5 Нормальное распределение
Мы научились описывать эмпирическое распределение переменных — то есть распределение, которое получено на выборке. Но ведь в генеральной совокупности наши переменные тоже каким-то образом распределены. Уделим внимание и этому вопросу.
5.1 Распределение признаков в генеральной совокупности
Можем ли мы знать наверняка, как распределен признак в генеральной совокупности?
Нет.
Однако мы можем предполагать некоторое теоретическое распределение признака. На основе чего мы можем сделать такое предположение? Конечно же, на основе собранных данных, то есть на основании выборки. Большой выборки. Очень большой выборки. Большого количества очень больших выборок.
Теоретических распределений существует много — и они разные по форме, по параметрам, которыми они задаются, по величинам, которые ими можно описывать и т. д. Однако есть одно распределение, которое стало невероятно популярным и крайне широко используемым — нормальное распределение. Его мы и будем рассматривать.
5.2 Нормальное распределение
Тот факт, что некоторая величина распределена согласно закону нормального распределения (normal distribution), записывается следующим образом:
\[ X \thicksim \mathcal{N}(\mu, \sigma^2) \]
Здесь \(X\) — некоторая случайная величина (переменная), \(\mathcal{N}\) — обозначение нормального распределения, \(\mu\) и \(\sigma^2\) — параметры нормального распределения.
5.2.1 Параметры нормального распределения
Итак, в скобках указаны параметры распределения — как можно видеть, их всего два. На самом деле, мы их уже хорошо знаем:
- \(\mu\) — это не что иное, как среднее,
- \(\sigma^2\) — дисперсия.
Эти два параметра входят в формулу, описывающую график функции плотности вероятности нормального распределения:
\[ f(x) = \frac{1}{\sigma \sqrt{2\pi}} e ^{- \frac{(x-\mu)^2}{2 \sigma^2}}, \quad x \in \mathbb{R}, \mu \in \mathbb{R}, \sigma \in \mathbb{R}_{>0} \]
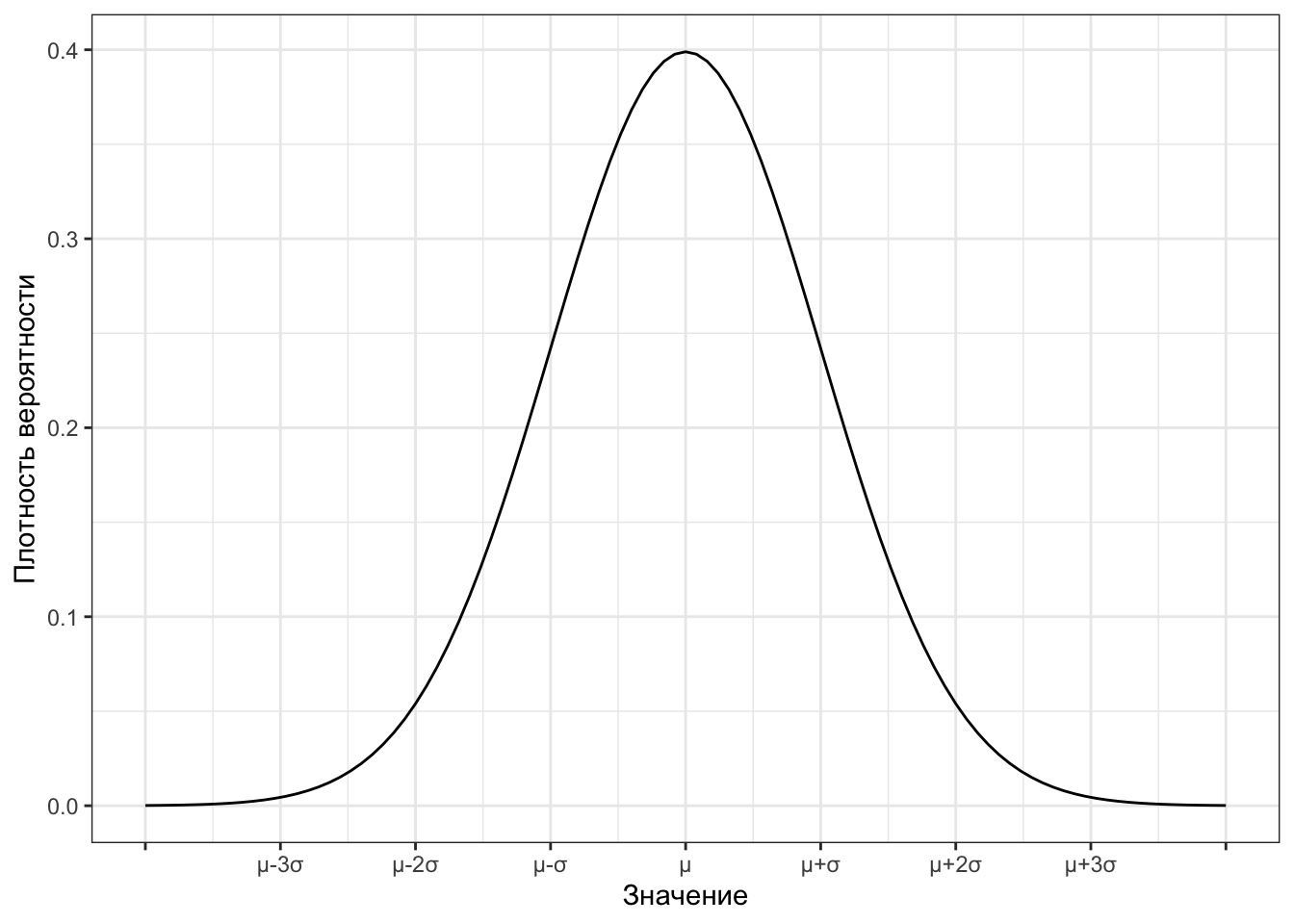
А сам график выглядит вот так:
И мы его уже тоже много раз видели.
