4 Меры разброса
Итак, мы разобрались с мерами центральной тенденции. Однако для описания распределения их оказывается недостаточно. Почему?
4.1 Зачем нужны меры разброса
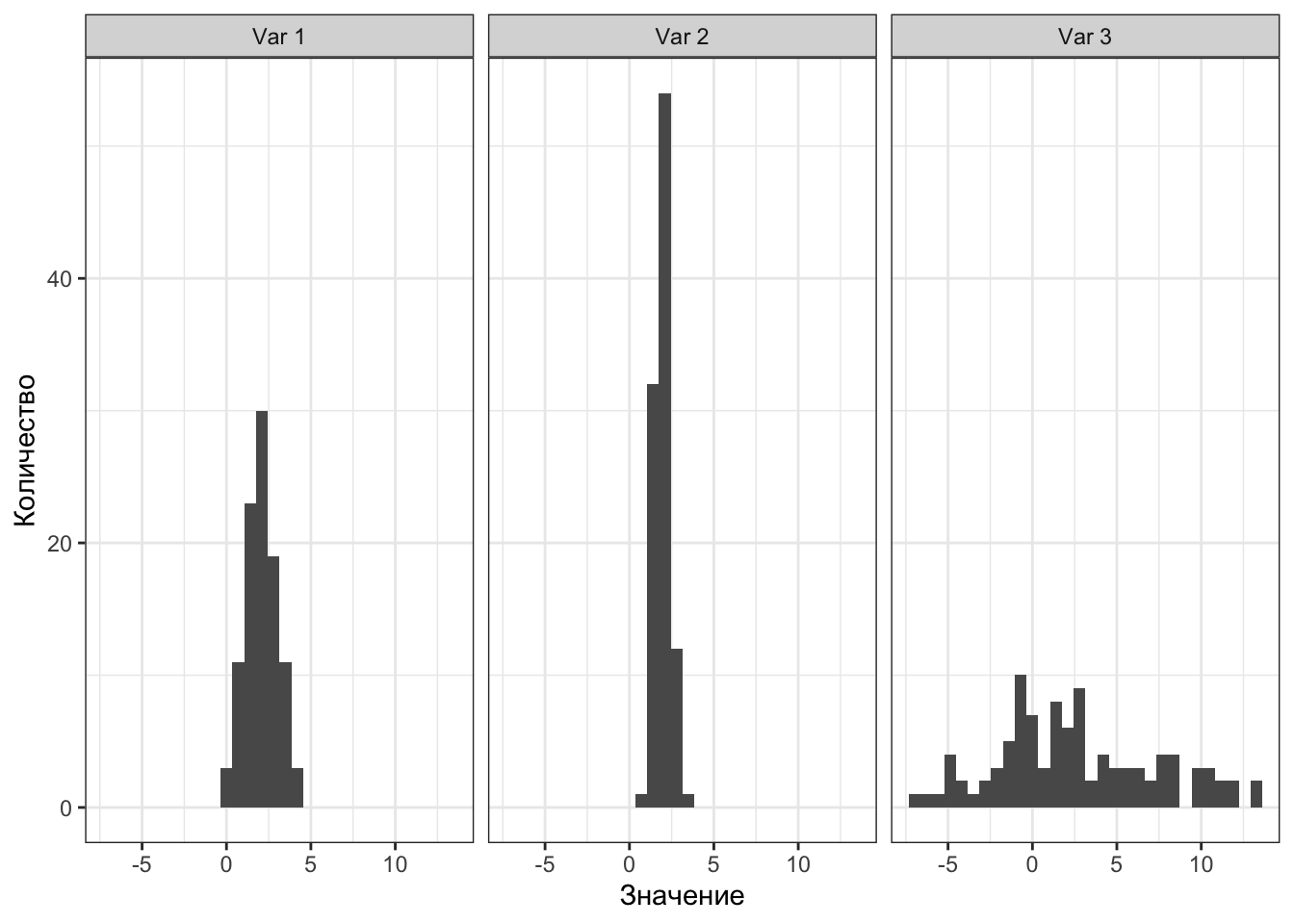
Посмотрим на несколько распределений:
Методом пристального взгляда можно установить, что у всех распределений одинаковые средние:
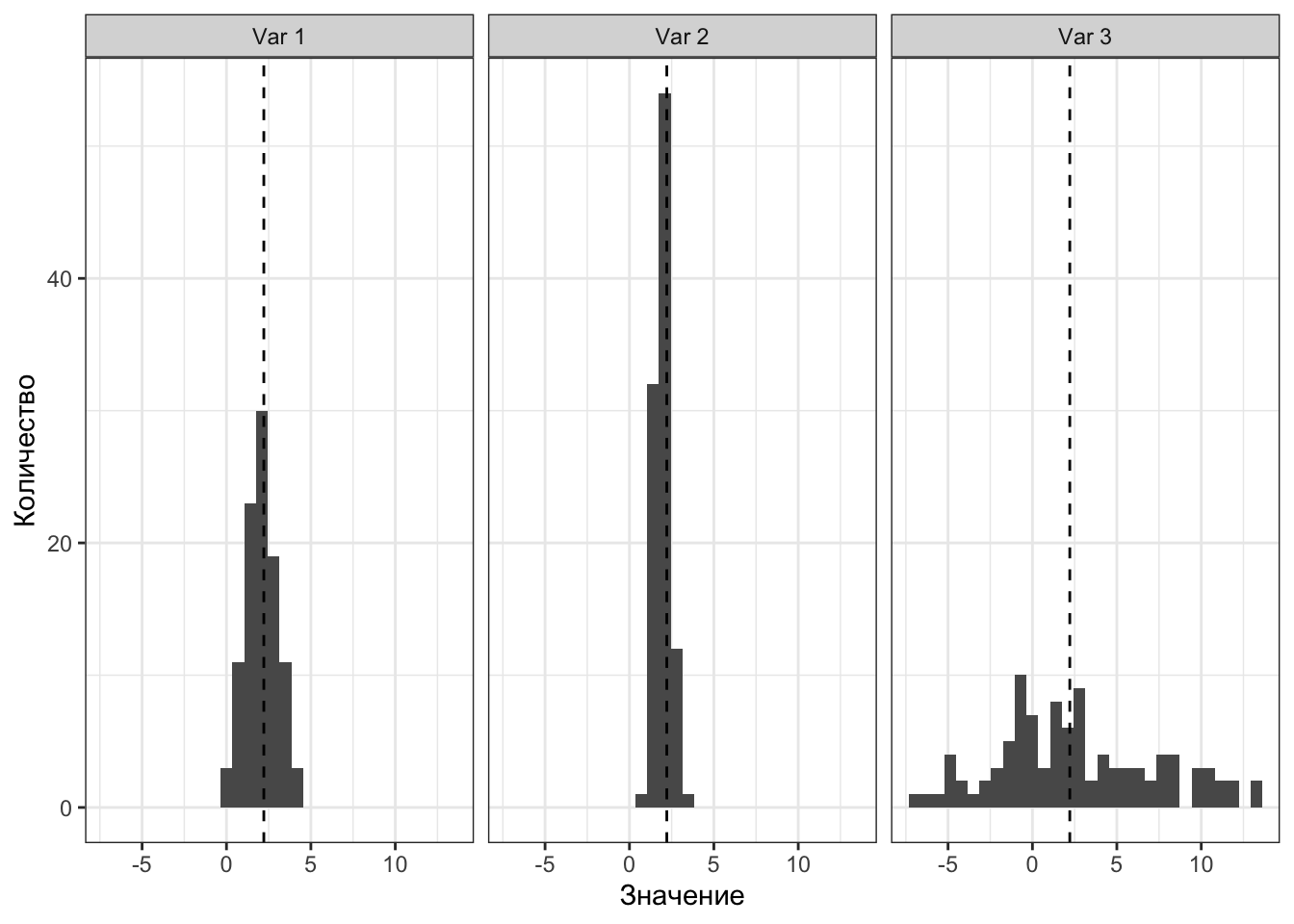
Однако мы видим, что значения по-разному группируются вокруг среднего. Как они группируются — плотно, как на втором рисунке, или не особо, как на третьем — можно описать с помощью мер разброса, или мер вариативности.
4.2 Основные характеристики статистических данных
Вообще если посмотреть на это более свысока, то необходимость описания разброса определяется тем, что статистические данные обладают двумя ключевыми особенностями — неопределенностью и вариативностью.
- Неопределённость нам говорит о том, что мы не знаем, что именно мы получим в результате наших измерений для конкретной выборки. В том числе потому, что мы работаем на просторах случайных величин.
- Вариативность означает, что наши данные будут различаться ещё и от респондента к респонденту. И между выборками тоже. Здесь и ошибка измерения, и различные смешения и ещё куча всего.
Более того, вариативность есть главное условие применения статики, поскольку она входит в расчёт любого статистического критерия. Если у переменной отсутствует вариативность, статистика на ней работать не будет.
4.3 Минимум, максимум, размах
Начнем с самого простого. Как наиболее просто описать вариативность? Мы работаем с выборкой, а в выборке, как известно, ограниченное число наблюдений. А если оно ограниченное, значит среди них точно есть наибольшее — максимум (max) — и наименьшее — минимум (min).
Допустим, мы открыли ведомость по «Анатомии и физиологии ЦНС» некоторой академической группы и пронаблюдали следующее:
[1] 7 4 6 9 10 5 6 9 6 6 3 6 8 8 5 10 7 5 7 3 9 4 8 3 8
[26] 4 6 8 7 5Мы можем посчитать минимальное и максимальное значение по этому ряду наблюдений — они окажутся равны соответственно 3 и 10. То есть оценки по этой дисциплине варьируются от 3 до 10. Ну, чу́дно.
Разница между максимальным и минимальным значением называется размах (range):
\[ \text{range}(X) = \max(X) - \min(X) \]
В примере выше он будет равен 7.
И вот мы преисполнившиеся сим знанием идёт описывать вариативность переменной с помощью размаха, но обнаруживаем в другой ведомости этой же группы (по «Введению в психологию») вот что:
[1] 6 8 4 6 7 5 7 10 4 6 7 8 7 6 8 10 8 7 7 6 8 7 6 8 6
[26] 3 8 6 6 4Минимум, максимум и размах вроде как такие же: 3, 10 и 7 соответственно.
Значит ли это, что вариативность одинаковая? Нарисуем.
