2 Типы данных
Итак, до какого-то момента мы работали только с числами, а затем начали их сравнивать, и получили что-то новое типа TRUE и FALSE. И как мы отметили, это новый тип данных.
А что такое вообще тип данных? Тип данных — это характеристика данных, которая определяет:
- множество допустимых значений, которые могут принимать данные этого типа,
- и набор операций, которые можно осуществлять с данными этого типа.
Что это значит, будем разбираться на конкретных примерах.
2.1 numeric
Этот тип данных нам уже знаком — это числа. Например, если мы создадим переменную со значением 7 и захотим узнать её тип, то это будет выглядеть так:
## [1] "numeric"Итак, действительно, \(7\) — это число, нас не обманули.
Вообще-то, в R много типов числовых данных: integer (целые числа), double (числа с десятичной дробной частью), complex (комплексные числа). Последние вам вряд ли встретятся в ближайшее время, а по поводу деления первых можно особо не заморачиваться — R сам разберется, что к чему, и переконвертирует как надо.
Однако для интересующихся есть спойлер — все дело в том, как храняться числа на железе. А о комплексных числах в R немного можно почитать тут.
Если мы всё же хотим выяснить, что это за числовые данные, то воспользуется функцией typeof():
## [1] "double"На числовых данных выполняются все математические операции и различные функции, с чем мы развлекались на протяжении предыдущей главы. А множество значений этого типа, как вы понимаете, бесконечно.
2.2 logical
Здесь все гораздо проще. Есть всего два значение TRUE и FALSE, то есть «истина» и «ложь». Получаются логические данные в результате сравнения — и мы это уже тоже видели в предыдущей главе — и на себе сравнение они также допускают.
## [1] TRUE## [1] FALSE## [1] FALSETRUE и FALSE — это логические константы, и, обратите внимание, записываются они прописными буквами. true и True не сработают. Правда есть вариант записывать их только одной буквой T и F, но c’est mauvais ton, и вот почему:
## [1] TRUE## [1] FALSEКонстанты TRUE и FALSE защищены от перезаписи (на то они и константы):

Поэтому мы не будем жалеть времени и символы и в угоду удобочитаемости и стабильности кода будем писать логические константы полностью.
Кроме сравнения, логический тип данных допускается на себе логические операции, что в общем-то логично.
Основных операций две:
- логическое И (конъюнкция,
&, \(\wedge\), \(\cdot \,\)) - логическое ИЛИ (дизъюнкция,
|, \(\vee\), \(+ \,\))
Работают они следующим образом в соответствии с таблицей истинности:
## [1] TRUE## [1] FALSE## [1] FALSE## [1] FALSE## [1] TRUE## [1] TRUE## [1] TRUE## [1] FALSEМожем создать и более сложные конструкции. Например, с участие переменных:
## [1] FALSE## [1] TRUE## [1] FALSEЗаметьте, что ! существует не только в составе !=, но и как самостоятельный логический оператор и обозначает логическое отрицание.
Также есть оператор xor() (который выглядит как функция1), обозначающий исключающее ИЛИ. Это логическая функция от двух переменных и работает вот так:
## [1] FALSE## [1] TRUE## [1] TRUE## [1] FALSEОн используется редко, но может когда-нибудь внезапно пригодиться.

Хотя множество значений логического типа данных действительно состоит из двух элементов TRUE и FALSE, логических констант в R — три штуки. Какая третья?
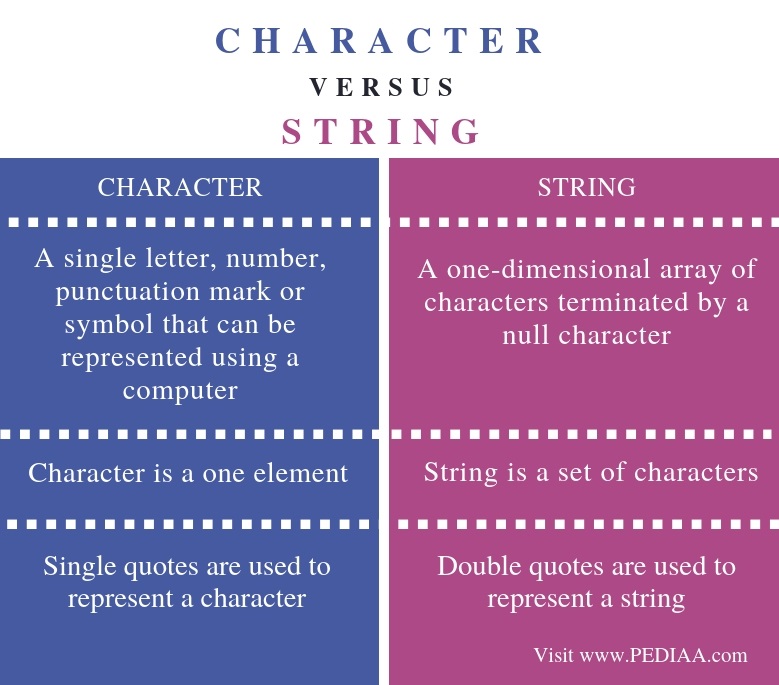
2.3 character
Очевидно, что в практике мы не всегда имеет дело только с цифрами, мы храним ещё и текстовую информацию. Для этого есть тип данных character (хотя другие языки программирования с R бы поспорили).