Почему все так любят нормальное распределение?
- Его очень давно знают. Карл Фридрих Гаусс (1777–1855) исчерпывающе его исследовал, и теперь про это распределение известно всё. И ещё чуть более.
- Ряд статистических методов, называемых параметрическими,
требуют, чтобы распределение изучаемых переменных подчинялось нормальному закону.- Сейчас, строго говоря, это уже не совсем так. Появляются новые исследования и симуляции, показывающие, что это далеко не ключевое требование.
- С помощью нормального распределения определяют статистические нормы. Например, в образовательном тестировании, психодиагностике и иногда клинической практике.
- На основании нормального распределения рассчитывается стандартная ошибка среднего — важная оценка в статистике.
- На основании нормального распределения, а точнее — стандартной ошибки — рассчитываются доверительные интервалы среднего — одна из ключевых оценок в статистике.
5.2.2 Форма нормального распределения и параметры
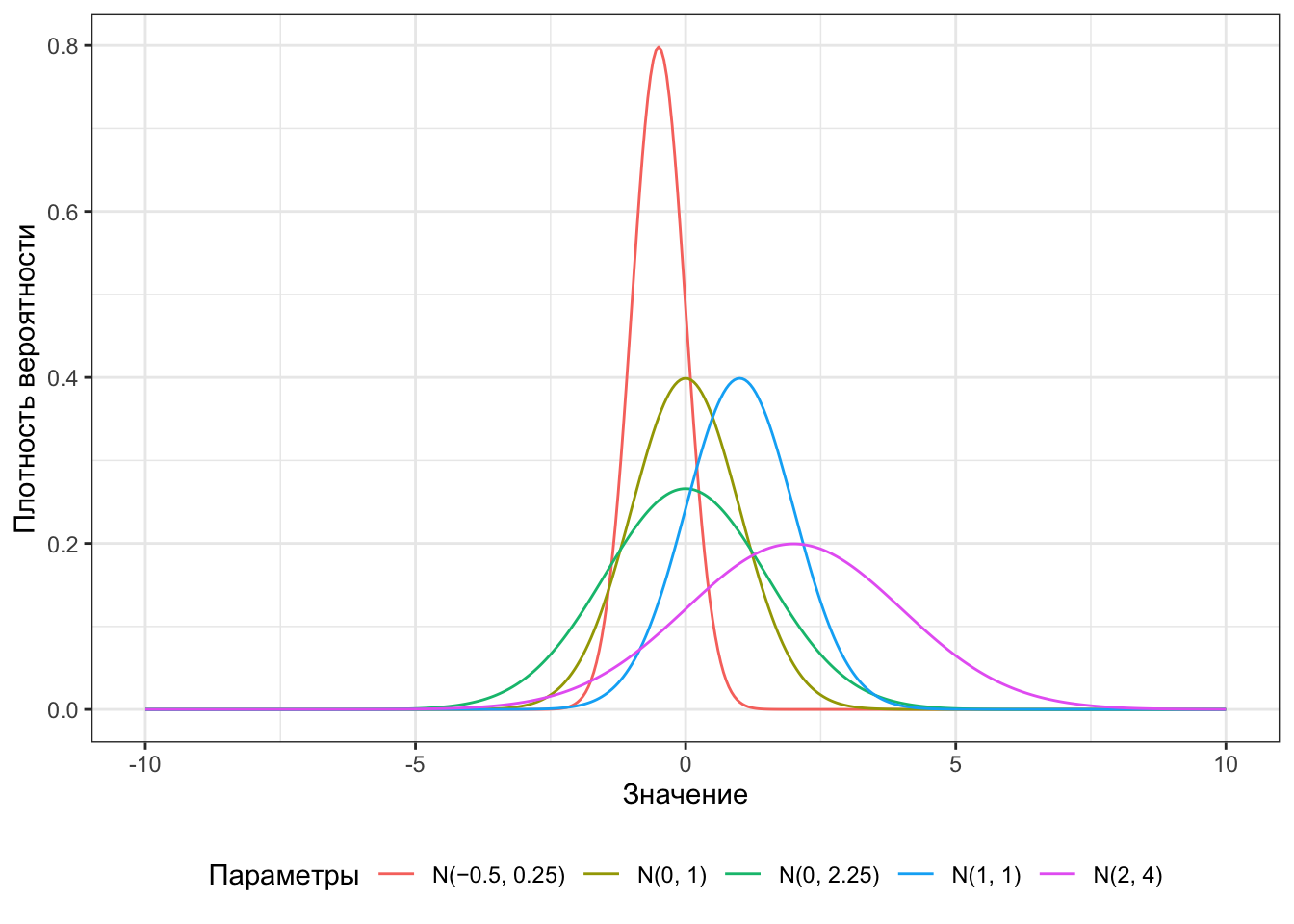
Очевидно, что раз у распределения есть какие-то параметры, значит они каким-то образом на него влияют. Не менее очевидно, что среднее \(\mu\) будет задавать положение центра колокола на оси \(x\), а дисперсия \(\sigma^2\) — ширину колокола. Ниже представлены несколько нормальных распределений c различными параметрами:
5.2.3 Стандартные отклонения и вероятности
Как уже упоминалось выше, нормальное распределение изучено вдоль и поперек. В том числе, посчитаны вероятности попадания значений в определенные интервалы. Вот они:
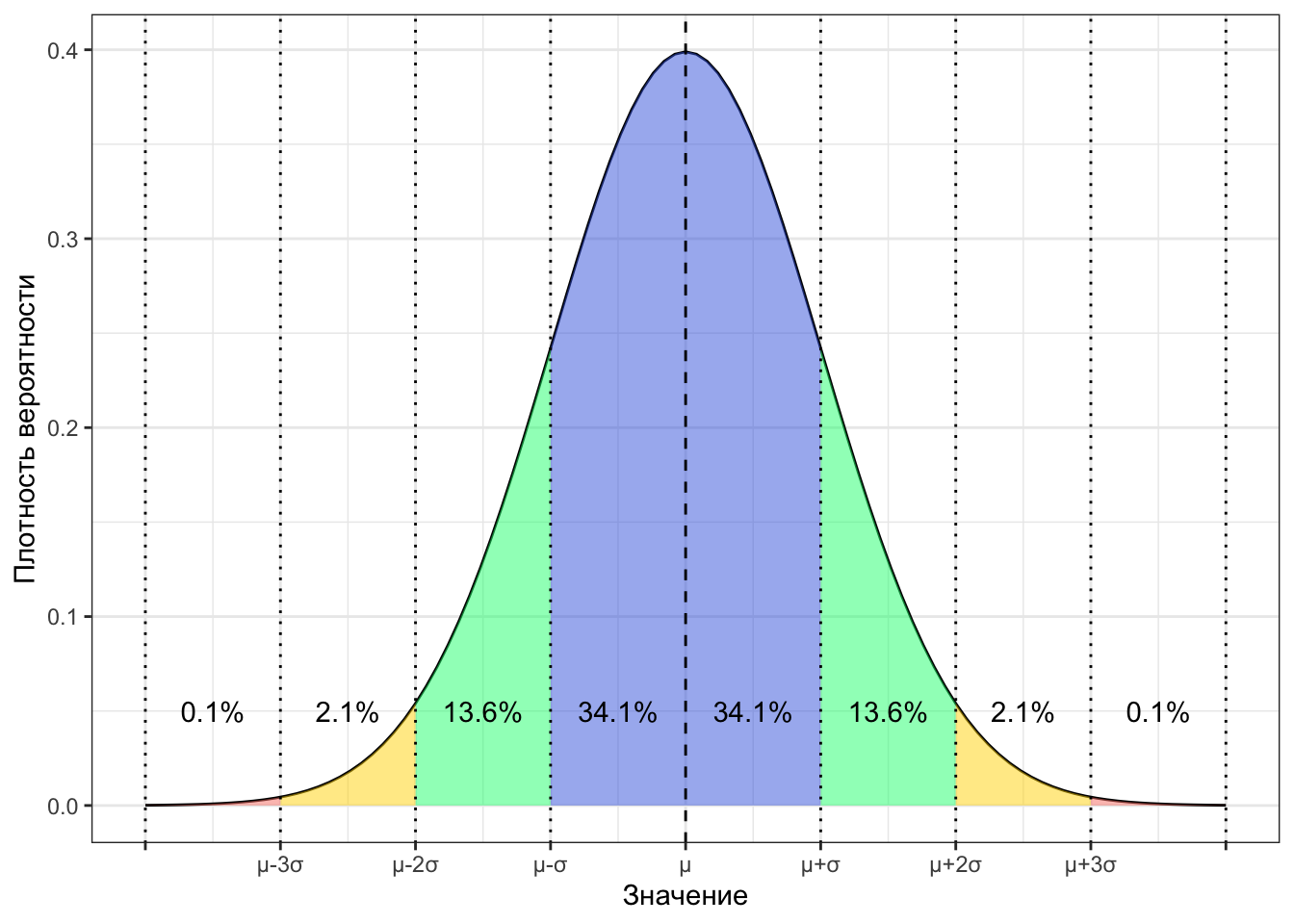
Конкретно с этими вероятностями мы работаем реже — полезнее оказывается знать следующие:
\[ \begin{split} &\mathbb{P} \big( X \in (\mu - \sigma, \mu + \sigma) \big) = 68.2\% \\ &\mathbb{P} \big( X \in (\mu - 2\sigma, \mu + 2\sigma) \big) = 95.6\% \\ &\mathbb{P} \big( X \in (\mu - 3\sigma, \mu + 3\sigma) \big) = 99.8\% \end{split} \tag{5.1}\]
