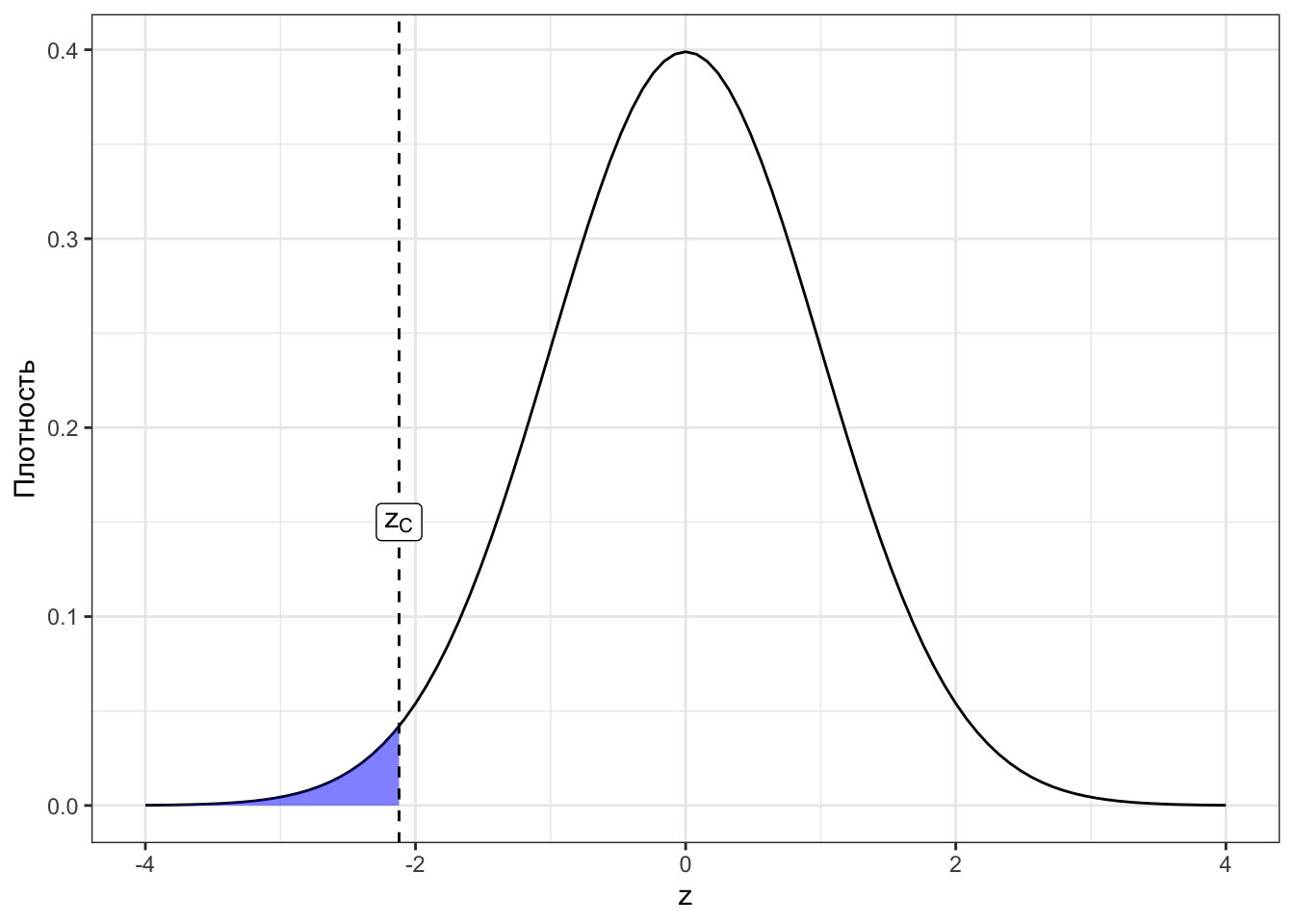
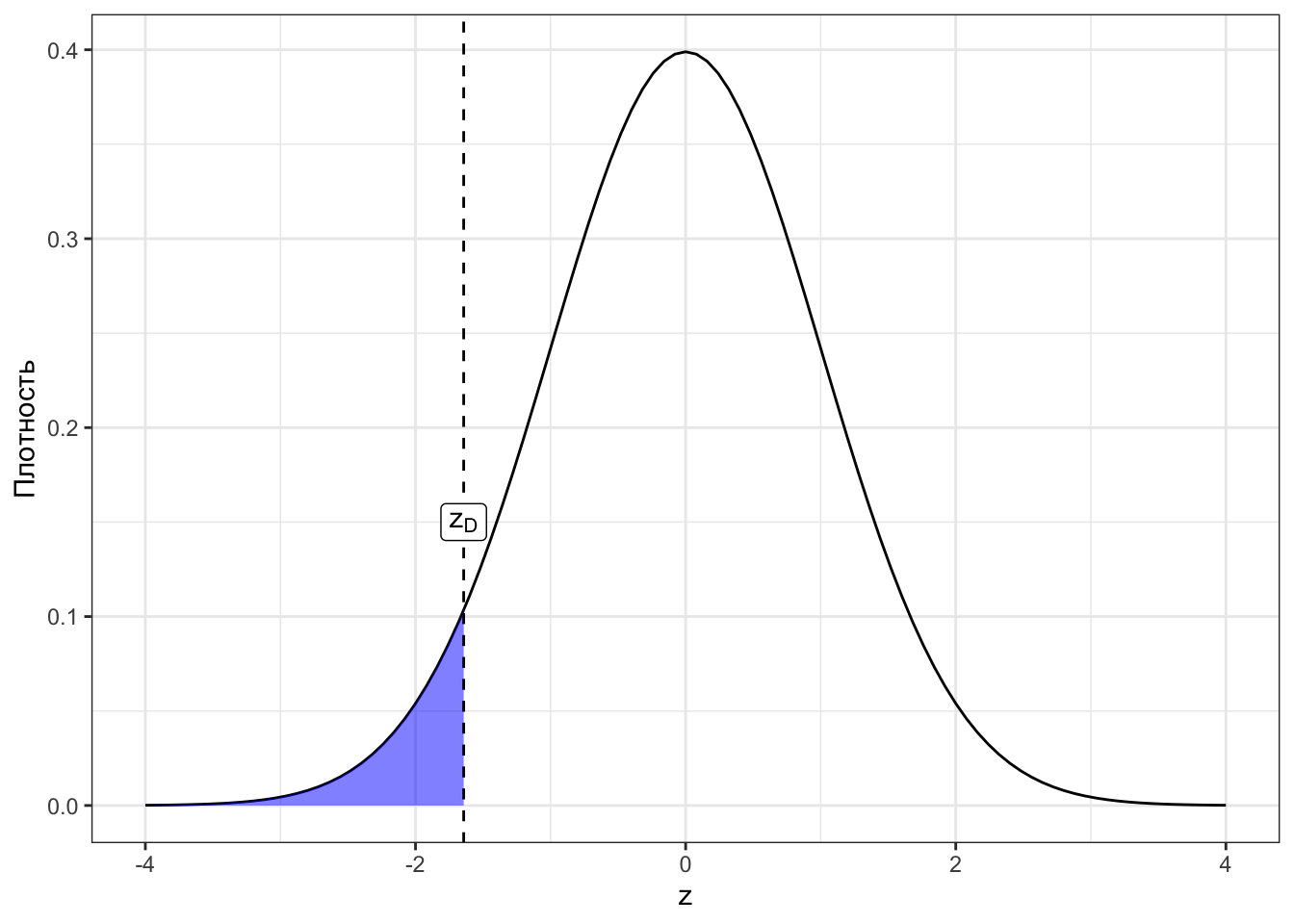
Исходя из визуализаций можно дать p-значению такое определение:
Определение 7.2 p-значение (p-value) — вероятность получить такое или более экстремальное значение статистики критерия при условии, что нулевая гипотеза верна.