{kind=link}
## [1] "character"character — это строки (strings) символов, поэтому они должны быть закавычены одинарными (') или двойными (") кавычками. Так R поймёт, где строка начинается и где заканчивается. Большой разницы между одинарными и двойными кавычками нет, но если у вас кавычки внутри кавычек, здесь надо быть аккуратным:
## [1] "Мужчина громко зашёл в комнату и высказал решительное \"здравствуйте\""А вообще, есть беспроигрышный [и типографически верный] вариант:
## [1] "Мужчина громко зашёл в комнату и высказал решительное «здравствуйте»"Строковый тип данных мы еще подробно обсудим в теме работы со строками, а пока посмотрим вот на что…
Конечно, чтобы разговор и типах данных был полным, необходимо сказать о таком типе данных как
factor. Хотя он не является «базовым» типом, Всё же ему необходимо уделить некоторое внимание.
2.4 factor
Фактор — это строковые данные, которые хранятся как числа. Почему там делать удобно? Потому что фактор содержит определённый (как правило, небольшой) набор уникальных значений (чаще всего около 2-5).
Для чего используются факторы? Для задания каких-либо групп в данных. Например, у вас есть экспериментальные данные, в которых есть два экспериментальных условия и одно контрольное. Тогда вектор, задающий эти условия может выглядет примерно так:
conditions <- c('exp1', 'exp2', 'control', 'exp1', 'exp1', 'exp2', 'control', 'exp2', 'control')
conditions## [1] "exp1" "exp2" "control" "exp1" "exp1" "exp2" "control"
## [8] "exp2" "control"Сейчас это строковый вектор — это достаточно просто превратить в фактор:
## [1] exp1 exp2 control exp1 exp1 exp2 control exp2 control
## Levels: control exp1 exp2В аутпуте добавилась строчка Levels, которая как раз и определяет набор уникальных значений. По умолчанию уровни фактора выстраиваются в алфавитном (лексикографическом) порядке. Если вам принципиален порядок факторов — например, в случае эксперимента на зрительный поиск у вас есть несколько visual set size (количество стимулов в пробе) — тогда можно воспользоваться специальной функцией и создать упорядоченный фактор:
vis_set_size <- factor(rep(c(3, 6, 9), times = 10),
levels = c(3, 6, 9), # задаём порядок уровней
ordered = TRUE) # указываем, что нам нужн упорядоченный вектор
vis_set_size## [1] 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9 3 6 9
## Levels: 3 < 6 < 9Теперь в строке Levels указаны не только сами уровни, но и отношение порядка для множестве значений. Как видите, в фактор можно превратить не только текстовый вектор, но и числовой.
В актуальных версиях R обычно текстовые векторы автоматически приводятся к факторам в тех случаях, когда это нужно. Однако если нам нужен числовой вектор как факторный, это придется делать вручную. Хотя, конечно, числовые данные мы чаще всего рассмтариваем именно как числовые.
2.5 Coercion [part one]
А что будет, если мы пренебрежём допустимыми операциями и попробуем, например, сложить не-числа? Допустим, так:
## [1] 2Внезапно, команда выполнилась. Можно задаться вопросом, почему именно так, ведь правила алгебры логики говорят, что должно быть по-другому. Опуская детали, скажем, что оператор + несет только арифметический, но не логический смысл, поэтому произошло следующее:
- оператор
+умеет работать только с числовыми значениями - но получил логические
- поэтому попробовал привести их к числовым
- у него получилось —
TRUEлегко и непринуждено приводится к1, аFALSEк0 - далее выполнилось сложение
Такое поведение называется приведение типов (coercion). Подробно мы его будем обсуждать позже, когда изучим структуры данных и поймем, какие опасности это может за собой влечь. Сейчас же ознакомимся с некоторыми примерами.
Приведение типов сработает не всегда. Например, если мы попытаемся сложить строки2, то получим ошибку:
## Error in "abc" + "cbd": non-numeric argument to binary operatorЧтобы контролировать приведение типов, есть семейство функций as.*(). Посмотрим, как они работают.
## [1] 1## [1] 0## [1] TRUE## [1] FALSE## [1] TRUE## [1] TRUE## [1] TRUE## [1] "23"## [1] "-150"## [1] "TRUE"## [1] "FALSE"Поздравляю! Мы закончили с основами основ! Пора переходить к самому важному и интересному — структурам данных, а именно – векторам!
Так-то любой оператор (арифметический или логический) — это функция от двух переменных. В предудщей главе был пример
`+`(7, 3), а теперь попробуйте выполнить`&`(TRUE, FALSE).↩︎Хотя, например, для JavaScript сложение строк — стандартная процедура.↩︎