То есть
- в пределах одного стандартного отклонения от среднего значения лежит почти 70% значений — это очень частотные значения;
- в пределах двух стандартных отклонений от среднего значения лежит 95% значений — бо́льшая часть выборки;
- в пределах трех стандартных отклонений от среднего значения лежит практически 100% выборки — практически вся выборка.
Что нам это дает?
- Во-первых, еще один способ определения выбросов (нехарактерных значений).
- Например, так как за границы двух стандартных отклонений попадает всего 5% значений, мы можем считать, что эти значения — нехарактерные и назвать их выбросами. - Либо же можем быть более либеральными и сказать, что выбросы для нас — значения, которые выходят за пределы трех стандартных отклонений. Главное обосновать, почему мы так считаем.
- Во-вторых, так мы можем определять статистические нормы.
- Например, мы разрабатываем клинический опросник (типа MMPI какого-нибудь), и нам надо выяснить, какие значения на шкалах итогового балла будут являться «нормой», а какие «патологией». Мы собираем большую репрезентативную выборку (скажем, по России или по странам СНГ), строим распределение итогового балла по каждой из шкал опросника, и определяем границы нормы — пусть это будет \(\mu \pm 3\sigma\).
- Теперь, когда новый респондент пройдет наш опросник, мы сможем сказать относительно его тестового балла, соответствует ли он нормативным границам или не соответствует.
- Отмечу еще раз: здесь мы говорим только о статистической норме — о таких значениях, которые чаще всего встречаются в выборке. Это только один из возможных вариантов определения нормы.
В целом, это всё, что нам надо знать про нормальное распределение.