Экстремальное в данном контексте означает «ещё больше отклоняющееся от нуля, чем наблюдаемое». Это всё, конечно, хорошо, но нам бы определить типичность наблюдаемого значения z-статистики. Можно ли это сделать с помощью p-значения?
Да, и на практике ровно так и поступают. Давайте сопоставим p-значение с уровнем значимости. Сначала вновь сделаем это визуально (Рисунок 7.5).
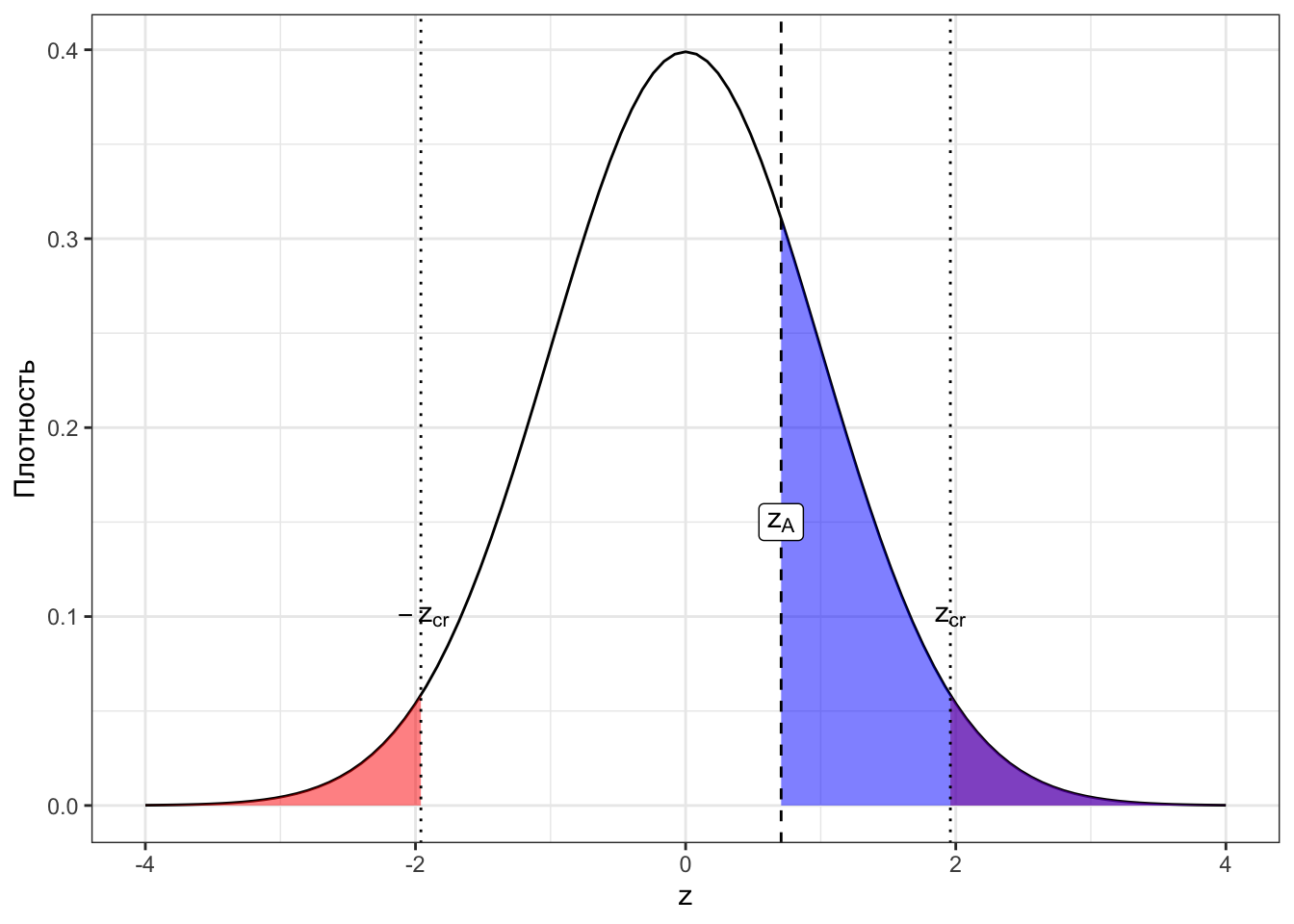
- так как для факультетов A и D \(\mathsf p > \alpha\), то мы получили значение статистики критерия типичное для случая, когда нулевая гипотеза верна;
- так как для факультетов B и C \(\mathsf p < \alpha\), то мы получили значение статистики критерия нетипичное для случая, когда верна нулевая гипотеза.