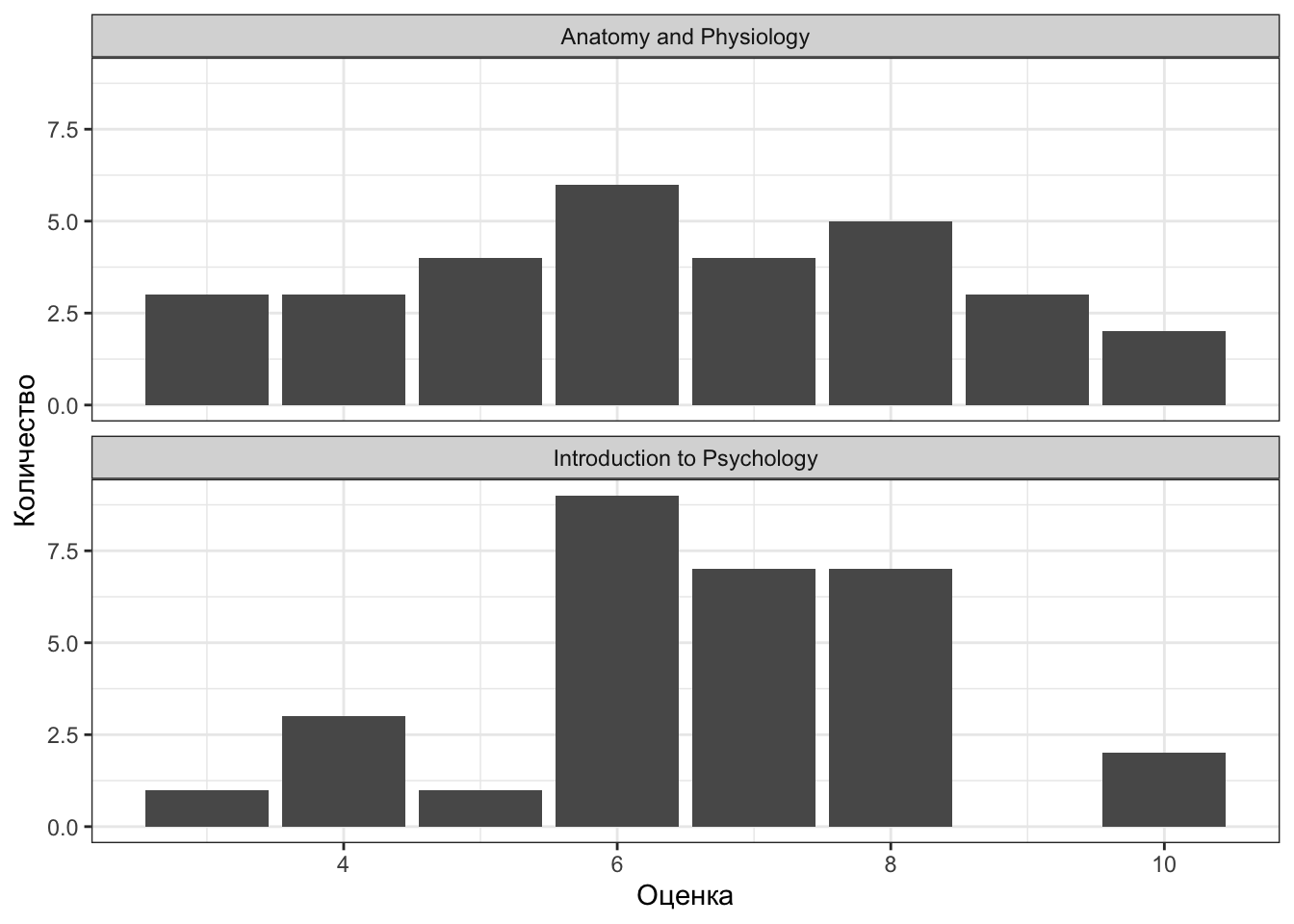
Кажется, что вариативность различна. Распределение оценок по «Анатомии и физиологии ЦНС» более равномерное, в то время как оценки по «Введению в психологию» активнее группируются где-то в середине.
Штош, размах хоть и дает нам некоторую информацию о вариативности, нам этого маловато. Будем искать другие меры разброса.
4.4 Квантили
Возьмем распределение суммарного балла по шкале толерантности к неопределенности. Выглядит оно как-то так:
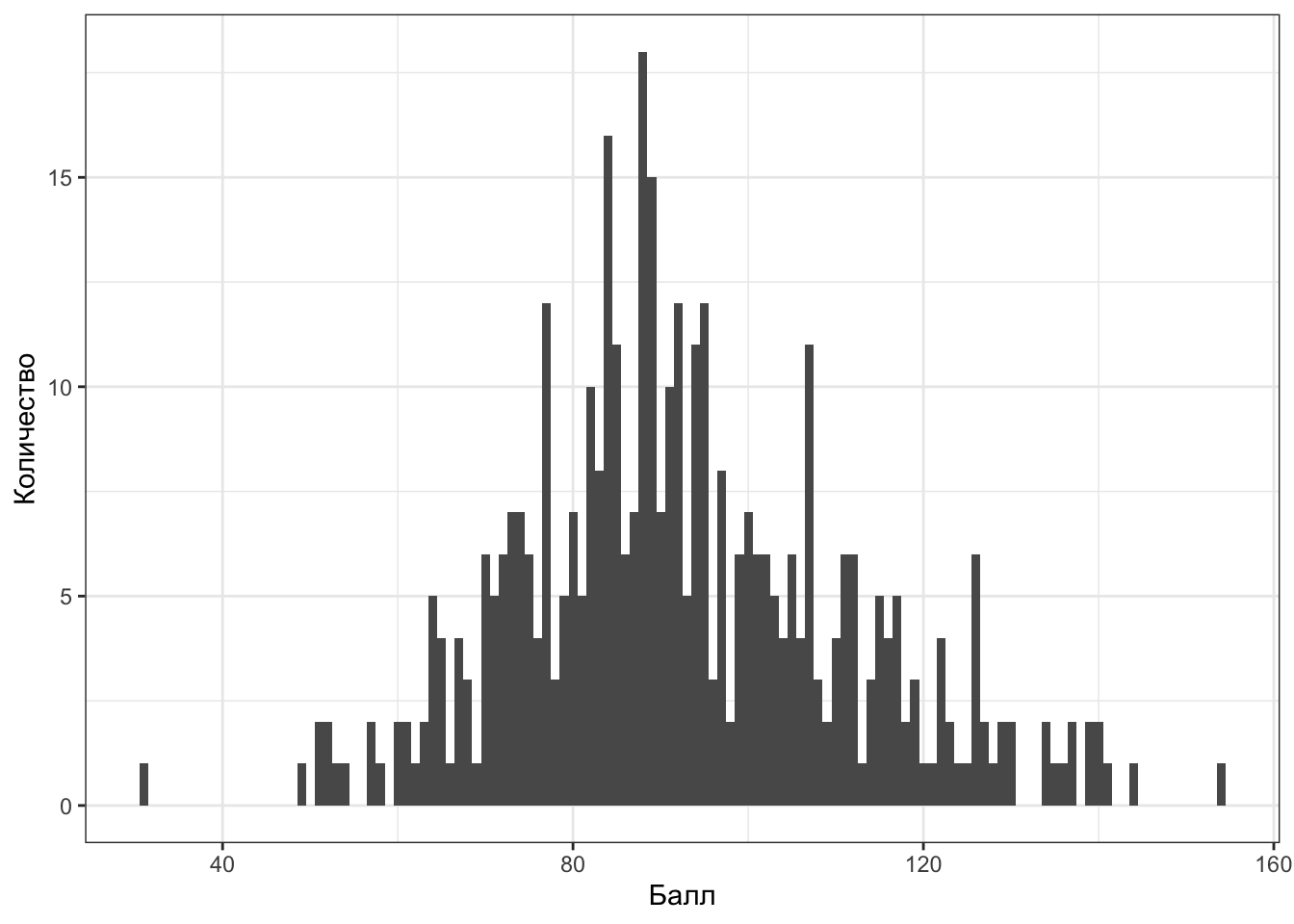
Теперь нам понадобится определение квантиля распределения.
Определение 4.1 Квантиль (quantile) — это значение переменной, которое не превышается с определенной вероятностью.
Обозначим эту вероятность \(p\). Тогда можно сказать, что квантиль уровня \(p\) — это такое значение переменной, слева от которого лежит \(p\%\) наблюдений.
Посмотрим на картинки.