5.3 Стандартизация
Нормальных распределение существует много, и пример тому Рисунок 5.2. Однако среди всех нормальных распределений одно выделяется особо.
5.3.1 Стандартное нормальное распределение
Нормальное распределение со средним \(0\) и дисперсией \(1\) называется стандартным нормальным распределением (standard normal distribution), или \(z\)-распределением. Значения на шкале такого распределения называются \(z\)-значениями.
\[ z \thicksim \mathcal{N}(0, 1) \]
Выглядит оно так:
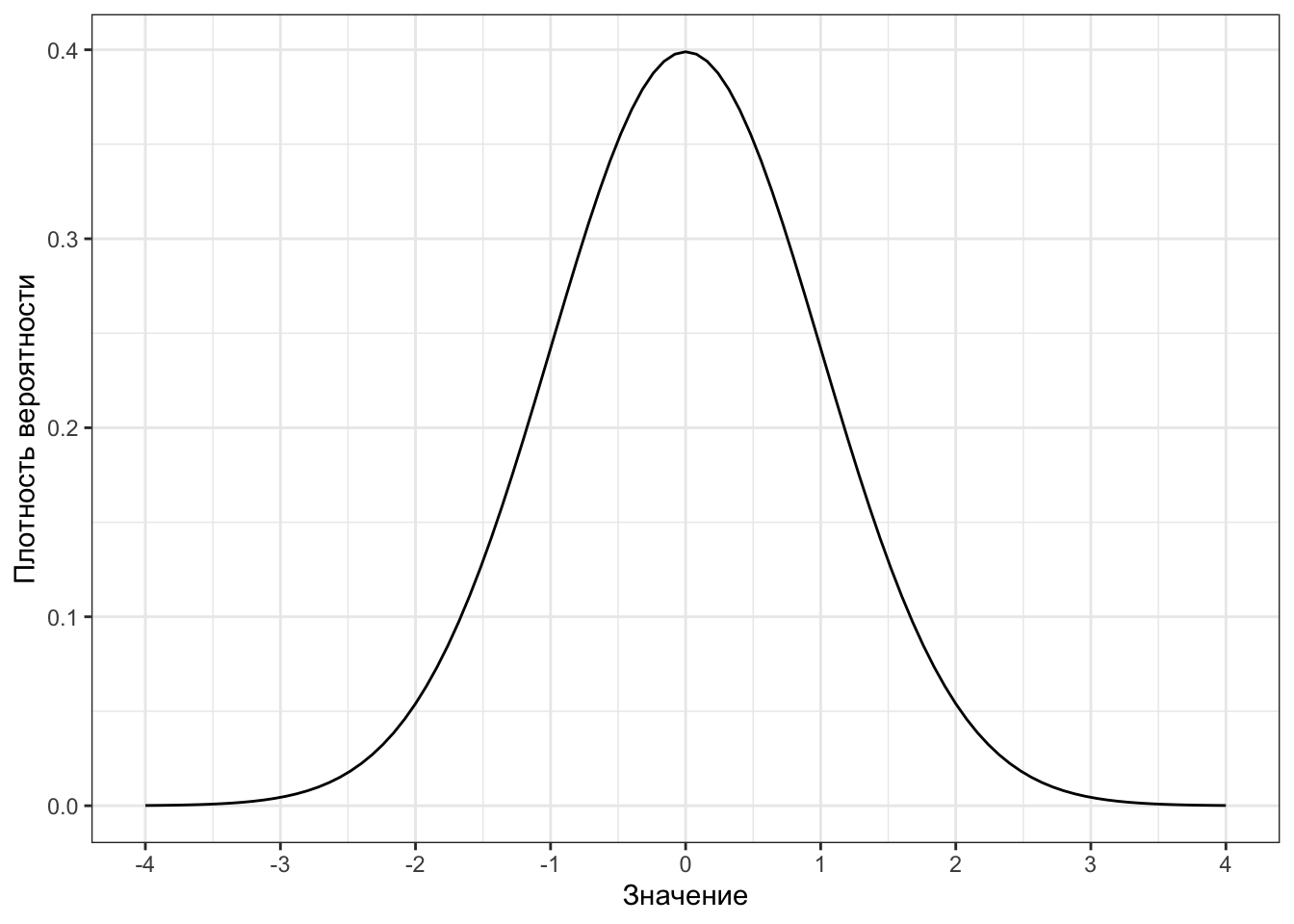
Разумеется, так как стандартное нормальное распределение является частным случаем нормального распределения, оно сохраняет все его свойства.
5.3.2 Стандартизация
Часто возникает следующая задача: нам нужно сравнить, например, баллы по шкалам двух опросников, при этом разброс баллов на шкале различный. Более того, сами распределения баллов по этим шкалам могут быть также различны.
Рассмотрим следующий пример. Мы дали респондентам два опросника на измерение личностных черт — BFI-2 (по модели «Большая пятерка») и SD3 (по модели «Тёмная триада»). Допустим, что мы хотим сравнить баллы некоторого респондента по шкалам Нейротизм из BFI-2 и Нарциссизм из SD3. Вопрос будет простой: по какой из двух шкал респондент набрал больший балл?
Данные говорят, что этот респондент набрал \(31\) балл по обеим шкалам. Собственно, а в чём тогда вопрос? Ясно же, что баллов набрано по обеим шкалам одинаково. Или всё же нет…
Шкалы BFI-2 состоят из двенадцати пунктов, а шкалы SD3 — из девяти. И даже учитывая, что отвечали респонденты в обоих случаях по пятибалльной шкале Ликерта, суммарный балл по шкалам опросника будет иметь разные пределы изменчивости (Рисунок 5.5). Описательные статистики — например, среднее и стандартное отклонение — будут также различны (Таблица 5.1).