Как не трудно видеть, сценарий два, в котором рассчитывается p-value, оказывается несколько проще, чем сценарий с критической областью, однако по смыслу они равносильны друг другу, ведь
- если значение попало в критическую область, то \(\mathsf p < \alpha\),
- если значение не попало в критическую область, то \(\mathsf p > \alpha\).
7.3.7 Статистический вывод
Итого, мы получили в итоге по обоим сценариям оценку типичности значения z-статистики. Пришло время сделать статистический вывод. В двух обозначенных сценариях он будет делать немного по-разному, однако сами выводы будут равносильны в обоих случаях,
Итак, для первого сценария (7.1) было рассчитано \(z_\text{cr}\) и наблюдаемые z-значения сравнивались с ними. Алгоритм статистического вывода в данном случае будет таков:
- если \(|z| < |z_\text{cr}|\), то мы имеем значение статистики критерия, типичное для случая, когда нулевая гипотеза верна, следовательно, у нас нет оснований отклонять нулевую гипотезу
- если \(|z| > |z_\text{cr}|\), то мы имеем значение статистики критерия, нетипичное для случая, когда нулевая гипотеза верна, следовательно, у нас есть основания отклонить нулевую гипотезу и принять альтернативную
Таким образом,
- для факультетов A и D ввиду того, что в обоих случаях наблюдаемое значение z-статистики по модулю меньше критического, то мы не можем отклонить нулевую гипотезу о том, что средний балл по шкале «Открытость к опыту» не отличается от 50.
- для факультетов B и C ввиду того, что в обоих случаях наблюдаемое значение z-статистики по модулю больше критического, то мы можем отклонить нулевую гипотезу о том, что средний балл по шкале «Открытость к опыту» не отличается от 50 — в этом случае мы заключаем, что, согласно имеющимся данным, средний балл по шкале «Открытость к опыту» на факультете B больше 50, а на факультете C — меньше 50.
Для второго сценария (7.2) было рассчитано p-значение, которое необходимо сравнить с уровнем значимости \(\alpha\). Алгоритм статистического вывода будет в этом случае таков:
- если \(\mathsf p > \alpha\), то мы имеем значение статистики критерия, типичное для случая, когда нулевая гипотеза верна, следовательно, у нас нет оснований отклонять нулевую гипотезу
- если \(\mathsf p < \alpha\), то мы имеем значение критерия, нетипичное для случая, когда нулевая гипотеза верна, следовательно, у нас есть основания отклонить нулевую гипотезу и принять альтернативную
Таким образом,
- для факультетов A и D ввиду того, что в обоих случаях \(\mathsf p > \alpha\), то мы не можем отклонить нулевую гипотезу о том, что средний балл по шкале «Открытость к опыту» не отличается от 50.
- для факультетов B и C ввиду того, что в обоих случаях \(\mathsf p < \alpha\), то мы можем отклонить нулевую гипотезу о том, что средний балл по шкале «Открытость к опыту» не отличается от 50 — в этом случае мы заключаем, что, согласно имеющимся данным, средний балл по шкале «Открытость к опыту» на факультете B больше 50, а на факультете C — меньше 50.
Мы видим, что независимо от того, каким из сценариев тестирования статистических гипотез мы пользуемся, мы получаем одинаковые статистические выводы. На практике большую применимость находит второй сценарий (7.2), поскольку он оказывается более гибким. Представим, что мы захотели понизить уровень значимости с \(0.05\) до \(0.01\) — такие уровни значимости встречаются, например, в медицине. Если мы идем по первому сценарию, то нам надо заново пересчитать критические значения и вновь проанализировать, попадает ли наблюдаемое значение в критическую область. Если мы адепты второго сценария, то нам надо только выполнить одно новое сравнение нашего p-value с новым уровнем значимости.