Слева относительно квантиля-0.05 (\(x_{0.05}\)) лежит 5% наблюдений:
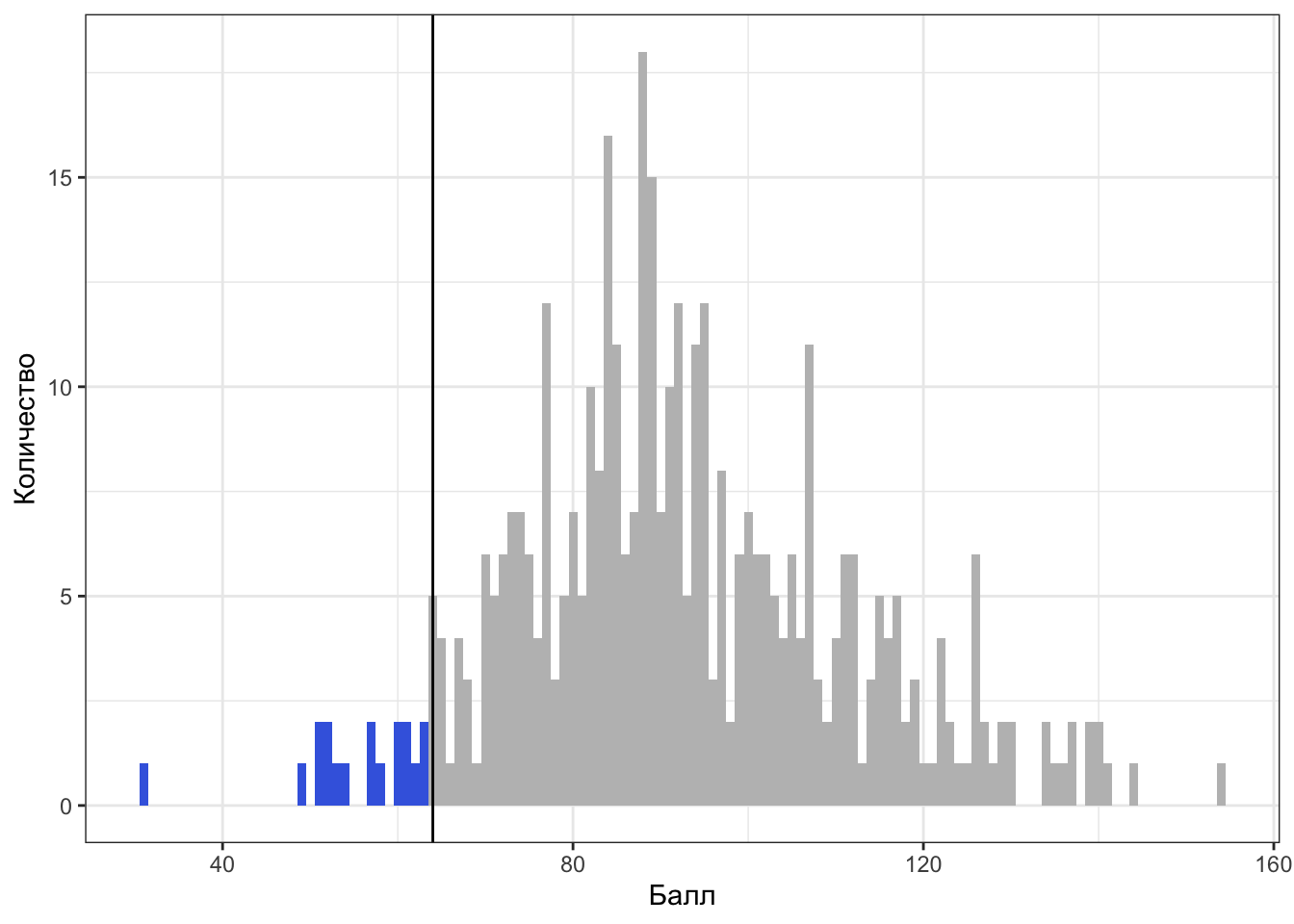
Слева относительно квантиля-0.68 (\(x_{0.68}\)) лежит 68% наблюдений:
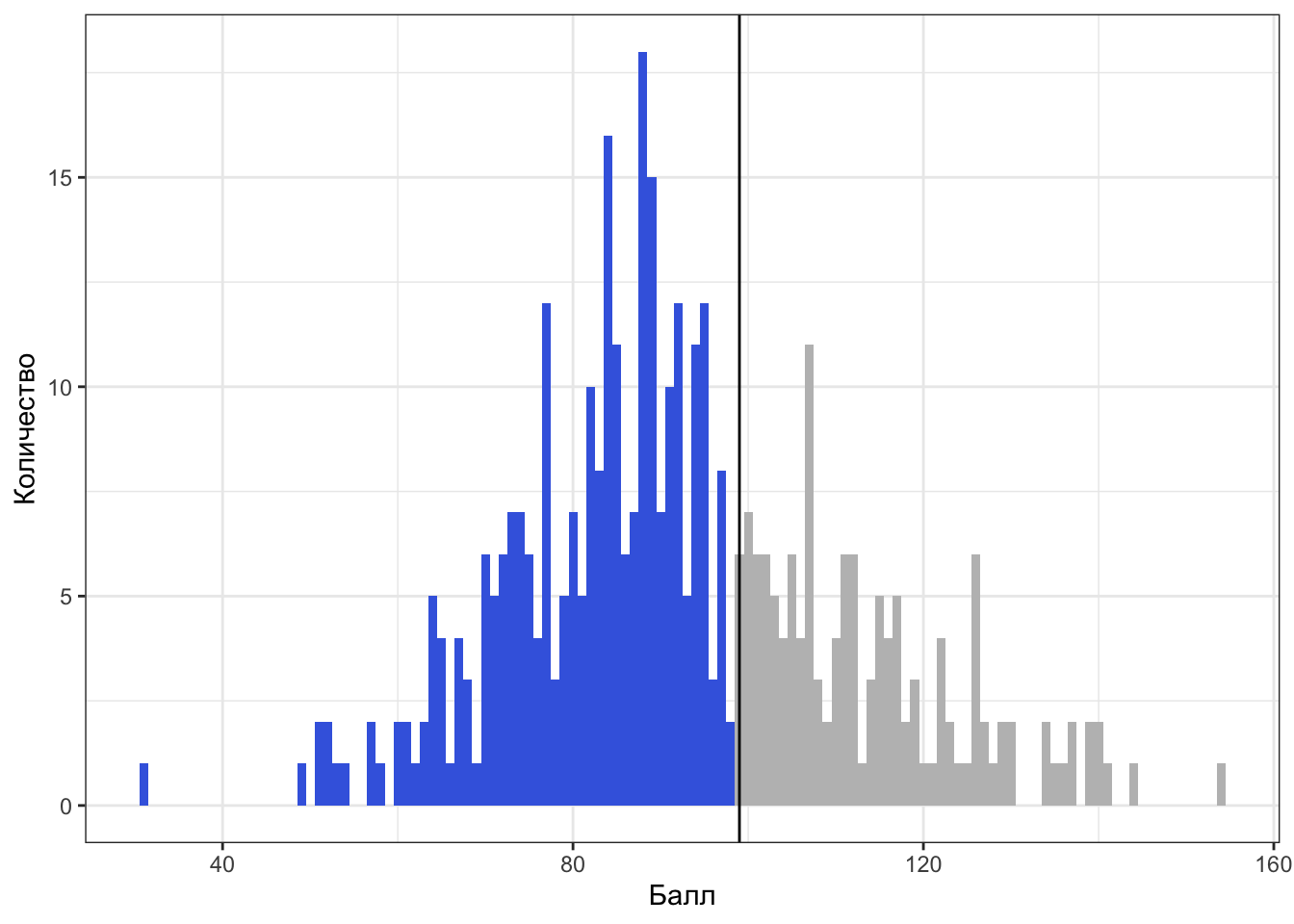
Слева относительно квантиля-0.99 (\(x_{0.99}\)) лежит 99% наблюдений:
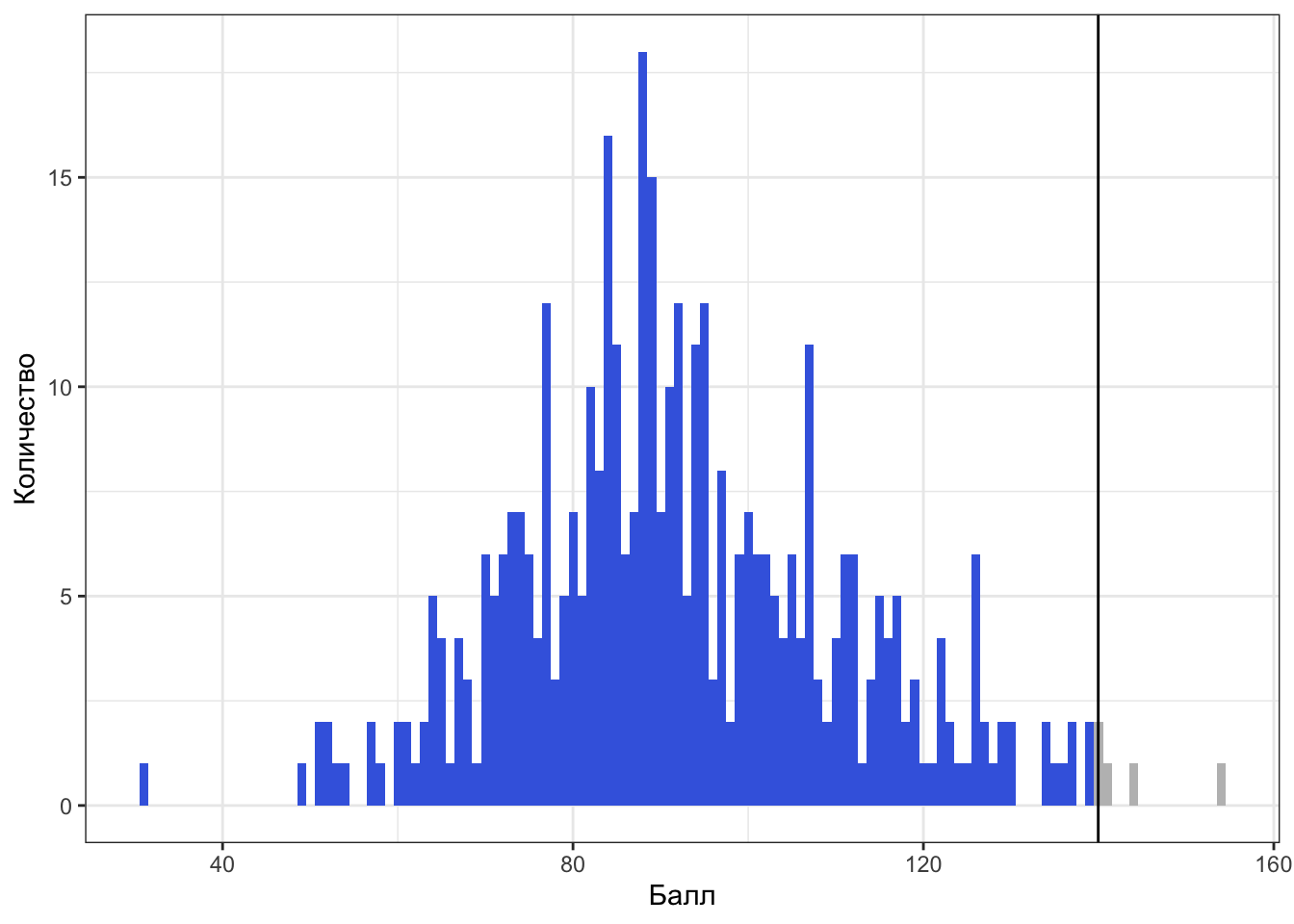
Итак, мы поняли, а также приняли и осознали, что такое квантиль. Неясно только, как он нам поможет описать вариативность данных.