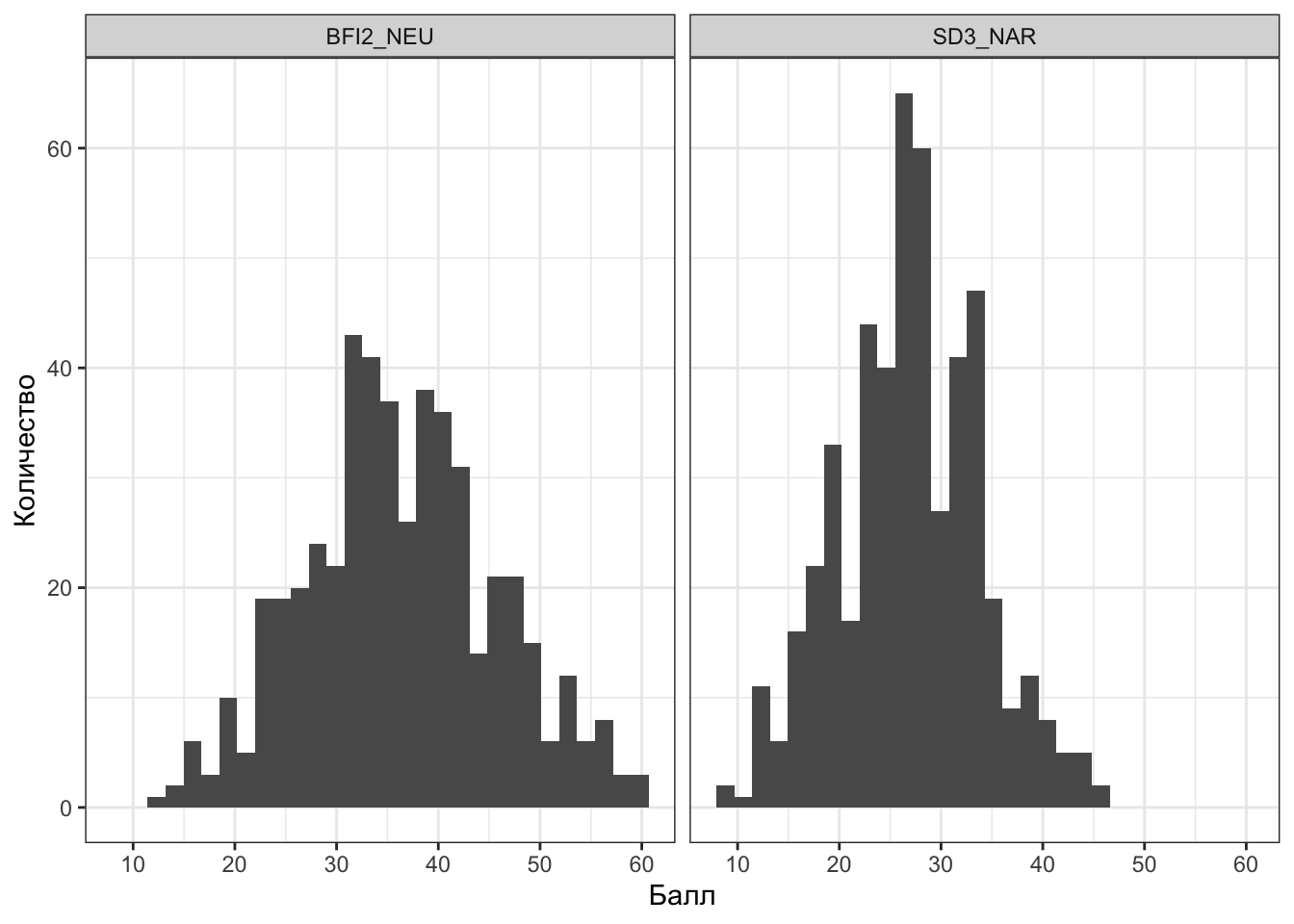
BFI2_NEU — шкала Нейротизм опросника BFI-2, SD3_NAR — шкала Нарциссизм опросника SD3.
BFI2_NEU — шкала Нейротизм опросника BFI-2, SD3_NAR — шкала Нарциссизм опросника SD3.
| Шкала | Количество пунктов | Количество респондентов | Среднее | Стандартное отклонение |
|---|---|---|---|---|
BFI2_NEU |
12 | 492 | 36.34 | 9.41 |
SD3_NAR |
9 | 492 | 26.94 | 6.95 |
В силу разного разброса значение одни и те же значения будут находится в разных частях распределений. В частности, внимательно присмотревшись к описательным статистикам (Таблица 5.1) можно заметить, что значение \(31\) меньше среднего для шкалы BFI2-NEU и больше среднего для шкалы SD3_NAR. Это, безусловно, полезная информация, однако хотелось бы найти какой-то единый способ для сравнения значений из различных распределений. Такой способ есть — нам необходимо стандартизировать случайный величины.
Определение 5.1 Стандартизация — преобразование случайной величины, в результате которого среднее её распределения становится равным \(0\), а стандартное отклонение — \(1\).
\[ z_i = \frac{x_i - \overline X}{s_X}, \tag{5.2}\]
где \(z_i\) — значение стандартизированной случайной величины, \(x_i\) — значение исходной случайной величины, \(\overline X\) — среднее исходной случайной величины, \(s_X\) — стандартное отклонение исходной случайной величины.
Полученные стандартизированные значения также часто называют \(z\)-значениями. В этом есть довольно понятный смысл, ведь если изначально переменная была распределена нормально — \(X \thicksim \mathcal{N}(\mu, \sigma^2)\) — то стандартизированная случайная величина будет подчиняться стандартному нормальному распределению — \(z \thicksim \mathcal{N}(0, 1)\).