7.4 Асимметрия статистического вывода
Обратим внимание на формулировки, которые мы использовали при формулировании статистического вывода. Ввиду равносильности обоих сценариев и большей практической применимости второго — с p-value — остановимся на нём:
- если \(\mathsf p < \alpha\), то у нас есть основания отклонить нулевую гипотезу и принять альтернативную;
- если \(\mathsf p > \alpha\), то у нас нет оснований отклонить нулевую гипотезу.
Наблюдаем некоторую асимметрию:
- если \(\mathsf p < \alpha\), то у нас есть основания подозревать наличие закономерности
- если \(\mathsf p > \alpha\), то у нас нет оснований подозревать наличие закономерности
- но также нет оснований говорить, что закономерности нет
То есть в случае, когда мы получили \(\mathsf p > \alpha\), мы остаёмся в некотором неведении относительно того, есть закономерность или нет. Сам по себе алгоритм статистического вывода не позволяет говорить об отсутствии закономерности, следовательно, проверить эмпирическую гипотезу об отсутствии связи или об отсутствии различий с помощью изучаемых нами статистических методов невозможно.
Строго говоря, даже в ситуации принятия альтернативной гипотезы мы не можем быть абсолютно уверенны в том, что изучаемая закономерность существует, поэтому необходимы репликационные исследования, которые нацелены на проверку того, воспроизводится ли результат, полученный в отдельном исследовании.
7.5 Статистическая мощность и размер эффекта
Вернемся к таблице 7.1. В алгоритме тестирования статистических гипотез использовался уровень значимости \(\alpha\), контролирующий ошибку I рода. Собственно, с его помощью мы делали статистический вывод. Однако мы никак не контролировали ошибку II рода, не упоминали статистическую мощность и размер эффекта. Действительно, сам по себе алгоритм тестирования статистических гипотез никак не работает с ложноотрицательным выводом. Однако статистическая мощность оказывается крайне полезна, если мы хотим всё же сделать какой-то вывод в случае, когда не может отклонить нулевую гипотезу.
Подход здесь оказывается несколько хитрее. Сама по себе статистическая мощность описывает вероятность того, что мы не совершили ошибку II рода, то есть обнаружили закономерность при условии, что она есть. Но управлять этой вероятность мы можем только на этапе планирования исследования — в отличие от вероятности ошибки I рода, которая напрямую зависит от выбранного уровня значимости.
Статистическая мощность связана, как уже отмечалось выше, с размером эффекта и объемом выборки. Связь эта устроена следующим образом:
- при заданной статистической мощности, для поиска меньшего размера эффекта необходим больший объем выборки;
- при заданной статистической мощности, на большей выборке мы можем обнаружить меньший размер эффекта.
Взаимосвязи между ошибками первого и второго рода, статистической мощностью, размером эффекта и объемом выборки можно изучить здесь.
Поскольку размер эффекта по-разному считается для разных статистических тестов, мы подробнее будем рассматривать его вместе с каждым из методов. Пока же ограничимся общим представлением о взаимосвязи всех этих конструкций.
Алгоритм тестирования статистических гипотез и алгоритм статистического вывода будет нам встречаться в каждой из последующих глав данного раздела, поэтому если сейчас не вполне понятно, как это всё работает, далее, полагаю, это станет яснее на примере конкретных статистических методов.
Здесь использовано обозначение условной вероятности \(\mathbb P (A|B)\), то есть это вероятность того, что случилось событие \(A\) при условии, что случилось событие \(B\).↩︎
T-шкала (T-score) — одна из стандартных шкал, для которой среднее равно 50, а стандартное отклонение — 10.↩︎
Совпадение в данном случае всё же возможно ввиду того, что T-шкала дискретная, однако даже это совпадение может быть случайным, так как в тестовый балл входит также ошибка измерения, что подробнее обсуждается в курсе психометрики.↩︎