4.4.1 Квартили
Для этого нам пригодятся специально обученные квантили. Оказалось достаточно удобно поделить все наблюдение на четыре равные части — вот так:
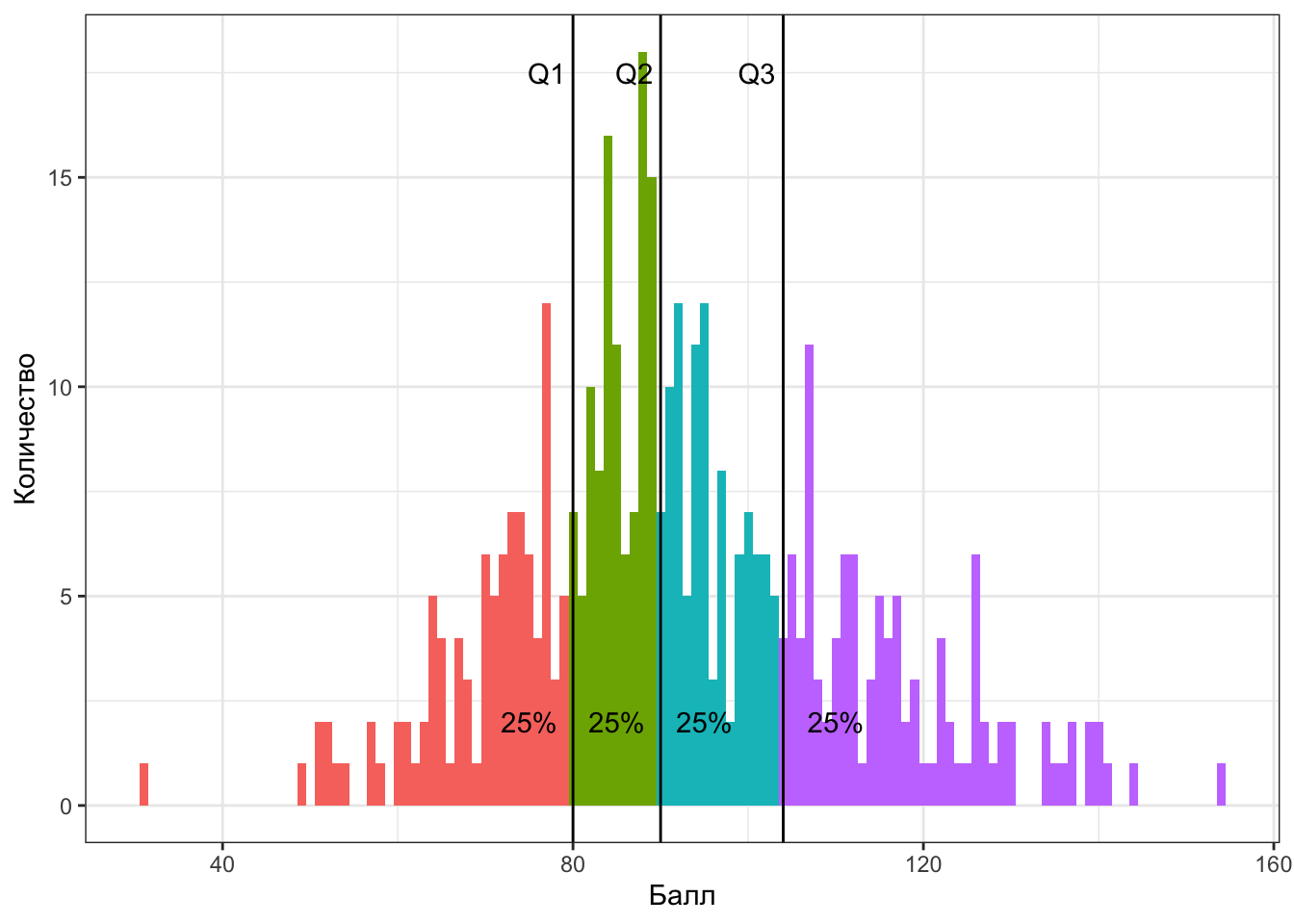
Значения переменной, которые делят выборку на четыре равные части называются квартили (quartile). Получается, что
- слева от первого (нижнего) квартиля (\(\text{Q1}, x_{0.25}\)) лежит 25% наблюдений
- слева от второго (среднего) квартиля (\(\text{Q2}, x_{0.50}\)) лежит 50% наблюдений
- а значит и справа 50%: получается второй квартиль делит выборку пополам — это медиана
- слева от третьего (верхнего) квартиля (\(\text{Q3}, x_{0.75}\)) лежит 75% наблюдений
Четвертый квартиль не используется, потому что является максимальным значением — слева от него лежит 100% наблюдений.
Кстати, можно также отметить, что первый квартиль — это медиана нижней (меньшей) половины наблюдений, а третий — медиана верней (большей) половины наблюдений.
Вот такая вот прикольная история.
4.4.2 Децили
К слову, делить выборку можно не только на четверти — можно поделить, скажем, на 10 частей и получить децили. Так, слева от первого дециля (\(x_{0.10}\)) лежит 10% наблюдений, а слева от третьего (\(x_{0.30}\)) — 30%.
Децили встречаются редко (в основном в психометрике), но знать о них полезно.
4.4.3 Перцентили
Гораздо чаще встречаются перцентили — значения переменной, которые делят выборку на 100 равных частей. Например, так устроен ваш рейтинг. Только стоит помнить, что в рейтинге отсчет ведется от максимального GPA, поэтому если у вас нулевой перцентиль (\(x_{0.00}\)) по программе, значит выше вас в рейтинге никого нет. А если ваш перцентиль, скажем, 36-ой (\(x_{0.36}\)), то выше вас в рейтинге 36% ваших однокурсников, то есть вы все ещё в первой половине рейтинга, что очень неплохо!
4.5 Интерквартильный размах
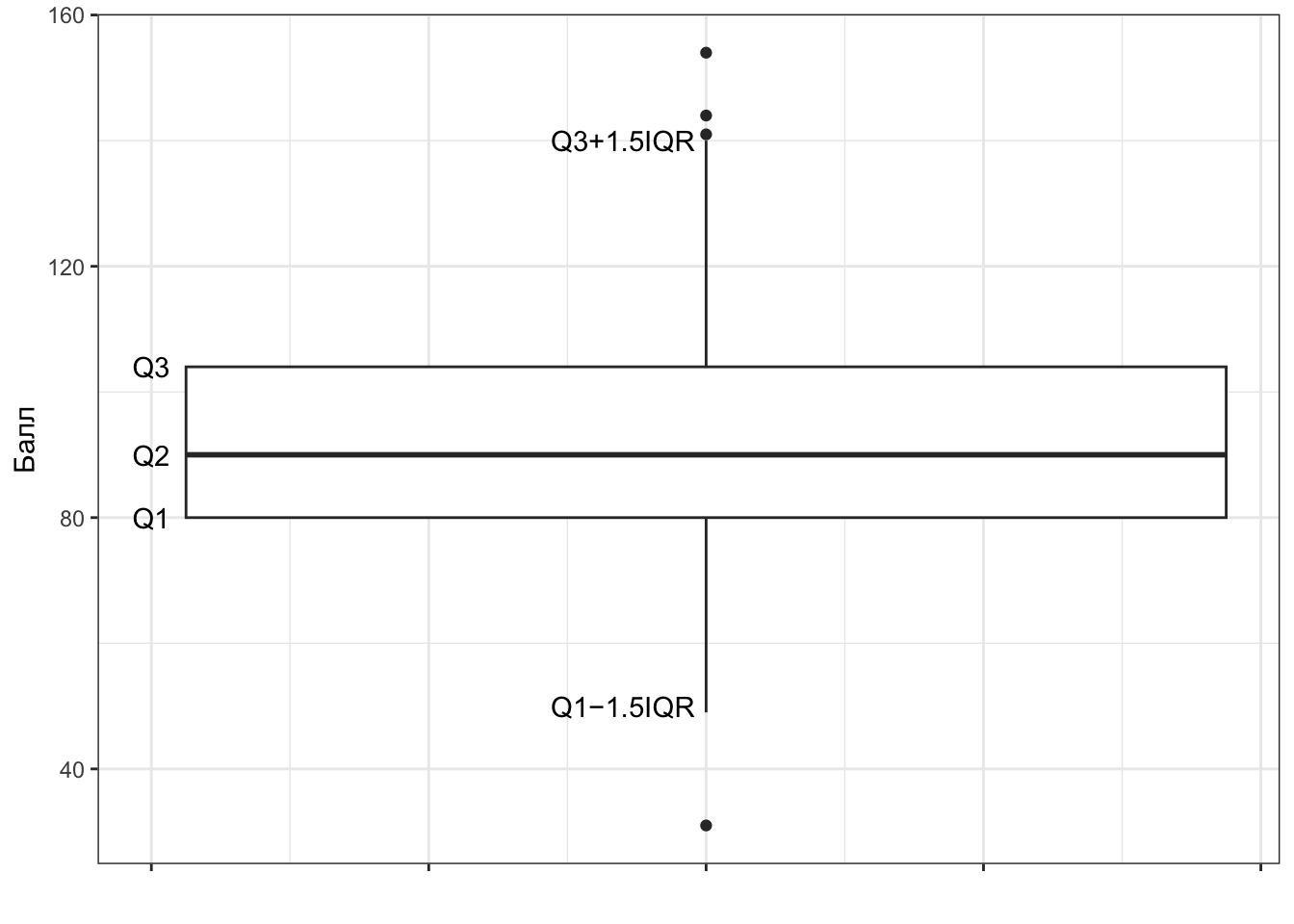
И — о, ура! — мы наконец-то добрались до того, ради чего тут собрались! Зная первый и третий квартили распределения, можно рассчитать интерквартильный (межквартильный) размах (interquartile range, IQR) как разницу между третьим и первым квартилями.
\[ \text{IQR}(X) = \text{Q3}(X) - \text{Q1}(X) \]
Эта величина описывает интервал значений признака, в котором лежит 50% наблюдений. В случае с баллами по шкале толерантности к неопределенности он равен 24, то есть 50% срединных наблюдений лежит в пределах 24 единиц шкалы.
4.5.1 Визуализация квартилей. Боксплот
Отображать квартили на гистограмме, во-первых, совершенно неудобно, а во-вторых, не то чтобы график получается информативный. Для визуализации квартилей придумали специальный тип графика — ящик с усами, или боксплот (boxplot).