Посмотрим на процедуру стандартизации детально, благо деталей всего две — числитель и знаменатель (см. Уравнение 5.2). Стандартизация состоит из двух операций:
- центрирование — то, что происходит в числителе — обращает среднее в ноль (см. Утверждение 3.1),
- нормирование — то, что происходит в знаменателе — обращает стандартное отклонение в единицу (см. Следствие 4.2).
Посмотрим на две операции отдельно на примере стандартизации какого-то нормального распределения.
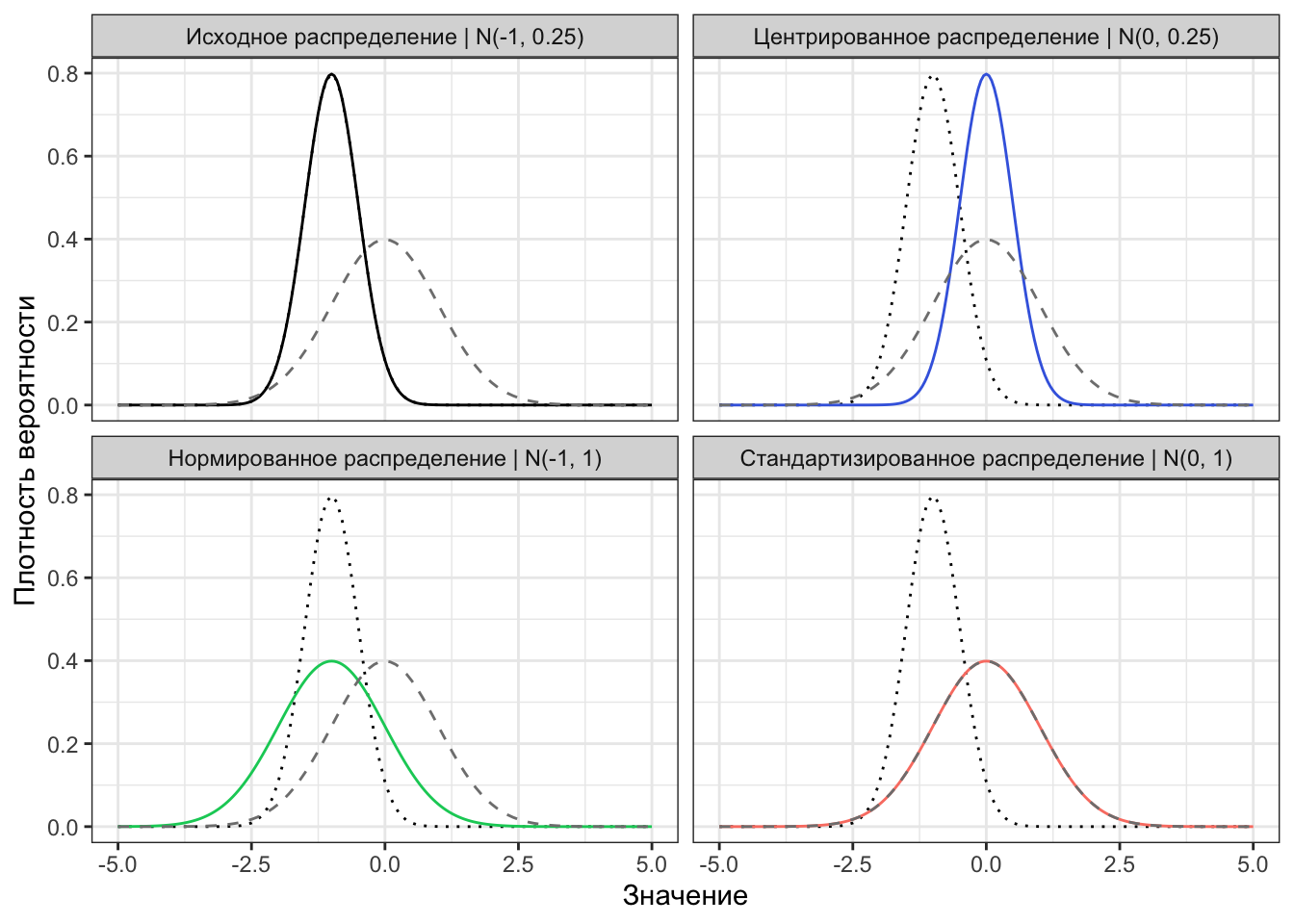
На рисунке 5.6 черной линией представлено исходное нормальное распределение \(\mathcal{N}(-1,0.25)\) [слева сверху]. Если его центрировать, то оно подвинется вправо — \(x_i - \overline X\) — и получится синее распределение \(\mathcal{N}(0, 0.25)\) [справа сверху]. Если нормировать исходное распределение, то оно станет несколько шире — \(\frac{x_i}{s_X}\) — как зелёное \(\mathcal{N}(-1,1)\) [слева снизу]. А если осуществить обе операции вместе — \(\frac{x_i - \overline X}{s_X}\) — это и будет стандартизация, и распределение совпадет сo стандартным нормальным распределением [справа снизу].
Стандартизация не меняет форму распределения!
В реальной ситуации никто не может нам гарантировать, что выборочное распределение обязательно будет нормальным. Вообще-то на выборке может случится всё, что угодно.
Иногда можно услышать такое утверждение: «стандартизация приводит произвольное распределение к стандартному нормальному» — что совершеннейшая неправда. Вернитесь к определению 5.1 и убедить, что там нет ни слова про нормальность распределений.