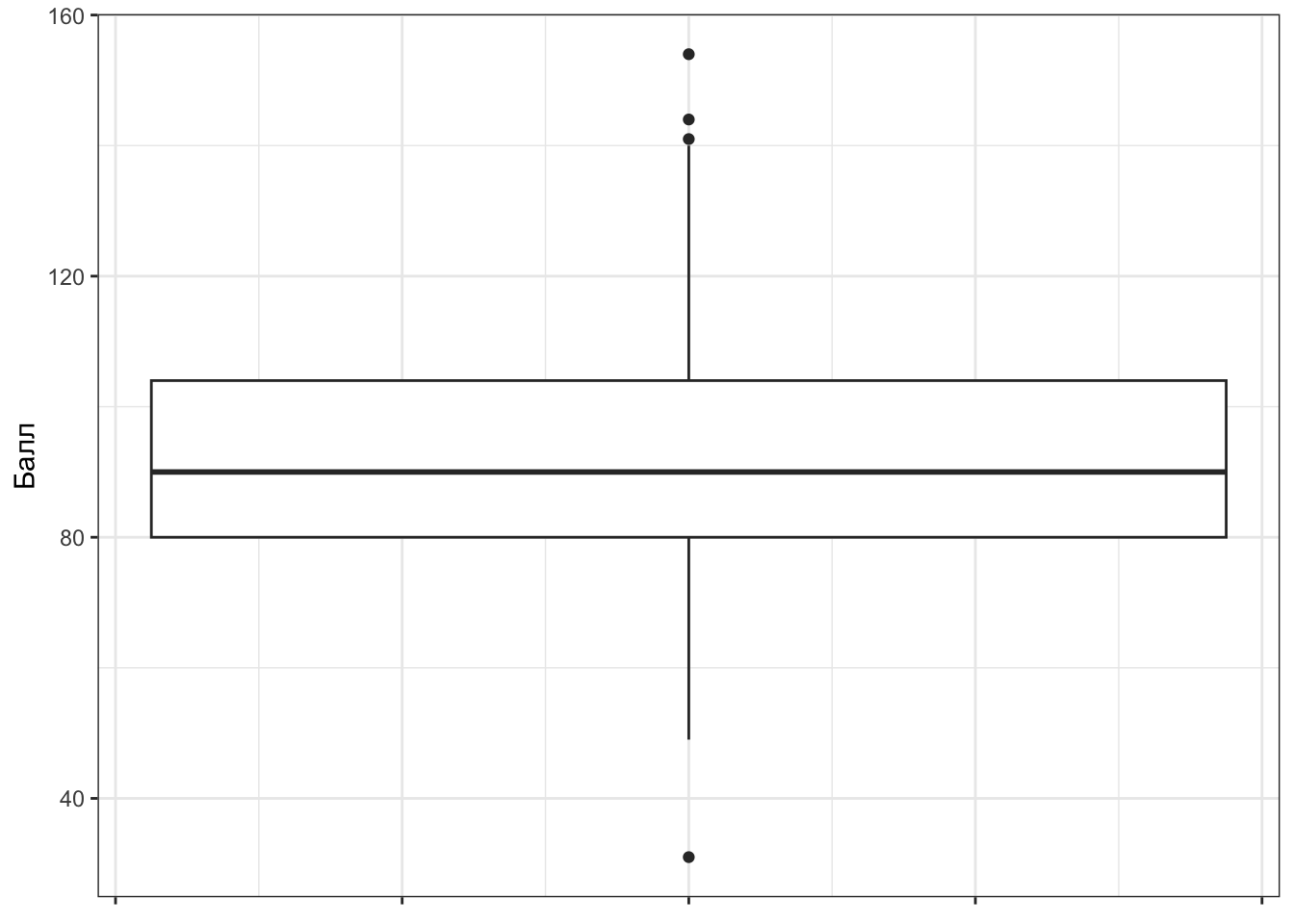
Прикольная ерунда. Научимся его читать.
- Значения переменной идут по вертикальной оси (оси ординат)1
- По горизонтальной оси (оси абсцисс) здесь ничего не идёт2
- Жирная линия посередине ящика — медиана (второй квартиль)
- Нижняя граница ящика — первый квартиль, верхняя — третий
- Границы ящика показывают нам межквартильный размах
- Нижний ус — первый квартиль минус полтора межквартильных размаха
- Верхний ус — третий квартиль плюс полтора межквартильных размаха
Кривой ящик
Ящик может быть асимметричным — то есть верхняя его часть (расстояние между медианой и третьим квартилем) и нижняя его часть (расстояние между медианой и первым квартилем) могут быть разными. Это нам говорит об асимметричности распределения. Усы также могут быть неравными, если один из них упирается в максимум / минимум — тоже по причине асимметричности распределения.
Ну, допустим. А что тогда точки?
4.5.2 Выбросы
Вообще справедливо было бы задаться вопросом, а зачем нам вообще усы на этом графике? И почему мы прибавляем полтора межквартильных размаха?
Это один из подходов к определению нехарактерных значений — выбросов (outliers). При исследовании данных мы часто задаемся вопросом, есть ли в наших данных такие значения, которые сильно отличаются от распределения той или иной переменной. Но как определить это самое «сильно»?
Вот один из подходов. Будем считать, что значения, которые укладываются в интервал \((\text{Q1} - 1.5 \times \text{IQR}, \text{Q3} + 1.5 \times \text{IQR})\), нас устраивают. Всё что попадает в этот интервал — это «нормальные», типичные значения нашей переменной. Те же, которые будут находиться за пределами этого интервала, мы назовём нетипичными, аномальными значениями, или выбросами. Эти значения и будут отмечены точками на графике.
Что делать с выбросами?
Во-первых, содержательно анализировать. Выбросы могут возникнуть по разным причинам. Может быть испытуемый отвлекся на прилетевшего в окно голубя, и у нас в данных появилось время реакции 200 секунд. Такие выбросы мы можем исключить из данных.
А возможно в нашу выборку попали какие-то люди, которые, скажем, очень сильно или очень слабо толерантны к неопределенности. Эти наблюдения не являются «ошибками», и их необходимо дополнительно проанализировать — возможно, это представители каких-либо специфических групп нашей генеральной совокупности. Анализ принесет нам дополнительную информацию, которую мы могли не учесть при планировании исследования. Крч, думать надо. И собирать побольше данных, чтобы можно было найти содержательную интерпретацию происходящему.
4.6 Дисперсия
Хотя описание разброса переменных с помощью квантилей (в частности, квартилей) может дать нам много полезной информации, все же у них есть существенный недостаток: они никак не взаимодействуют с самими значениями нашей переменной.
Действительно, мы делим нашу отсортированную выборку на равные части, и смотрим, что в эти части попало. Но хотелось бы как-то учесть ещё и сами значения переменной в некоторой числовой мере разброса.
Ну, хорошо. Поступим следующим образом. Мы все ещё хотим узнать, как наши значения группируются вокруг среднего. В предыдущей главе мы уже видели, что наши наблюдения отклоняются от среднего значения — значит мы можем посчитать отклонение для каждого наблюдения (\(d\) — от лат. вумшфешщт или англ. deviation):
\[ d_i = \overline X - x_i \]
Окей. Если мы сложим все отклонения и поделим получившуюся сумму на их количество, равное количеству наблюдений (\(n\)), то получим среднее отклонение, да?
В принципе, да:
\[ \overline d = \frac{1}{n} \sum_{i=1}^n d_i = \frac{1}{n} \sum_{i=1}^n (\overline X - x_i) \]
Однако есть одна проблема. В прошлой главе мы выяснили, что сумма отклонений от среднего равна нулю (Утверждение 3.3), а значит и cреднее отклонение также будет равно нулю.
Хорошо. Но отрицательные значения ведь можно победить! Есть два пути:
- Модуль. Преимущество первого в том, что размерность величины разброса остается той же, что и у измеряемой переменной.
- Квадрат. Преимущество второго в том, что квадрат обладает более хорошими аналитическими свойствами, чем модуль, а ещё сильные отклонения будут оказывать более сильное влияние на окончательное значение статистики (см. заметку 4.1).
Второй путь на практике оказывается полезнее, так как мы хотим, чтобы сильно отличающиеся наблюдения вносили больший вклад в меру разброса.
Возведя отклонения в квадрат, получим формулу дисперсии (вариации, variation):
\[ D(X) = \text{var}(X) = \sigma^2_X = \frac{1}{n} \sum_{i=1}^n d_i^2 = \frac{1}{n} \sum_{i=1}^n (\overline X - x_i)^2 \tag{4.1}\]
Гениально.
Note 4.1: Почему квадрат лучше модуля?
Рассмотрим два простейших примера. Пусть у нас есть два нехитрых ряда наблюдений:
[1] 1 2 3 4 5 6[1] 1 2 3 4 5 20Как несложно заметить, они отличаются друг от друга всего лишь одним наблюдением — в первом случае существенных отклонений нет, а во втором есть одно наблюдений, значительно отклоняющееся от всех остальных.
Попробуем посчитать разброс, используя модуль — формула будет такова:
\[ \text{MAD} = \frac{1}{n} \sum_{i=1}^n |d| = \frac{1}{n} \sum_{i=1}^n |\overline X - x_i| \]
Эта статистика называется среднее абсолютное отклонение (mean absolute deviation, MAD).
Для первого ряда наблюдений получим 1.5, для второго — 4.72.
Значения разброса, безусловно, различаются, однако не то чтобы очень значительно.
Теперь воспользуется формулой дисперсии:
\[ \text{var}(X) = \frac{1}{n} \sum_{i=1}^n d^2 = \frac{1}{n} \sum_{i=1}^n (\overline X - x_i)^2 \]
Для первого ряда наблюдений получим 2.92, для второго — 41.81.
В этой случае значения различаются уже гораздо сильнее — на целый порядок.
Отметим, что и в случае отклонений в меньшую от среднего сторону формулы не перестают работать. Возьмём такие ряды наблюдений:
[1] 15 16 17 18 19 20[1] 5 16 17 18 19 20Расчёты мер разброса для них представлены ниже.
| MAD (модуль) | Дисперсия (квадрат) | |
|---|---|---|
| Первый ряд | 1.5 | 2.92 |
| Второй ряд | 3.61 | 25.14 |
Но не совсем. Формула, которую мы получили, пригодна для расчета дисперсии генеральной совокупности — на выборке же она будет давать неточную оценку.
Чтобы получить точную (несмещенную) оценку дисперсии по выборке, нам нужно исправить знаменатель дроби — вместо \(n\) использовать \(n - 1\):
\[ s^2_X = \hat \sigma^2_X = \frac{1}{n-1} \sum_{i=1}^n d^2 = \frac{1}{n-1} \sum_{i=1}^n (\overline X - x_i)^2 \tag{4.2}\]
Но почему?
Обозначения параметров и их выборочных оценок
Обратим внимание на используемые обозначения.
- Для обозначения параметров генеральной совокупности используются греческие буквы, поэтому дисперсия генеральной совокупности обозначена как \(\sigma^2\).
- Для обозначения оценок параметров, полученных на выборке используются соответствующие греческим латинские буквы, поэтому выборочная дисперсия обозначена как \(s^2\).
Также для обозначения выборочных оценок может быть использована «шляпка», которая надевается на обозначение параметра — в случае дисперсии это выглядит как \(\hat \sigma^2\).
4.6.1 Свойства выборочных оценок
Во всём виновата выборка. В первой главе мы говорили, что в ходе исследования мы собираем выборку, чтобы по результатам её изучения сделать вывод о генеральной совокупности (см. Рисунок 1.1). Иначе говоря, мы заинтересованы в получение максимально точных выборочных оценок параметров генеральной совокупности.
Однако ввиду неопределенности и вариативности данных мы неизбежно будем ошибаться, то есть значение любой выборочной оценки будет отличаться от значения параметра генеральной совокупности. Что же делать?
Необходимо предъявить определённые требования к оценке параметра, для того чтобы она считалась «хорошей», «правильной», «корректной». Таких требований всего существует три — несмещённость, состоятельность и эффективность — из которых мы познакомимся только с первым, так как оно имеет непосредственное отношение к оценке дисперсии.
Несмещённость выражает следующую идею:
пусть мы будем ошибаться в оценке параметра на отдельной выборке,
однако мы не должны ошибаться в среднем, постоянно используя один и тот же способ оценки.
Иначе говоря, да, мы ошибёмся на конкретной выборке, но если выборок будет много, то, усреднив оценки по всем выборкам, мы будем попадать ровно в значение параметра генеральной совокупности.
Под эту идею существует математические обоснование, которое мы не будем рассматривать — лучше поглядим на картинки. Начнём с чего-то хорошо нам знакомого — например, среднего. Ведь у среднего была только одна формула, как мы помним. Почему?
Сделаем симуляцию. Пусть известно, что среднее некоторой переменной в генеральной совокупности равно \(10\), а дисперсия — \(25\). Для определенности можете считать, допустим, что это время реакции на некоторым тип стимулов, хотя это не важно — излагаемая логика будет работать для любых переменных.
Извлечём из этой генеральной совокупности 1000 выборок по 50 наблюдений. На каждой из выборок мы посчитаем среднее и получим что-то такое:
[1] 10.172018 10.732041 8.730498 10.194034 9.957397 11.247254 10.010271
[8] 9.627500 9.671977 11.386532 10.134469 9.442532 9.185977 9.317582
[15] 11.061941 9.996794 9.968616 10.967281 10.501165 9.306908 10.856482
[22] 10.342924 9.923969 9.884275 9.378945 10.595663 9.176307 10.221581
[29] 9.845554 11.084339 11.081289 9.273581 11.066268 9.824072 9.932142
[36] 10.378406 9.720336 10.931505 10.204910 10.523979 10.026035 8.789679
[43] 9.092949 9.578313 10.009071 8.952169 9.915419 10.814884 8.891549
[50] 10.727858 9.983400 11.077476 9.836667 9.013348 9.554866 10.293186
[57] 9.965728 10.509745 9.465434 11.490972 9.557135 9.903944 8.850641
[64] 9.606149 10.591157 9.796804 10.559390 9.952048 9.636643 10.415579
[71] 9.865853 10.813721 9.592410 10.231220 9.197716 8.303104 10.712915
[78] 10.012025 11.149892 10.335617 9.631661 9.538324 9.846021 9.732227
[85] 9.298658 10.578616 9.415370 10.171959 10.417826 9.027612 11.310096
[92] 9.307295 10.651196 9.946036 9.604827 9.725039 9.605681 9.861112
[99] 9.588404 9.525222Здесь представлено только 100 первых значений выборочных средних, так как выводить все довольно громоздко. Наблюдаем, что от выборки к выборки среднее меняется, но все они плюс-минус находятся около 10 — значения параметра генеральной совокупности.
Мы можем усреднить полученные значения, то есть посчитать среднее средних. Отобразим его на распределении выборочных средних, добавив на график значение параметра генеральной совокупности:
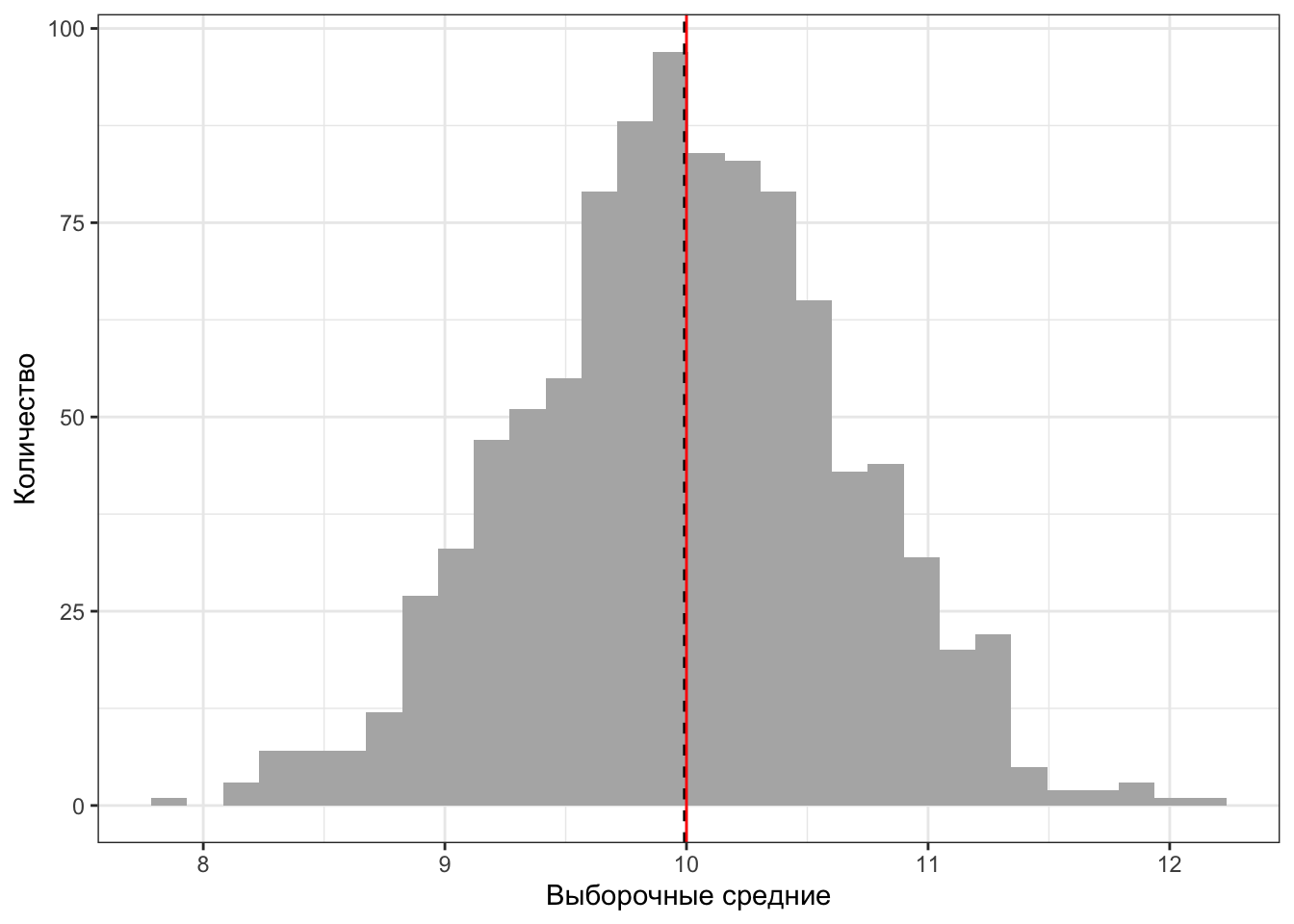
На рисунке красная сплошная линия — значение параметра генеральной совокупности, черная пунктирная — среднее выборочных средних. Видно, что линии [практически] совпадают. Значит, при использовании среднего арифметического в качестве выборочной оценки генерального среднего мы в среднем не ошибаемся. Это и есть несмещённость.
Теперь рассмотрим ситуацию с дисперсией. Итак, у нас есть два способа оценки дисперсии по выборке — Уравнение 4.1 и Уравнение 4.2. Возьмём те же 1000 выборок по 50 наблюдений и посчитаем для каждой выборке её дисперси двумя способами — по формуле выборочной дисперсии и по формуле дисперсии генеральной совокупности. Получим такие значения:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 21.43088 20.49587 24.46954 21.66786 22.43881 22.28620 26.59727 27.83184
[2,] 21.00226 20.08595 23.98015 21.23450 21.99003 21.84047 26.06533 27.27521
[,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16]
[1,] 26.37401 21.56579 20.00768 24.25818 26.16181 27.23231 28.71230 22.23534
[2,] 25.84653 21.13447 19.60752 23.77301 25.63857 26.68766 28.13805 21.79063
[,17] [,18] [,19] [,20] [,21] [,22] [,23] [,24]
[1,] 26.46129 28.90916 26.89292 24.96440 32.85149 21.96123 26.79094 23.48350
[2,] 25.93206 28.33098 26.35506 24.46511 32.19446 21.52201 26.25512 23.01383
[,25] [,26] [,27] [,28] [,29] [,30] [,31] [,32]
[1,] 25.25271 17.49122 27.39924 23.96021 23.82035 24.51674 16.59327 21.68536
[2,] 24.74766 17.14140 26.85126 23.48100 23.34395 24.02641 16.26140 21.25166
[,33] [,34] [,35] [,36] [,37] [,38] [,39] [,40]
[1,] 32.32796 27.61211 31.96177 20.94532 22.33992 31.91699 34.97936 24.66116
[2,] 31.68140 27.05986 31.32254 20.52641 21.89312 31.27865 34.27977 24.16794
[,41] [,42] [,43] [,44] [,45] [,46] [,47] [,48]
[1,] 20.07405 18.86281 18.75675 19.10307 23.59617 18.90775 21.90138 29.39349
[2,] 19.67257 18.48555 18.38161 18.72101 23.12425 18.52960 21.46335 28.80562
[,49] [,50] [,51] [,52] [,53] [,54] [,55] [,56]
[1,] 26.02598 22.21602 26.12363 21.29367 28.51742 25.34852 23.22511 21.56059
[2,] 25.50546 21.77170 25.60115 20.86779 27.94707 24.84155 22.76061 21.12938
[,57] [,58] [,59] [,60] [,61] [,62] [,63] [,64]
[1,] 28.56293 23.55512 24.66227 34.95235 28.57192 30.27220 16.84703 21.14235
[2,] 27.99167 23.08402 24.16903 34.25331 28.00048 29.66675 16.51009 20.71950
[,65] [,66] [,67] [,68] [,69] [,70] [,71] [,72]
[1,] 29.56573 28.62074 20.61853 15.24286 24.56120 30.57612 29.65539 28.62259
[2,] 28.97442 28.04833 20.20616 14.93800 24.06997 29.96459 29.06228 28.05014
[,73] [,74] [,75] [,76] [,77] [,78] [,79] [,80]
[1,] 30.5701 17.0702 16.56888 21.85629 20.59761 21.46445 24.19590 36.10662
[2,] 29.9587 16.7288 16.23751 21.41917 20.18566 21.03516 23.71199 35.38449
[,81] [,82] [,83] [,84] [,85] [,86] [,87] [,88]
[1,] 33.96684 27.40384 16.72593 14.25868 20.21827 31.23118 25.26411 33.85720
[2,] 33.28751 26.85577 16.39141 13.97350 19.81390 30.60655 24.75883 33.18005
[,89] [,90] [,91] [,92] [,93] [,94] [,95] [,96]
[1,] 29.27159 20.44659 24.65205 24.70663 28.30399 18.50158 25.47180 23.12485
[2,] 28.68615 20.03766 24.15901 24.21249 27.73791 18.13155 24.96236 22.66235
[,97] [,98] [,99] [,100]
[1,] 15.32872 29.48873 24.24794 38.14298
[2,] 15.02215 28.89896 23.76298 37.38012Вновь взглянем на первую сотню пар значений: в первой строке расчёты по формуле выборочной дисперсии, во второй — по формуле дисперсии генеральной совокупности. Заметим, что значения в первой строке всегда больше, чем значения во второй. Оно и понятно — так устроены формулы. При этом числа в обеих строках вновь плюс-минус собираются около 25 — значения параметра генеральной совокупности.