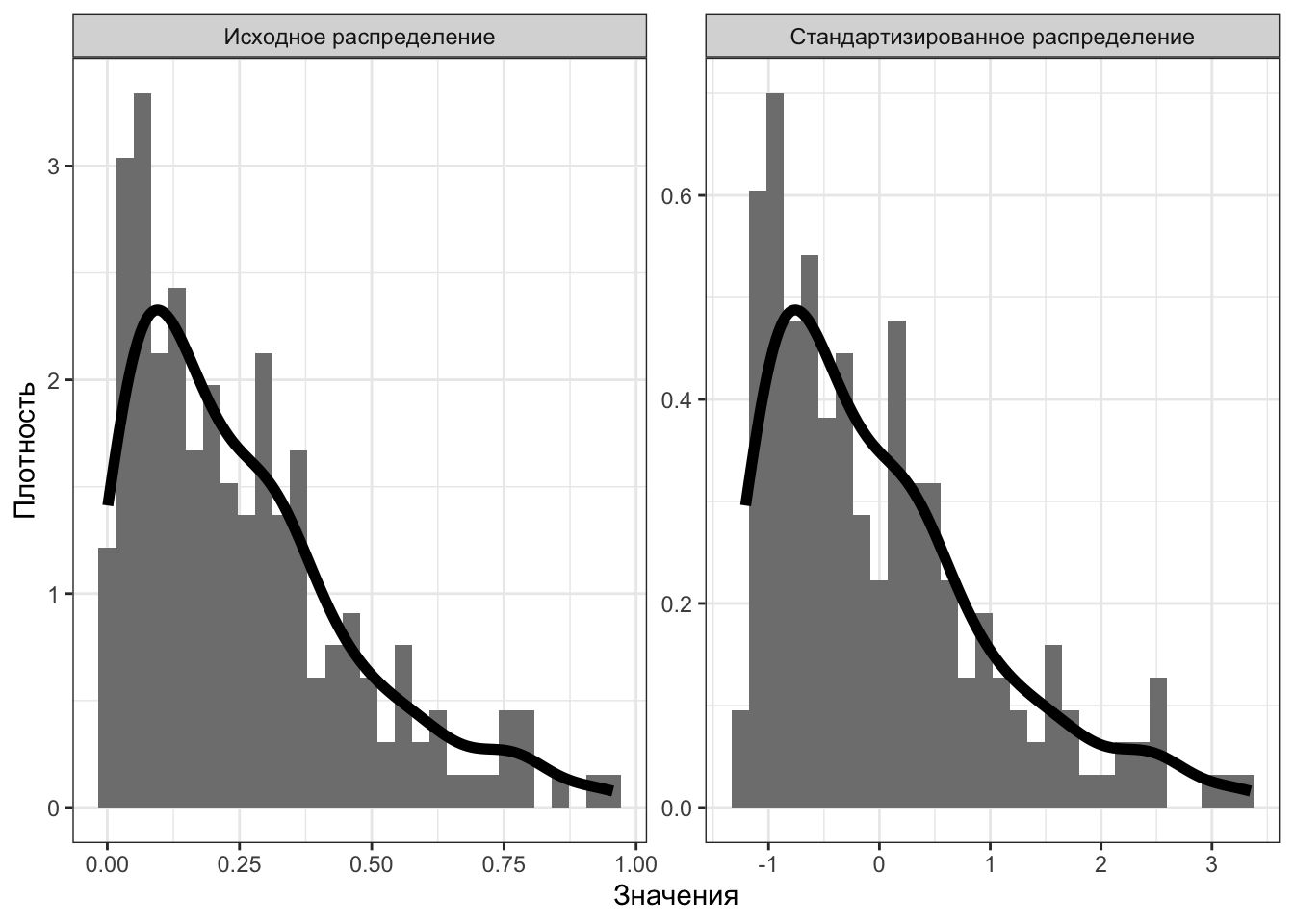
Рассмотрим пару примеров. Пусть исходное распределение асимметрично (Рисунок 5.7). Стандартизировав его, мы получим распределение со средним \(0\) и стандартным отклонением \(1\), однако его форма совершенно не изменилась.
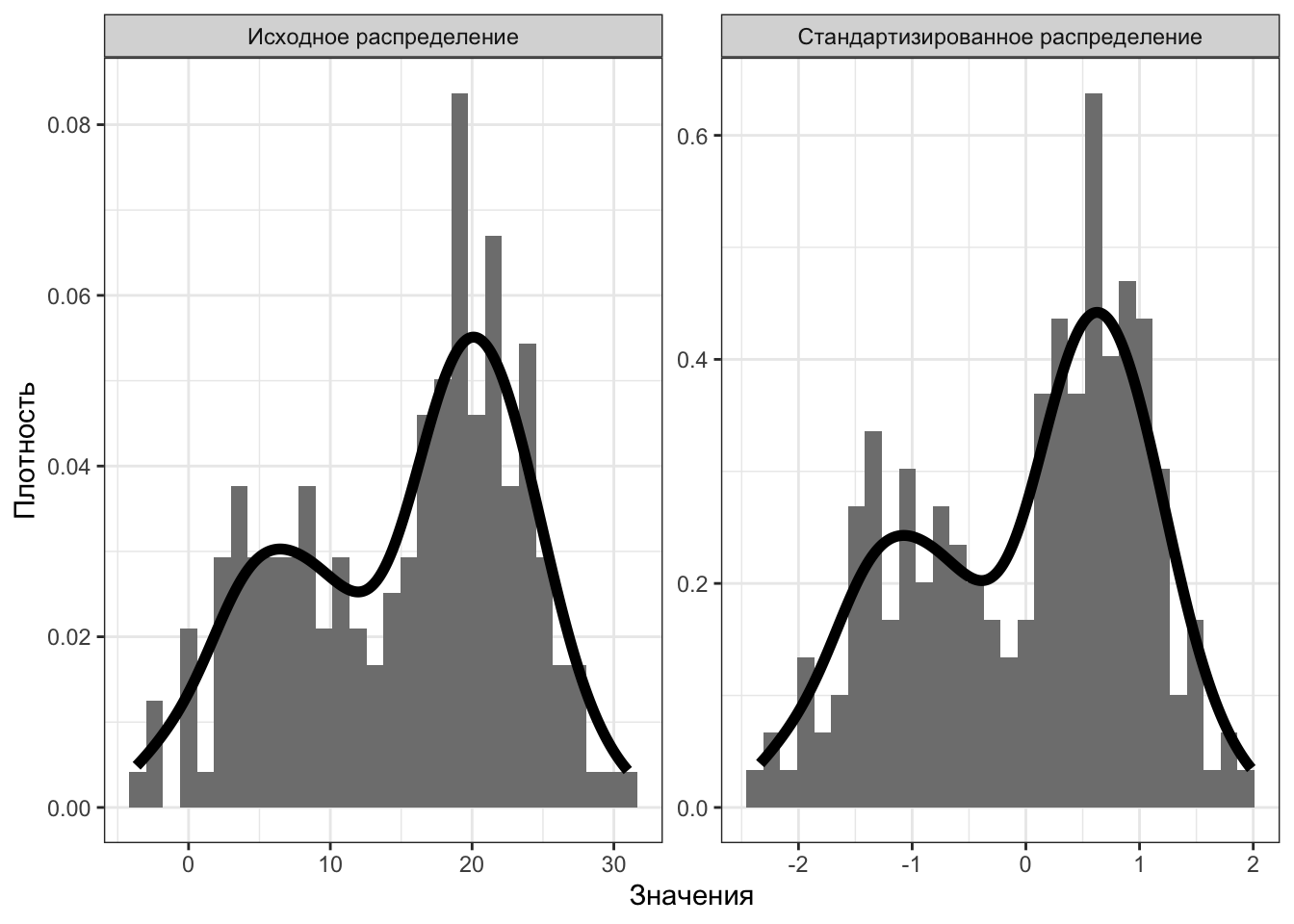
Теперь возьмем бимодальное распределение, и пронаблюдаем ровно ту же ситуацию — форма распределения вновь не изменилась (Рисунок 5.8).
Вернёмся же, наконец, к нашей исходной задаче: мы собирались ответить на вопрос по какой из двух шкал респондент набрал больший балл, при этом данные нам говорят, что респондент набрал \(31\) балл по обеим шкалам. Найдём стандартизированное значение по формуле 5.2 взяв значения среднего и стандартного отклонения из таблицы 5.1. Получим
\[ z_\mathrm{BFI2.NEU} = \frac{31 - 36.34}{9.41} \approx -0.57 \] \[ z_\mathrm{SD3.NAR} = \frac{31 - 29.94}{6.95} \approx 0.58 \]
Таким образом, мы можем сказать, что наш респондент набрал более высокий балл по шкале нарциссизма.
5.3.3 Интерпретация z-значений
Хорошо, мы сделали стандартизацию — довольно простая процедура. Но как с этими числами дальше работать? Можно ли из них выжать больше смысла, чем просто сравнение?
Здесь надо понять всего одну вещь:
Конечно, \(z\)-шкала безразмерная, то есть не имеет единиц измерения (метры, секунды, года и др.). Однако единица — в смысле \(1\) — на этой шкале небессмысленна. Это мера типичности.
Взглянем ещё раз на рисунок 5.4. Обратим внимание вот на что: \(1\), \(2\) \(3\) и \(-1\), \(-2\), \(-3\) находятся в тех самых точках, где в другом нормальном распределении находятся стандартные отклонения (\(\mu \pm \sigma\), \(\mu \pm 2\sigma\), \(\mu \pm 3\sigma\)). Мы также знаем, что этим диапазонам соответствуют вероятности, с которыми значения случайных величин оказываются в этих диапазонах (Уравнение 5.1).
То есть мы можем говорить, что \(z\)-значения
- в интервале \((-1,1)\) — очень типичные, поскольку лежат в пределах одного стандартного отклонения от среднего,
- в интервалах \((-2, -1)\) и \((1,2)\) — тоже достаточно типичные, поскольку лежат в пределах двух стандартных отклонений от среднего,
- в интервалах \((-3, -2)\) и \((2,3)\) — менее типичные, но еще «нормальные», так как лежат в пределах трёх стандартных отклонений от среднего,
- меньшие \(-3\) и большие \(3\) — очень нетипичные, так как выходят за пределы трёх стандартных отклонений от среднего.
Это и есть мера типичности.
Таким образом, с помощью \(z\)-значений мы можем быстро понять, где находится испытуемый или респондент на имеющемся распределении.
Можно ли это понять без перевода значений в \(z\)-шкалу? Можно. Но неудобно. Надо держать в голове среднее и стандартное отклонение конкретного распределения, а если сравниваем респондентов по нескольким шкалам, то по две характеристики для каждой шкалы, постоянно пересчитывая диапазоны — в общем, слишком много инфы. Трудно.
5.3.4 Применение стандартизации
Помимо обсужденного выше, есть ещё одно применение \(z\)-значений. От них можно перейти к значениям любой другой стандартной шкалы, выполнив преобразование, обратное 5.2. Стандартных шкал существует много — Sten, Stanine, T-score, IQ-score… С ними вы познакомитесь в курсе психометрики. Они оказываются очень удобными для представления результатов тестов конечным пользователям. Однако для того, чтобы перейти к этим шкалам, сначала все равно будет необходимо перейти к \(z\)-значениям.
Кроме того, стандартизация также используется в некоторых статистических методах, когда нам необходимо уравнять дисперсии переменных. Поскольку после стандартизации дисперсия переменной всегда будет равна единице, такая процедура отлично подходит для этой задачи.