Изобразим картину для большей наглядности:
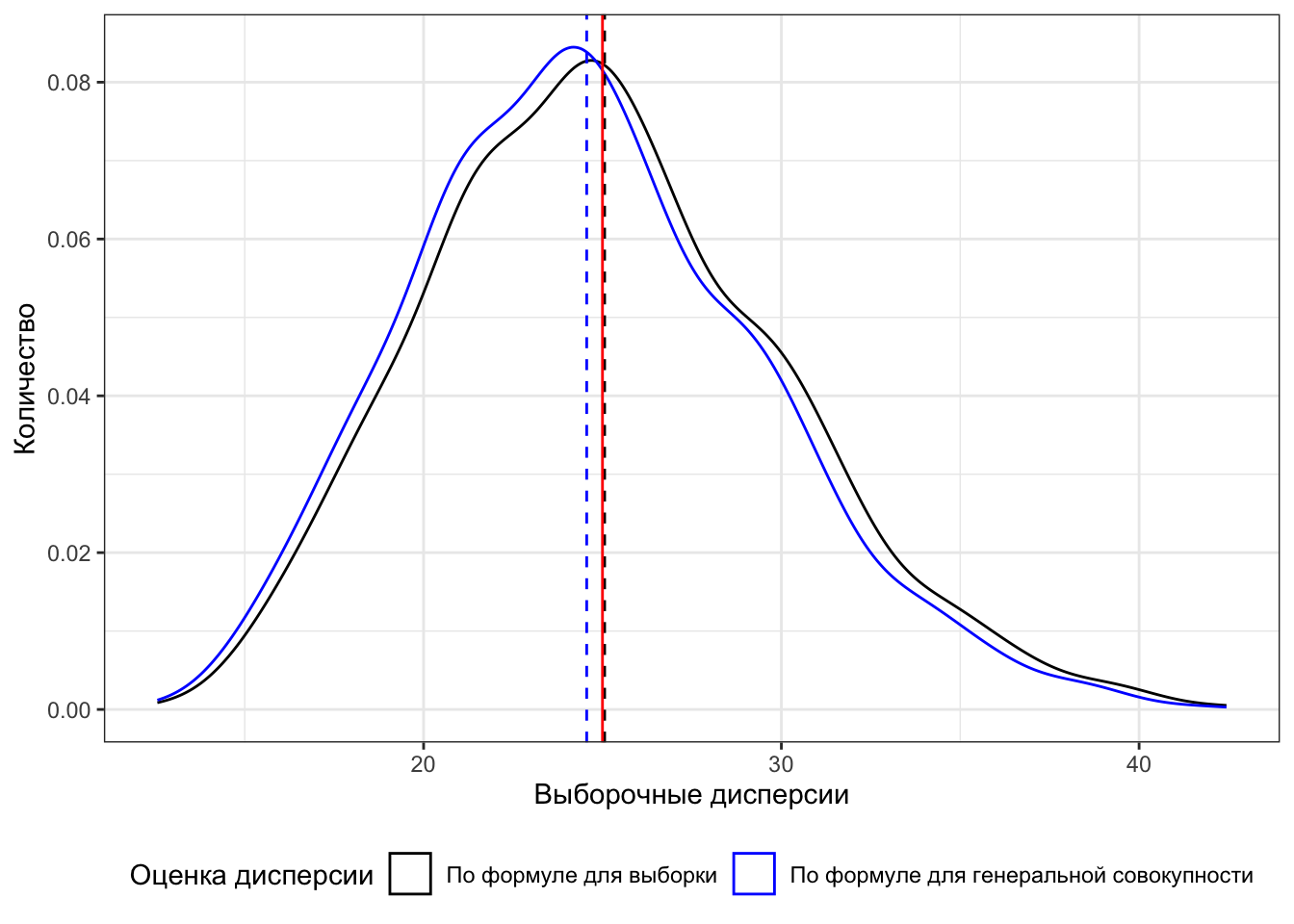
Красной сплошной линией здесь вновь отображен параметр генеральной совокупности. Несложно пронаблюдать, что среднее выборочных дисперсий — чёрная пунктирная линия — [практически] совпадает с красной. Следовательно, формула дисперсии для выборки действительно даёт несмещённую оценку. Теперь обратим внимание на синюю пунктирную линию — среднее оценок дисперсии по формуле для генеральной совокупности. Она не совпадает с красной. Более того, если мы посмотрим на распределение — синяя сплошная линия — то заметим, что оно сдвинуто в сторону относительно чёрного распределения. Это нам говорит о том, что формула для генерального среднего систематически промахивается, что и является выражением смещённости оценки.
Таким образом, при оценке дисперсии по выборке используется Уравнение 4.2, поскольку именно оно даёт несмещённую оценку параметра генеральной совокупности.
4.6.2 Степени свободы
Число \(n-1\) в 4.2 называется количеством степеней свободы. Это довольно мутное понятие, которое при этом непозволительно часто встречается в статистике. Попытаемся к нему хотя бы интуитивно подойти.
Сразу возникает разумный вопрос: почему \(n-1\)? Почему не \(n-2\) или \(n+6\)?
Это число с неизбежностью появляется в расчетах при математическом способе исследования несмещённости оценки дисперсии. Как говорилось выше, в математику мы здесь нырять не будем, однако можно помыслить обоснование следующим образом.
Взглянем на формулу дисперсии: в неё входит среднее арифметическое. То есть для того, чтобы рассчитать дисперсию на выборке, сначала нам необходимо на этой же выборке рассчитать среднее. Мы получаем часть информации о выборке, тем самым как бы «фиксируя» её этим средним значением.
В каком смысле «фиксируя»? Рассчитанное среднее могло получиться многими способами — разные значения наблюдений могли сложиться в одно и то же среднее. До расчета среднего число свободно варьирующихся наблюдений в выборке было \(n\), то есть все имеющиеся значения. Однако когда среднее стало известно, возможность варьирования уменьшилась. Теперь свободно варьирующихся наблюдений стало \(n-1\), так как при известном среднем произвольно могут измениться все наблюдения, кроме одного — всегда можно будет его вычислить, зная выборочное среднее и все предыдущие.
Иначе говоря, теперь одно из наблюдений не является случайным, а значит не участвует в формировании дисперсии выборки. По этой причине оно исключается из расчетов, и в формуле дисперсии появляется \(n-1\).
О степенях свободы можно думать ещё и так: для расчета дисперсии мы посчитали одну статистику — среднее арифметическое, значит из числа наблюдений надо вычесть единицу. В общем-то это то же, что и излагалось выше, только в предельно укороченном варианте.
Впрочем, это не так далеко от истины — позже мы стокнемся со случаями, когда для расчета мер изменчивости необходимо будет рассчитывать две, три и более статистик, и тогда количество степеней свободы будет соответственно \(n-2\), \(n-3\) и \(n-p\).
4.7 Стандартное отклонение
И вот мы получили невероятное! У нас есть формула расчета меры разброса, которая позволяет учесть каждое значение переменной! Ну, не чудо ли!
Чудо, конечно. Однако есть некоторая проблема. Мы возводили отклонения в квадрат. Представим, что мы хотим посчитать дисперсию роста студентов психфака. Пусть мы измеряли рост в метрах. Отклонения тоже будут в метрах, так как среднее — это тоже метры, а если из метров вычитать метры, то мы получим метры. При возведении же метров в квадрат получаются метры в квадрате. Очевидно, что если мы поделим квадратные метры на некоторое число, они все еще останутся метрами в квадрате.
Мы знаем, что в квадратных метрах измеряется, например, площадь, однако едва ли можно говорить о разбросе роста как о площади. Что-то тут нелогичное получается. К тому же, если мы возьмем не рост, а скажем, время реакции, то его дисперсия будет измеряться в квадратных секундах. Это уже вовсе за рамками всевозможных приличий…
А счастье было так близко, так возможно! Неужели мы не сможем интерпретировать эту меру разброса? Не сможем даже нарисовать?
Да, но это не очень большая беда. Для того, чтобы вернуться к исходным единицам измерения нашей переменной, нам всего лишь нужно извлечь корень из дисперсии:
\[ \sigma_X = \sqrt{\sigma^2_X} = \sqrt{\frac{1}{n} \sum_{i=1}^n d^2} = \sqrt{\frac{1}{n} \sum_{i=1}^n (\overline X - x_i)^2} \]
Мы получили величину, называемую стандартным (средним квадратичным3) отклонением (standard deviation).
Чем она хороша? Тем, что её размерность совпадает с размерностью нашей переменной. Стандартное отклонение уже может быть достаточно интерпретабельно и хорошо визуализируемо.
Кстати, формула выше — это стандартное отклонение генеральной совокупности, потому что под корнем стоит дисперсия генеральной совокупности.
Чтобы посчитать стандартное отклонение по выборке, нам надо извлечь корень из выборочной дисперсии:
\[ s_X = \sqrt{s^2_X} = \sqrt{\frac{1}{n-1} \sum_{i=1}^n d^2} = \sqrt{\frac{1}{n-1} \sum_{i=1}^n(\overline X - x_i)^2} \]
4.8 Сравнение мер разброса
Как и разные меры центральной тенденции, разные меры разброса по-своему хороши. Более того, они «дружат» с мерами центральной тенденции. Так, с медианой обычно используется межквартильный размах, а со средним арифметическим — стандартное отклонение.
Размах подходит для всего сразу. Его стоит рассчитать, чтобы составить самое первое представление о разбросе, о границах изменения изучаемого признака [на нашей выборке].
Стоит также отметить, что все, что мы тут обсуждали, совершенно не годится для номинативных переменных. Однако у них тоже есть вариативность. Согласитесь, что выборка из Питера, Москвы, и Казани более вариативна, чем выборка из Москвы. Аналогом меры разброса для номинальной переменной можно назвать количество уникальных значений этой переменной.
4.9 Свойства дисперсии и стандартного отклонения
Мы рассмотрим два свойства дисперсии и два свойства стандартного отклонения, непосредственно следующих из свойств дисперсии.
Утверждение 4.1 Если к каждому значению распределения прибавить некоторое число (константу), то дисперсия распределения не изменится.
\[ D_{X+c} = D_X \]
Доказательство. \[ \begin{split} D_{X+c} &=\frac{1}{n} \sum_{i=1}^n \big( (\overline X + c) - (x_i + c) \big)^2 = \\ &= \frac{1}{n} \sum_{i=1}^n (\overline X + c - x_i - c)^2 = \\ &= \frac{1}{n} \sum_{i=1}^n (\overline X - x_i)^2 = D_X \end{split} \]
Следствие 4.1 Если к каждому значению распределения прибавить некоторое число (константу), то стандартное отклонение не изменится.
\[ \sigma_{X+c} = \sigma_X \]
Доказательство. \[ \sigma_{X+c} = \sqrt{\sigma^2_{X+c}} = \sqrt{D_{X+c}} = \sqrt{D_X} = \sqrt{\sigma^2_X} = \sigma_X \]
Утверждение 4.2 Если каждое значение распределения умножить на некоторое число (константу), то дисперсия изменится в \(c^2\) раз.
\[ D_{X \times c} = D_X \times c^2 \]
Доказательство. \[ \begin{split} D_{X \times c} &=\frac{1}{n} \sum_{i=1}^n \big( (\overline X \times c) - (x_i \times c) \big)^2 = \\ &= \frac{1}{n} \sum_{i=1}^n c^2 \times (\overline X - x_i)^2 = \\ &= c^2 \times \frac{1}{n} \sum_{i=1}^n (\overline X - x_i)^2 = \\ &= c^2 \times D_X \end{split} \]
Следствие 4.2 Если каждое значение распределения умножить на некоторое число (константу), то стандартное отклонение изменится во столько же раз.
\[ \sigma_{X \times c} = \sigma_X \times c \]
Доказательство. \[ \sigma_{X \times c} = \sqrt{\sigma^2_{X \times c}} = \sqrt{D_{X \times c}} = \sqrt{c^2 \times D_X} = c \times \sqrt{D_X} = c \times \sqrt{\sigma^2_X} = c \times \sigma_X \]
Проиллюстрировать свойства дисперсии довольно трудно, поскольку на графиках её отобразить весьма проблематично, однако для стандартного отклонения картинки нарисовать можно. Собственно, мы их уже видели, когда обсуждали свойства среднего арифметического (см. Утверждение 3.1 и Утверждение 3.2).
Для следствия 4.1 визуализация будет такой:
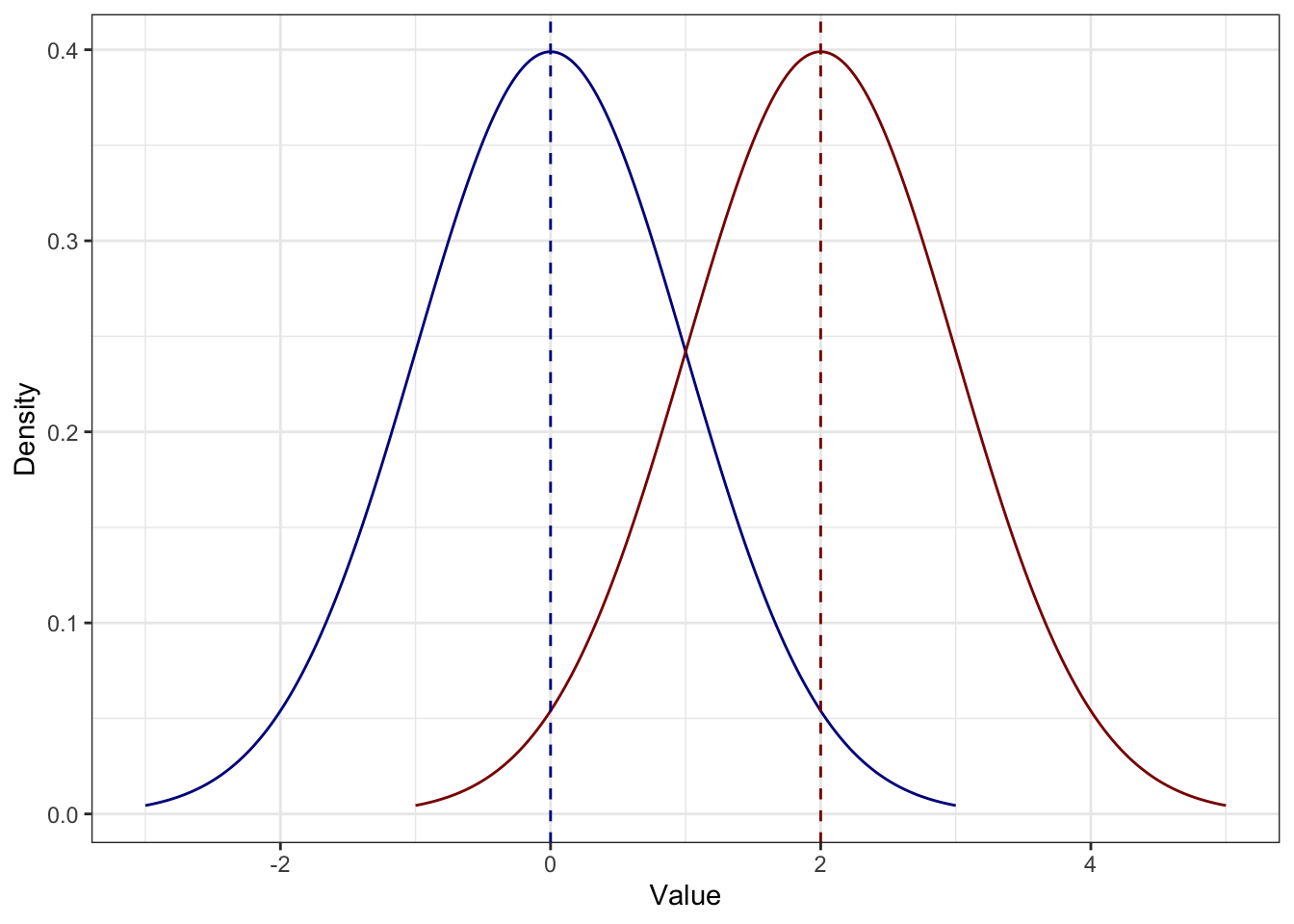
Как мы уже видели, распределение просто сдвигается на константу. Если к каждому значению синего распределения прибавить \(2\), получится красное — разброс у обоих распределений одинаковый.
Для следствия 4.2 визуализация выглядит так:
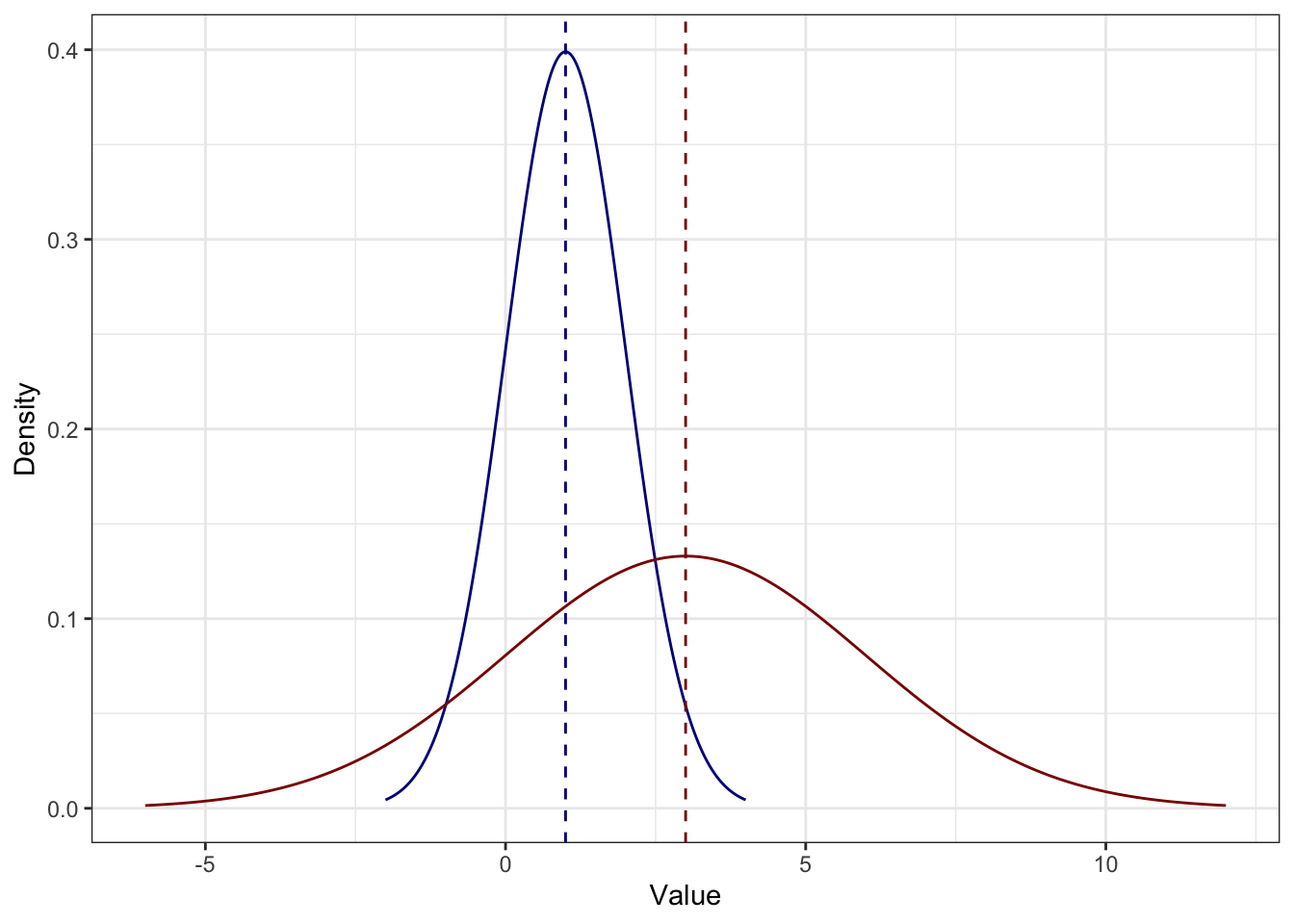
Здесь каждое значение синего распределения умножили на \(3\) и получили красное — разброс также увеличился в три раза, поэтому распределение более плоское.
Обычно это так, хотя не обязательно — иногда боксплоты рисуют горизонтально, если это лучше отображает закономерности.↩︎
Но если мы рисуем несколько боксплотов рядом, то на оси \(x\) будет категориальная переменная.↩︎
Взгляните в предыдущую главу. Как и было обещано, мы увиделись с одним из других средних.↩︎